查询系统直接面对用户,在接受用户的查询请求后,通过检索,排序及摘要提取等计算,将结果组织成搜索结果返回给用户
特点:快速,准确,全面(效率,效果)
1.1 信息熵
如数据结构的huffMan编码,为不同词频的词频创建不同长度的前缀编码
信息熵在信息论中称为消息X的熵,其含义是信息集X发出任意一个随机事件的平均信息量
通过熵阐明概率和信息的关系.变量的不确定性越大,熵也就越大,将其搞清楚所需要的信息量也就越大
1.2 检索和查询的区别
查询的结果是搜索结果网页;而检索结果是与查询词相关的文档列表
查询相对查询系统而言;检索相对于索引系统而言
1.3 检索词和查询词的区别
用户输入查询词,通过查询系统分词提交给检索代理"检索分词"
1.4 自动文本摘要
从文档中自动提取一个正文片段
2 网页信息检索
检索数据来源于网页索引库(网页对象被索引入库的全过程),网页信息检索输出是一组文档编号.
2.1 早期检索模型
"布尔模型"(Boolean Models)也称集合模型
采用AND,OR,NOT等逻辑运算符组成的逻辑表达式.通过布尔运算进行检测的简单匹配模型.
易于实现,速度快.但是没有考虑文档和关键词的相关性,没有区分查询词权重问题.放弃了效果(出现次数排序或者优先词问题),仅仅考虑效果
2.2 向量空间模型(Vector Space Models)
向量空间模型 主要关心的是效果而非效率.
提出了将查询词和文档按照关键词唯独分别向量化,然后通过计算这两个向量之间夹角的方法得到文档和关键词的相似度.从而优先检索相似度大的文档,并进行排序
三个步骤
(1) 把原始查询和文档看作文本,使用同样的向量化过程分别得到查询向量和文档向量
(2) 通过计算向量相似度的方法计算原始查询和文档的相似度
(3) 按照相似度从大到小进行排序,返回给用户
将不同的关键词看作不同维度,那么每个文档关键词进行高向量化得到向量中的每个分量可以理解为向量在关键词维度上的投影.
eg

通过每个关键词出现次数比
走进,搜索引擎,学习 = (1/4,2/4,1/4)
对于文档进行同样的处理,那么得到类似一个空间向量
然后计算夹角,夹角越小,说明相似度越高,排名越高,返回给用户的网页显示也就越靠前
因为这样会产生浮点数计算的问题,所以使用词频进行处理
TF/IDF方法进行向量化工作,然后计算文档和查询词相似度的问题.
可以使用哈希表的方法快速找到两个向量相同分量的非0值进行计算
2.3 关键词权重 量化方法 TF/IDF
熵最大限度的压缩冗余信息对于衡量关键词权重具有特殊意义
具体参考自制简单搜索引擎
2.4 搜索引擎采用的检索模型
锁搜引擎采用布尔模型和空间向量空间模型结合的方法进行信息检索,布尔模型高效且易于实现;空间向量模型能提高检索相似度,改善禅寻效果.
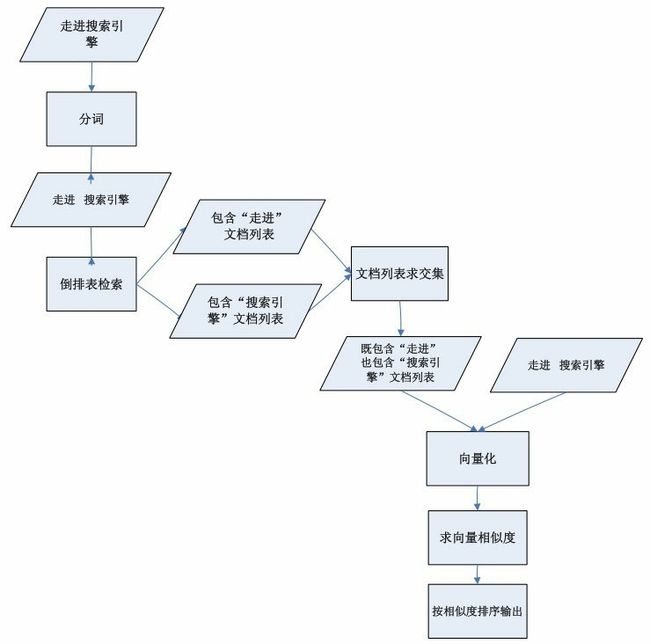
2.5 多文档列表求交计算
三种情况
(1) 查询单个词
(2) 查询多个词: 空格隔离
(3) 查询一个词:由于分词形成多词查询
对23情况进行文档求交.
使用"最佳归并树算法"
基本思路:越短的文档列表越早参与文档列表求交过程...
好处:如果在求最短的两个文档列表的交集时发现为空,那么终止这个过程
缺点:
计算有依赖性,难以并发
需要本地空间临时保存求交结果
最后依次求交必然是1个长列表和一个短列表求交
2.6 检索结果排序
对于返回结果,只需要返回前n项即可.称为"top-n查询"也就是采用堆排序方案处理
堆排序除了内存复制少特点,还具有"就地(inplace)"排序的特点
3 中文自动摘要
3.1 自动摘要的含义和实现
自动摘要是从文档中自动提取一个正文片段.
对于同一个文档,其自动摘要对于不同的查询词是不同的.所以,自动摘要的计算是实时的,并且和查询相关,考虑"效率" 和"效果"
摘要必须包含的4层含义:
(1) 摘要指示性:摘要必须出现查询词,指出文档位置
(2) 摘要描述性:如果多个查询词,摘要最好全部显示查询词,即使不能,也应当给出权重更高的查询词
(3) 摘要简介性:长度控制,不长不短
(4) 摘要完整性:句子完整,且从句子首部开始,不允许断句
投票方式+滑动窗口方法.
滑动窗口实现自动摘要的步骤:
(1) 在文档正文中标记查询词出现的位置
(2)从第一个查询词开始,取出滑动窗口长度的正文片段作为第一个候选窗口,接下来,每次窗口滑动到下一个出现的查询词开始.同样取出窗口长度的正文片段作为候选窗口,直到取完所有候选窗口
(3)每个候选窗口包含的正文片段中,累计候选窗口中出现的全部查询词的权重作为候选窗口的评分,最终评分高的候选窗口作为自动摘要提取的结果输出.
滑动窗口类似SIngle算法.



4 生成搜索结果页
搜索结果页的主体包含与查询相关的网页链接URL和自动摘要

4.1 生成网页搜索结果页
因为索引系统中的使用局部倒排文件的分布式部署,提高并发性,可靠性.而由于这种存储结构,实际的检索也是在索引节点内完成.
每个索引节点增加一个检索模块从而变成一个检索节点.
主要步骤:
(1) 检索请求发送给检索代理,检索代理进行查询词分词
(2) 查询词分词后的结果同时发往各个检索节点
(3) 检索代理重新排序来自各个检索节点的文档,去除top-n作为结果页拼接的候选文档
(4) 通过自动摘要模块从网页库中去除n个文档的摘要信息
(5) 将3,4的结果合并,动态产生搜索结果页
5 搜索结果页的缓存
在查询系统中,搜索结果页的缓存是对搜索"效率"贡献的最大设计
注:缓存保存前人查询结果.查询时,直接从缓存提取.
结论:
(1) 前20%的查询词的查询次数约总查询次数的80%
(2) 查询具有稳定性,查过的查询词很可能在将来还会被查询.
使用LRU缓存技术

6 推测用户查询意图
日志分析及挖掘的技巧对排名进行干预.
6.1 查询分类
导航类
信息类
事物类
导航类可以充分利用瞄信息,关键词位置,标题/正文,PageRank等信息,eg"南京大学"-->"首页匹配"
而信息类和事物类查询效果不理想.egZ50,3/10的查询有效率
6.2 推测信息类,事物类的查询意图
(1) 从查询日志中得到用户这类查询中实际点击的URL,并进行排名反馈
(2) 在用户的查询序列中分析查询意图,并给出搜索结果
所以:信息类,事物类查询大多数通过事后分析及日志挖掘的技巧将分析结果反馈给排名系统,使得后续搜索效果更好
7 查询系统的当前热点和发展方向
搜索结果是搜索引擎的命脉,改善搜索结果的主要途径是查询系统,所以,查询系统是搜索引中最热门的话题
7.1 当前热点
(1) 推测用户查询意图,查询纠错,查询推荐,相关搜索
(2) 能够在领域进行查询.包括垂直搜索和分类搜索
(3) 查询结果的优化(相似结果聚类,垃圾网页和病毒的甄别)
(4) 提供个性化服务