最近由于业务需要监控一些数据,虽然市面上有很多优秀的爬虫框架,但是我仍然打算从头开始实现一套完整的爬虫框架。
在技术选型上,我没有选择Spring来搭建项目,而是选择了更轻量级的Vert.x。一方面感觉Spring太重了,而Vert.x是一个基于JVM、轻量级、高性能的框架。它基于事件和异步,依托于全异步Java服务器Netty,并扩展了很多其他特性。
github地址:https://github.com/fengzhizi715/NetDiscovery
一. 爬虫框架的功能
爬虫框架包含爬虫引擎(SpiderEngine)和爬虫(Spider)。SpiderEngine可以管理多个Spider。
1.1 Spider
在Spider中,主要包含几个组件:downloader、queue、parser、pipeline以及代理池IP(proxypool),代理池是一个单独的项目,我前段时间写的,在使用爬虫框架时经常需要切换代理IP,所以把它引入进来。
proxypool地址:https://github.com/fengzhizi715/ProxyPool

其余四个组件都是接口,在爬虫框架中内置了一些实现,例如内置了多个下载器(downloader)包括vertx的webclient、http client、okhttp3、selenium实现的下载器。开发者可以根据自身情况来选择使用或者自己开发全新的downloader。
Downloader的download方法会返回一个Maybe
package com.cv4j.netdiscovery.core.downloader;
import com.cv4j.netdiscovery.core.domain.Request;
import com.cv4j.netdiscovery.core.domain.Response;
import io.reactivex.Maybe;
/**
* Created by tony on 2017/12/23.
*/
public interface Downloader {
Maybe download(Request request);
void close();
}
在Spider中,通过Maybe
downloader.download(request)
.observeOn(Schedulers.io())
.map(new Function() {
@Override
public Page apply(Response response) throws Exception {
Page page = new Page();
page.setHtml(new Html(response.getContent()));
page.setRequest(request);
page.setUrl(request.getUrl());
page.setStatusCode(response.getStatusCode());
return page;
}
})
.map(new Function() {
@Override
public Page apply(Page page) throws Exception {
if (parser != null) {
parser.process(page);
}
return page;
}
})
.map(new Function() {
@Override
public Page apply(Page page) throws Exception {
if (Preconditions.isNotBlank(pipelines)) {
pipelines.stream()
.forEach(pipeline -> pipeline.process(page.getResultItems()));
}
return page;
}
})
.subscribe(new Consumer() {
@Override
public void accept(Page page) throws Exception {
log.info(page.getUrl());
if (request.getAfterRequest()!=null) {
request.getAfterRequest().process(page);
}
}
}, new Consumer() {
@Override
public void accept(Throwable throwable) throws Exception {
log.error(throwable.getMessage());
}
});
在这里使用RxJava 2可以让整个爬虫框架看起来更加响应式:)

1.2 SpiderEngine
SpiderEngine可以包含多个Spider,可以通过addSpider()、createSpider()来将爬虫添加到SpiderEngine和创建新的Spider并添加到SpiderEngine。
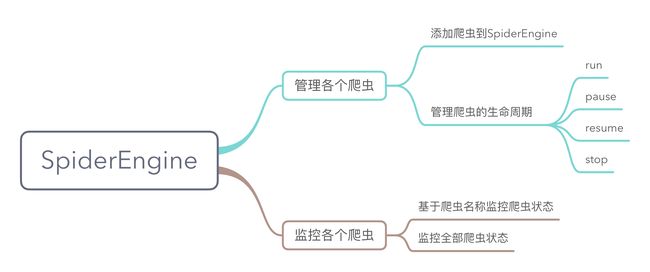
在SpiderEngine中,如果调用了httpd(port)方法,还可以监控SpiderEngine中各个Spider。
1.2.1 获取某个爬虫的状态
http://localhost:{port}/netdiscovery/spider/{spiderName}
类型:GET
1.2.2 获取SpiderEngine中所有爬虫的状态
http://localhost:{port}/netdiscovery/spiders/
类型:GET
1.2.3 修改某个爬虫的状态
http://localhost:{port}/netdiscovery/spider/{spiderName}/status
类型:POST
参数说明:
{
"status":2 //让爬虫暂停
}
| status | 作用 |
|---|---|
| 2 | 让爬虫暂停 |
| 3 | 让爬虫从暂停中恢复 |
| 4 | 让爬虫停止 |
使用框架的例子
创建一个SpiderEngine,然后创建三个Spider,每个爬虫每隔一定的时间去爬取一个页面。
SpiderEngine engine = SpiderEngine.create();
Spider spider = Spider.create()
.name("tony1")
.repeatRequest(10000,"http://www.163.com")
.initialDelay(10000);
engine.addSpider(spider);
Spider spider2 = Spider.create()
.name("tony2")
.repeatRequest(10000,"http://www.baidu.com")
.initialDelay(10000);
engine.addSpider(spider2);
Spider spider3 = Spider.create()
.name("tony3")
.repeatRequest(10000,"http://www.126.com")
.initialDelay(10000);
engine.addSpider(spider3);
engine.httpd(8080);
engine.run();
上述程序运行一段时间之后,在浏览器中输入:http://localhost:8080/netdiscovery/spiders
我们能看到三个爬虫运行的结果。

将json格式化一下
{
"code": 200,
"data": [{
"downloaderType": "VertxDownloader",
"leftRequestSize": 0,
"queueType": "DefaultQueue",
"spiderName": "tony2",
"spiderStatus": 1,
"totalRequestSize": 7
}, {
"downloaderType": "VertxDownloader",
"leftRequestSize": 0,
"queueType": "DefaultQueue",
"spiderName": "tony3",
"spiderStatus": 1,
"totalRequestSize": 7
}, {
"downloaderType": "VertxDownloader",
"leftRequestSize": 0,
"queueType": "DefaultQueue",
"spiderName": "tony1",
"spiderStatus": 1,
"totalRequestSize": 7
}],
"message": "success"
}
案例
最近比较关注区块链,因此做了一个程序来实时抓取三种数字货币的价格,可以通过“询问”公众号的方式来获取最新的价格。

目前该程序已经上线,可以通过询问我的公众号,来实时获取这几种数字货币的最新价格。
TODO
- 增加对登录验证码的识别
- 增加elasticsearch的支持
总结
这个爬虫框架才刚刚起步,我也参考了很多优秀的爬虫框架。未来我会在框架中考虑增加通过截屏图片来分析图片中的数据。甚至会结合cv4j框架。过年前,在爬虫框架中会优先实现对登录验证码的识别。