应用于SVM文本分类的UD-SVR参数寻优算法
应用于SVM文本分类的UD-SVR参数寻优算法
1、 前言
如果对SVM不那么了解可以看看这篇博客中的内容:http://blog.csdn.net/techq/article/details/6171688有了这个基础后我们再来说说下面的内容。
本文主要参考一篇论文所提到的UD-SVR的参数寻优方法来做的,只是原文中提到的方法是应用于SVR的,本人由于实际应用要应用于文本分类中,而且实际数据是通过真实文本量化来的,所以需要做一些相应的调整,描述格式就直接借鉴了原论文的描述方式来对这个方法做一个总结和说明。至于量化方法就是通过上一篇博文提到的改进的TF-IDF方法加上一些根据实际情况作出的预处理完成的。
大家都知道,支持向量机(support vector machine,SVM)是基于统计学习理论的通用机器学习方法,由Vapnik首先提出,包括分类(support vectorclassification,SVC)和回归(support vector regression,SVR),较好地解决了小样本、非线性、过拟合、维数灾和局部最小等问题,泛化推广能力优异,现已广泛引用于文本识别、时间序列预测、定量构效关系等领域,但都是基于小数据集。
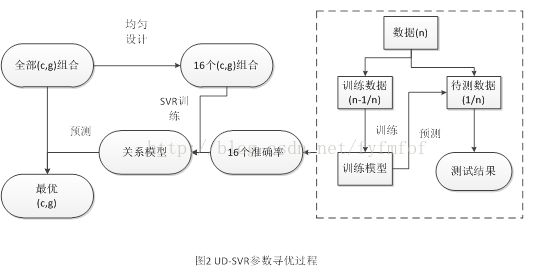
SVM模型的确定主要在于核函数与其参数的选择。而SVM不适用于大样本数据集的主要原因就在于参数选择方面花费的时间过多。解决这个问题的关键是加快寻优速度或缩小参数寻优范围。针对大数据集分类问题使用了一种快速有效寻找最优模型参数的方法UD-SVR。首先基于均匀设计从256个参数组合中抽取16个具有代表性的组合,再通过自调用支持向量回归建立各组合与其准确率之间的关系模型,并以此模型对参数全组合进行快速检测,以找出最优参数组合。
2、 UD-SVR算法介绍
2.1传统 SVM 参数寻优原理
传统SVM参数分类问题寻优需对(c,g:依次表示惩罚系数、核函数参数)组合在给定范围(两个参数范围一般为:log2c=-1:1:14,log2g=-8:-1:-23,补充:如果应用于一般情况的话g值没必要取到这么小,因为我要用在文本分类方面,文本分类量化后向量比较稀疏,所以g的最优参数一般偏小,这个大家可以根据实际情况自己把握这个范围)内进行穷尽搜索,搜索次数为两个参数向量长度的乘积,总的搜索时间为搜索次数x训练样本个数。对于小样本数据穷尽搜索算法运行时间尚能接受,但随着样本数目的增大,所需的计算时间会呈几何级数增加,致使SVM无法有效适用于大数据集。其详细过程如图1。

2.2 UD-SVR寻优原理
此算法以基于均匀设计的自调用SVR代替传统参数寻优过程,从两个方面对传统SVM寻优方法进行了优化:
1) 基于均匀设计仅从全部256组参数组合中选取16组具有代表性的组合,有效降低搜索范围,大幅度缩短了寻优时间;
2) 基于此16个参数组合及其评价指标(准确率)以自调用SVR建立评价指标与参数组合之间的关系模型,并以此对全部参数组合进行预测,以预测的评价指标代替传统SVM寻优方法中的交叉测试评价指标,有效提升了寻优效率。
3) (补充)关于均匀设计这种方法,我找了一些资料,只搞清楚了这种方法的作用和使用,所以在这里我就不做多的介绍了,大家有兴趣了解的自行google吧,我在使用时是查阅均匀设计表然后对应到参数中来的,其实我并不太清楚均匀设计表的产生方法,这个以后有时间再来好好看看。
UD-SVR参数寻优过程见图2其算法具体过程见下部分。至于实现部分由于工程和测试训练数据集一起比较大所以我就一起放在GitHub上了,地址在文章最后,有兴趣的朋友可以下来看看。
这里附上博主在应用中通过均匀设计选择出的16组c,g值以及交叉验证得到的准确率结果(为了更明显观察准确率都放大了10倍)
| log2c | log2g | 准确率 |
| -1 | -14 | 6.943 |
| 0 | -21 | 2.145 |
| 1 | -11 | 8.659 |
| 2 | -18 | 6.916 |
| 3 | -8 | 6.740 |
| 4 | -15 | 8.927 |
| 5 | -22 | 5.242 |
| 6 | -12 | 8.976 |
| log2c | log2g | 准确率 |
| 7 | -19 | 8.638 |
| 8 | -9 | 7.783 |
| 9 | -16 | 9.099 |
| 10 | -23 | 8.236 |
| 11 | -13 | 8.938 |
| 12 | -20 | 9.071 |
| 13 | -10 | 8.394 |
| 14 | -17 | 8.970 |
3、 实验结果比较
传统寻优算法的寻优结果


UD-SVR寻优算法的寻优结果

PS:12表示2的12次方,-17表示2的-17次方

由以上实验结果对比图可以看出UD-SVR的确能在对准确率影响能接受的范围内很大程度上提升SVM在大量数据情况下的参数寻优速度。
参考文献:面向大数据的SVM参数寻优方法_龚永罡
工程代码地址:https://github.com/F-Guardian/UD-SVR_LibSVM
LibSVM使用参考:http://blog.csdn.net/yangliuy/article/details/8041343
本文固定链接:http://blog.csdn.net/fyfmfof/article/details/44659183转载请注明出处