独家 | 机器学习解释模型:黑盒VS白盒(附资料链接)

作者:Lars Hulstaert
翻译:吴金笛
校对:Nicola
本文约2000字,建议阅读9分钟。
本文将讨论一些可用于解释机器学习模型的不同技术。
大多数机器学习系统需要能够为利益相关者解释为何做出这样特定的预测。 在选择合适的机器学习模型时,我们通常会在准确性与可解释性之间权衡:
准确与“黑盒”:
诸如神经网络,梯度增强模型或复杂集合之类的黑盒模型通常提供很高的准确性。 这些模型的内部工作难以理解,并且它们不能估计每个特征对模型预测的重要性,也不容易理解不同特征之间如何相互作用。
较弱的“白盒”:
另一方面,诸如线性回归和决策树之类的简单模型具备较弱的预测能力,并且不总能对数据集的固有复杂性建模(即,特征交互)。 但是这些却是很容易被理解和解释的。
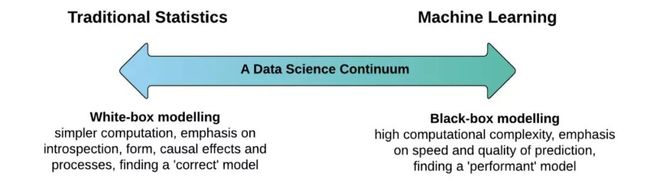
图片来自Applied.AI
准确性与可解释性的权衡取决于一个重要的假设,即“可解释性是模型的固有属性”。
“可解释性是模型的固有属性”
https://www.inference.vc/accuracy-vs-explainability-in-machine-learning-models-nips-workshop-poster-review/
然而,我坚信通过合适的“可解释性技术”,任何机器学习模型都可以更具解释性,尽管对于某些模型而言其复杂性和成本比其他模型更高。
在这篇博文中,我将讨论一些可用于解释机器学习模型的不同技术。 此博客文章的结构和内容主要基于H20.ai机器学习可解释性小册子。 如果您想了解更多信息,我强烈建议阅读这个H20.ai小册子或Patrick Hall撰写的的其他材料!
H20.ai机器学习可解释性小册子
Patrick Hall
http://docs.h2o.ai/driverless-ai/latest-stable/docs/booklets/MLIBooklet.pdf
模型属性
模型的可解释程度通常与响应函数的两个属性相关联。 模型的响应函数f(x)定义模型的输入(特征x)和输出(目标f(x))之间的输入 - 输出关系。 根据机器学习模型,此函数具有以下特征:
线性:在线性响应函数中,特征与目标之间的关联表现为线性。 如果一个特征线性变化,我们也期望目标以相似的速率线性变化。
单调性:在单调响应函数中,特征与目标之间的关系始终在特征上的一个方向(增大或减小)。 更重要的是,这种关系贯穿于整个特征域,并且与其他特征变量无关。
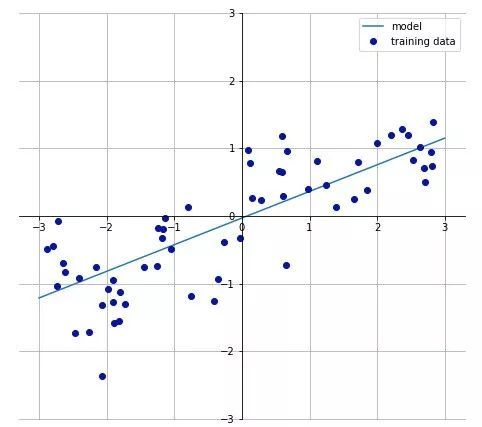
简单线性和单调响应函数的示例(1个输入变量x,1个响应变量y)
线性回归模型是线性单调函数的例子,而随机森林和神经网络是表现出高度非线性和非单调响应函数的模型的例子。
Patrick Hall的以下幻灯片说明了为什么在需要清晰简单的模型解释时,通常首选白盒模型(具有线性和单调函数)。 最上面的图表显示,随着年龄的增长,购买数量会增加。 在全局范围内响应函数具有线性和单调关系,这容易被所有利益相关者理解。
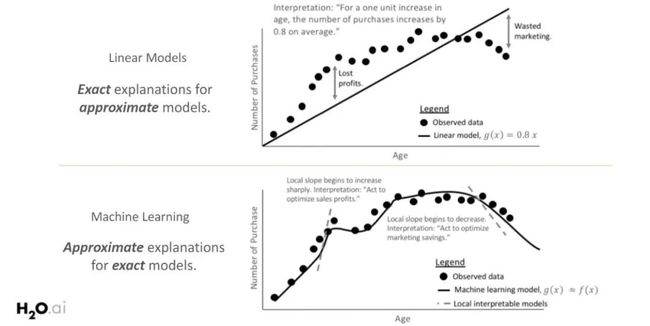
然而,由于白盒模型的线性和单调约束,趋势的一个重要部分被忽略了。 通过探索更复杂的机器学习模型,虽然响应函数在局部范围内仅是线性和单调的,但是可以更好地拟合观测数据。 为了解释模型行为,有必要在局部范围内研究该模型。
在全局范围或局部范围内,模型可解释性的范围本质上与模型的复杂性相关。线性模型在整个特征空间中表现出相同的行为(如上图所示),因此它们是全局可解释的。 输入和输出之间的关系通常受到复杂性和局部解释的限制(即,为什么模型在某个数据点做出了某种预测?),而局部解释默认为全局解释。
对于更复杂的模型,模型的全局行为更难定义,并且需要响应函数的小区域的局部解释。 这些小区域更可能表现出线性和单调,从而实现更准确的解释。
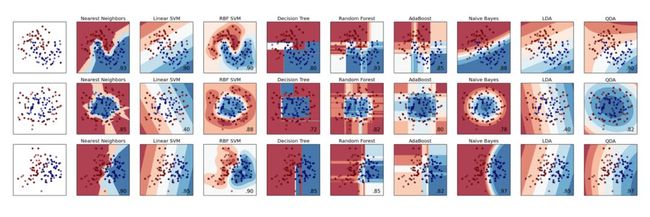
ML库(例如sk-learn)允许在不同分类器之间进行快速比较。 当数据集的大小和维度受限时,可以解释结果。 在大多数现实问题中情况将不再如此。
在本博文的其余部分中,我将重点介绍两种提供全局和局部解释的模型无关(model-agnostic)技术。 这些技术可以应用于任何机器学习算法,并且通过分析机器学习模型的响应函数来实现可解释性。
可解释性技术
1. 代理模型
代理模型是用于解释更复杂模型的模型。 通常使用线性模型和决策树模型,由于它们的简单解读。 创建代理模型以表示复杂模型(响应函数)的决策过程,并且是使用输入和模型预测训练的模型,而不是在输入和目标上训练的模型。
代理模型在非线性和非单调模型之上提供了一个全局可解释性的层,但它们不应该被完全依赖。 代理模型不能完美地表示底层响应函数,也不能捕获复杂的特征关系。 它们主要用作模型的“全局总结”。 以下步骤说明了如何为任一黑盒模型构建代理模型:
训练黑盒模型。
在数据集上评估黑盒模型。
选择一个可解释的代理模型(通常是线性模型或决策树)。
在数据集上训练可解释模型和其预测。
确定代理模型的错误度量并解释代理模型。
2. LIME
LIME背后的一般思想与代理模型相同。 然而,LIME并不构建代表整个数据集的全局代理模型,而只构建在局部区域内解释预测的局部代理模型(线性模型)。 有关LIME的更深入解释,请参阅LIME上的博客文章。
LIME提供了一种直观的方法来解释给定数据点的模型预测。
以下步骤说明了如何为任一黑盒模型构建LIME模型:
训练黑盒模型。
局部感兴趣区域的样本点。样本点可以从数据集中检索,或生成人工点。
通过接近感兴趣区域对新样本进行加权。在有差异的数据集上拟合加权的,可解释的(代理)模型。
解释局部代理模型。
结论
你可以使用这里的几种不同技术来提高你的机器学习模型的可解释性。尽管随着该领域的进步,这些技术越来越强大,但是一直比较不同的技术是很重要的。我没有讨论的一个技术是Shapley值。要了解更多有关该技术的知识请看Christoph Molnar的书《可解释的机器学习》(Interpretable Machine Learning)。
Interpretable Machine Learning
Christoph Molnar
https://christophm.github.io/interpretable-ml-book/
原文标题 :
Black-box vs. white-box models
原文链接:
https://towardsdatascience.com/machine-learning-interpretability-techniques-662c723454f3
译者简介

吴金笛,雪城大学计算机科学硕士一年级在读。迎难而上是我最舒服的状态,动心忍性,曾益我所不能。我的目标是做个早睡早起的Cool Girl。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,数据派THU产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~


点击“阅读原文”拥抱组织