6. 一致性Hash 算法的Java实现
在上一篇博文里面讲到通过一致性hash算法解决余数hash算法的伸缩性差的问题,保证新增缓存服务器时能够有尽量多的请求命中原来路由到的服务器。但是没有十全十美的办法,好的算法其实现的复杂度必然也会增加,下面研究一下一致性hash算法的Java实现方案。
数据结构的选取
一致性hash算法中最重要的就是那个2^32的hash环,,根据结点名称的hash值将 服务器结点放在hash环上。那么整数环应该取什么数据结构实现能使运行的时间复杂度最低呢?关于时间复杂度,常见的时间复杂度与时间效率的关系有如下的经验规则:
O(1) < O(log2N) < O(n) < O(N * log2N) < O(N2) < O(N3) < 2N < 3N < N!
前面四五个效率还能接受,后面的就基本不能接受了。 关于如何选取数据结构,有如下几种方案。
1. 排序+List
将所有节点名称的hash值放入数组中然后进行排序,将排序后的数据存入List中(这里使用List存储是考虑到扩展性)。之后,待路由的结点,只需要在List中找到第一个Hash值比它大的服务器节点就可以了,比如服务器节点的Hash值是[0,2,4,6,8,10],带路由的结点是7,只需要找到第一个比7大的整数,也就是8,就是我们最终需要路由过去的服务器节点。
如果暂时不考虑前面的排序,那么这种解决方案的时间复杂度:
(1)最好的情况是第一次就找到,时间复杂度为O(1)
(2)最坏的情况是最后一次才找到,时间复杂度为O(N)
平均下来时间复杂度为O(0.5N+0.5),忽略首项系数和常数,时间复杂度为O(N)。
但是如果考虑到之前的排序,我在网上找了张图,提供了各种排序算法的时间复杂度: 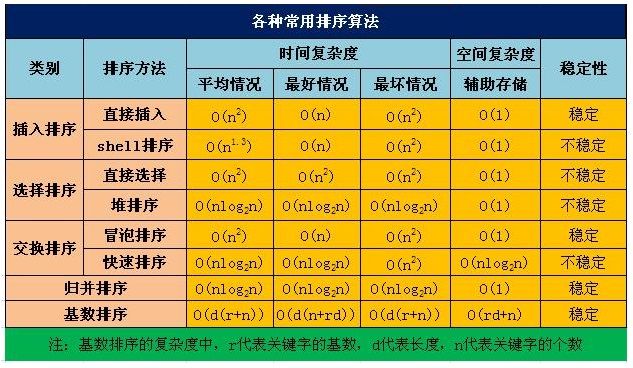
看得出来,排序算法要么稳定但是时间复杂度高、要么时间复杂度低但不稳定,看起来最好的归并排序法的时间复杂度仍然有O(N * logN),稍微耗费性能了一些。
2 遍历 + List
既然排序操作比较耗性能,那么能不能不排序?可以的,所以进一步的,有了第二种解决方案:
解决方案使用List不变,不过可以采用遍历的方式:
(1)服务器节点不排序,其Hash值全部直接放入一个List中
(2)带路由的节点,算出其Hash值,由于指明了”顺时针”,因此遍历List,比待路由的节点Hash值大的算出差值并记录,比待路由节点Hash值小的忽略
(3)算出所有的差值之后,最小的那个,就是最终需要路由过去的节点
在这个算法中,看一下时间复杂度:
1、最好情况是只有一个服务器节点的Hash值大于带路由结点的Hash值,其时间复杂度是O(N)+O(1)=O(N+1),忽略常数项,即O(N)
2、最坏情况是所有服务器节点的Hash值都大于带路由结点的Hash值,其时间复杂度是O(N)+O(N)=O(2N),忽略首项系数,即O(N)
所以,总的时间复杂度就是O(N)。其实算法还能更改进一些:给一个位置变量X,如果新的差值比原差值小,X替换为新的位置,否则X不变。这样遍历就减少了一轮,不过经过改进后的算法时间复杂度仍为O(N)。
总而言之,这个解决方案和解决方案一相比,总体来看,似乎更好了一些。
3 二叉查找树
抛开List这种数据结构,另一种数据结构则是使用二叉查找树。
当然我们不能简单地使用二叉查找树,因为可能出现不平衡的情况。平衡二叉查找树有AVL树、红黑树等,这里使用红黑树,选用红黑树的原因有两点:
1、红黑树主要的作用是用于存储有序的数据,这其实和第一种解决方案的思路又不谋而合了,但是它的效率非常高
2、JDK里面提供了红黑树的代码实现TreeMap和TreeSet
另外,以TreeMap为例,TreeMap本身提供了一个tailMap(K fromKey)方法,支持从红黑树中查找比fromKey大的值的集合,但并不需要遍历整个数据结构。
使用红黑树,可以使得查找的时间复杂度降低为O(logN),比上面两种解决方案,效率大大提升。
Hash值得重计算
对于服务器结点的字符串表示,比如”192.168.0.1:80”,一般来说多个结点的IP地址都是紧挨着的,我做了一个测试,计算相邻的5个结点的IP的字符串表示的hash值,得到结果如下:
public static void main(String[] args) {
System.out.println("192.168.0.0:8011".hashCode());
System.out.println("192.168.0.1:8011".hashCode());
System.out.println("192.168.0.2:8011".hashCode());
System.out.println("192.168.0.3:8011".hashCode());
System.out.println("192.168.0.4:8011".hashCode());
}运行结果如下: 
我们可以看到其hash值非常的接近,这时候问题就大了,[0,232-1]的区间之中,5个HashCode值却只分布在这么小小的一个区间,什么概念?[0,232-1]中有4294967296个数字,而我们的区间只有114516604,从概率学上讲这将导致97%待路由的服务器都被路由到”192.168.0.0”这个集群点上,简直是糟糕透了!负载完全不均衡。所以我们必须重新选择计算hash值的算法。
这里我使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别 。
private static int getHash(String str)
{
final int p = 16777619;
int hash = (int)2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}这时新的计算结果是: 
这时候分布明显均匀很多。
不带虚拟结点的一致性hash算法的实现
代码如下:
package test;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* Created by louyuting on 17/1/6.
*/
public class ConsistentHashingWithoutVirtualNode {
private static String[] servers = {"192.168.0.0:8011","192.168.0.1:8011","192.168.0.2:8011","192.168.0.3:8011","192.168.0.4:8011"};
private static SortedMap sortedMap = new TreeMap<>();
static {
for(int i=0; iint hash = getHash(servers[i]);
System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash);
sortedMap.put(hash, servers[i]);
}
System.out.println();
}
private static int getHash(String str)
{
final int p = 16777619;
int hash = (int)2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
private static String getServer(String node){
//d得到hash值
int hash = getHash(node);
//得到大于该hash的map
SortedMap subMap = sortedMap.tailMap(hash);
//取第一个元素
int i =subMap.firstKey();
return subMap.get(i);
}
public static void main(String[] args) {
String[] nodes = {"127.122.0.0:8011","11.168.22.1:8011","11.22.0.2:8011"};
for (int i=0; i"[" + nodes[i] + "]的hash值为" + getHash(nodes[i]) + ", 被路由到结点[" + getServer(nodes[i]) + "]");
}
}
}
//运行结果
/***
[192.168.0.0:8011]加入集合中, 其Hash值为1818534674
[192.168.0.1:8011]加入集合中, 其Hash值为170444199
[192.168.0.2:8011]加入集合中, 其Hash值为1044402306
[192.168.0.3:8011]加入集合中, 其Hash值为1967926791
[192.168.0.4:8011]加入集合中, 其Hash值为461565183
[127.122.0.0:8011]的hash值为1767943803, 被路由到结点[192.168.0.0:8011]
[11.168.22.1:8011]的hash值为486973912, 被路由到结点[192.168.0.2:8011]
[11.22.0.2:8011]的hash值为768129259, 被路由到结点[192.168.0.2:8011]
*/ 带虚拟结点的一致性hash算法的实现
首先我们考虑两个问题:
1、一个真实结点如何对应成为多个虚拟节点?
2、虚拟节点找到后如何还原为真实结点?
这两个问题其实有很多解决办法,我这里使用了一种简单的办法,给每个真实结点后面根据虚拟节点加上后缀再取Hash值,比如”192.168.0.0:8011”就把它变成”192.168.0.0:8011&&VN0”到”192.168.0.0:8011&&VN4”,VN就是Virtual Node的缩写,还原的时候只需要从头截取字符串到”&&”的位置就可以了。
package test;
import java.util.LinkedList;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* Created by louyuting on 17/1/6.
*/
public class ConsistentHashwithVirNode {
/**
* 待添加入Hash环的服务器列表
*/
private static String[] servers = {"192.168.0.0:8011", "192.168.0.1:8011", "192.168.0.2:8011",
"192.168.0.3:8011", "192.168.0.4:8011"};
/**
* 真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好
*/
private static List realNodes = new LinkedList();
/**
* 虚拟节点,key表示虚拟节点的hash值,value表示虚拟节点的名称
*/
private static SortedMap virtualNodes =
new TreeMap();
/**
* 虚拟节点的数目,这里写死,为了演示需要,一个真实结点对应5个虚拟节点
*/
private static final int VIRTUAL_NODES = 5;
static
{
// 先把原始的服务器添加到真实结点列表中
for (int i = 0; i < servers.length; i++)
realNodes.add(servers[i]);
// 再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高
for (String str : realNodes)
{
for (int i = 0; i < VIRTUAL_NODES; i++)
{
String virtualNodeName = str + "&&VN" + String.valueOf(i);
int hash = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash);
virtualNodes.put(hash, virtualNodeName);
}
}
System.out.println();
}
/**
* 使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
*/
private static int getHash(String str)
{
final int p = 16777619;
int hash = (int)2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
/**
* 得到应当路由到的结点
*/
private static String getServer(String node)
{
// 得到带路由的结点的Hash值
int hash = getHash(node);
// 得到大于该Hash值的所有Map
SortedMap subMap =
virtualNodes.tailMap(hash);
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
// 返回对应的虚拟节点名称,这里字符串稍微截取一下
String virtualNode = subMap.get(i);
return virtualNode.substring(0, virtualNode.indexOf("&&"));
}
public static void main(String[] args)
{
String[] nodes = {"127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333"};
for (int i = 0; i < nodes.length; i++)
System.out.println("[" + nodes[i] + "]的hash值为" +
getHash(nodes[i]) + ", 被路由到结点[" + getServer(nodes[i]) + "]");
}
}
//运行结果:
/**
虚拟节点[192.168.0.0:8011&&VN0]被添加, hash值为637334537
虚拟节点[192.168.0.0:8011&&VN1]被添加, hash值为1942673682
虚拟节点[192.168.0.0:8011&&VN2]被添加, hash值为1111653162
虚拟节点[192.168.0.0:8011&&VN3]被添加, hash值为749027645
虚拟节点[192.168.0.0:8011&&VN4]被添加, hash值为752063515
虚拟节点[192.168.0.1:8011&&VN0]被添加, hash值为653786264
虚拟节点[192.168.0.1:8011&&VN1]被添加, hash值为132412064
虚拟节点[192.168.0.1:8011&&VN2]被添加, hash值为811025279
虚拟节点[192.168.0.1:8011&&VN3]被添加, hash值为326692669
虚拟节点[192.168.0.1:8011&&VN4]被添加, hash值为374169458
虚拟节点[192.168.0.2:8011&&VN0]被添加, hash值为1321894695
虚拟节点[192.168.0.2:8011&&VN1]被添加, hash值为1051614494
虚拟节点[192.168.0.2:8011&&VN2]被添加, hash值为1087571079
虚拟节点[192.168.0.2:8011&&VN3]被添加, hash值为781884308
虚拟节点[192.168.0.2:8011&&VN4]被添加, hash值为1623760690
虚拟节点[192.168.0.3:8011&&VN0]被添加, hash值为367036244
虚拟节点[192.168.0.3:8011&&VN1]被添加, hash值为1370453265
虚拟节点[192.168.0.3:8011&&VN2]被添加, hash值为458430883
虚拟节点[192.168.0.3:8011&&VN3]被添加, hash值为1845319771
虚拟节点[192.168.0.3:8011&&VN4]被添加, hash值为2139636740
虚拟节点[192.168.0.4:8011&&VN0]被添加, hash值为1842286794
虚拟节点[192.168.0.4:8011&&VN1]被添加, hash值为460849631
虚拟节点[192.168.0.4:8011&&VN2]被添加, hash值为2130990870
虚拟节点[192.168.0.4:8011&&VN3]被添加, hash值为573019492
虚拟节点[192.168.0.4:8011&&VN4]被添加, hash值为1063403512
[127.0.0.1:1111]的hash值为380278925, 被路由到结点[192.168.0.3:8011]
[221.226.0.1:2222]的hash值为1493545632, 被路由到结点[192.168.0.2:8011]
[10.211.0.1:3333]的hash值为1393836017, 被路由到结点[192.168.0.2:8011]
*/ 从代码运行结果看,每个点路由到的服务器都是Hash值顺时针离它最近的那个服务器节点,没有任何问题。
通过采取虚拟节点的方法,一个真实结点不再固定在Hash换上的某个点,而是大量地分布在整个Hash环上,这样即使上线、下线服务器,也不会造成整体的负载不均衡。