如何快速高效的训练ResNet,各种奇技淫巧(七):batch norm
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:David Page
编译:ronghuaiyang
导读
这个系列介绍了如何在CIFAR10上高效的训练ResNet,这是第七篇,给大家讲解batch norm的相关内容,以及batch norm是如何影响训练的。
我们研究了batch normalisation如何帮助优化(剧透:它涉及内部协变量漂移……)。在这个过程中,我们遇到了一些糟糕的初始化、退化的网络和尖锐的海塞矩阵。
我学会了不要去担心,并爱上了减少内部的协变量漂移
这个项目最初的想法是通过替换batch norm层来加快高效的ResNet训练实现。事情并没有按照计划进行!——我们有足够的机会进行优化,但是batch norm仍然顽固地存在。为什么?今天,我们将探索batch norm是如何让对快速训练至关重要的高学习率可用的详细机制。让我们从高层视图开始。
深度网络提供了一种方法来表示由可学习的权重参数化的丰富函数的类。训练的工作是选择实现所需功能的参数。在由网络参数化的函数类中,也有许多退化函数,例如那些忽略输入而产生恒定输出的函数。我们将证明这些函数并不是异常现象,而是存在于整个参数空间中——特别是在网络在训练过程中所遵循的轨迹附近。训练过程必须对模型参数进行一定的约束,以避免向退化的函数移动,造成精度的灾难性损失。
SGD等一阶优化器不喜欢约束。垂直于“好”的配置空间方向上的急剧增加的的损失是高曲率和随之产生的训练不稳定性的根源。Batch norm通过对函数空间重新参数化来工作,从而使这些约束更容易实施,减少了损失的曲率,并且可以以较高的速度进行训练。
在我们的研究过程中,我们将详细地填写这张图。我们会学习网络初始化时的一些令人惊讶的行为,并解决关于Hessian频谱峰值的秘密。
让我们来回顾一下什么是batch norm,它的优点是什么,以及鼓励许多人寻找替代方法的缺点。
什么是batch Norm?
Batch norm的作用是减去激活通道的平均值并将其标准化。
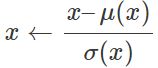
统计值μ(x),σ(x)是在一个batch中对每个像素和样本来计算的,在测试的时候是冻结的。
可学习的输出意味着β和标准偏差γ通常会用到,可能会抵消掉之前做的事情:
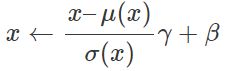
这并不像看上去那么愚蠢!就像我们在前一篇文章中看到的对权值进行缩放的例子那样,对网络参数进行重新参数化可以从根本上改变优化的前景。
对于今天的帖子,我们将省略β和γ(或把他们冻结成0和1),因为它们增加了复杂性,很大程度上与正在研究的问题无关。为了达到最高的训练精度,可学习的β是建议使用的,但是和可学习的尺度γ有时是没什么用的。
优点
从经验上看,batch norm是非常成功的,特别是在训练卷积网络方面。许多提出的替代方案都未能取代它。
稳定优化,提高学习效率及加快训练速度
它注入噪音(通过batch的统计数据),以提高泛化
降低对权重初始化的敏感性
它与权值衰减相互作用,以控制学习率的动态
第一点—优化稳定性—是关键,也是本文的重点。有其他方法可以改进泛化,只要稍加注意,就可以在没有batch norm的情况下找到良好的初始化权重,学习率动态可能更好地被显式控制(使用LARS之类的优化器),而不是像我们上次描述的隐式权重尺度动态。
让我们进行一个简单的实验来演示batch norm对优化稳定性的影响。我们在CIFAR10上训练了一个简单的、8层的、无分支的conv网络,使用或者不使用batch norm。我们将在整个帖子中使用这个网络的变体。选择非分支架构的原因是,我们将研究随着网络深度的增长和跳跃连接减少有效深度的效果,这意味着我们需要更深的架构才能看到类似的效果。
![]()
这里是结果:
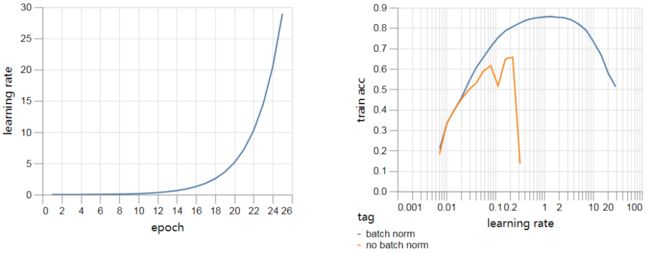
首先绘制的学习率,作为压力测试,随时间呈指数增长。第二个图显示了训练的准确性。
可以看出,具有batch norm的网络在更大的学习率范围内是稳定的(请注意第二个图中x轴上的日志刻度)。使用高学习率的能力允许对具有batch norm的模型进行更快的训练。
缺点
那么,为什么要花这么多精力寻找替代品呢?batch norm有几个缺点:
速度很慢(虽然节点融合会有所帮助)
训练和测试是不同的,所以很脆弱
对于小的batch和不同的层类型无效
它具有多种相互作用的效果,很难分离。
关于这些,我们今天没有太多要说的,只是说,一旦人们接受了batch norm之类的东西的必要性,解决这些问题似乎就容易得多了。特别是速度问题远非无法克服。一个好的编译器可以将统计数据的计算融合到上一层,并将应用融合到下一层,从而避免不必要的对内存的往返访问,并消除几乎所有的开销。
希望今天的探索也能对batch norm的基本特性提供一些指导,这些特性是任何替换都需要的。
深度网络和常数函数
本节的目的是了解深度网络在初始化时的典型行为。当我们开始训练时,我们将看到问题的迹象。如果网络要避免计算与输入无关的常数函数,在初始化时尤其需要注意。我们将回顾一个令人惊讶和被低估的事实,即标准的He-et-al初始化为足够深的ReLU网络提供了有效的常数函数。
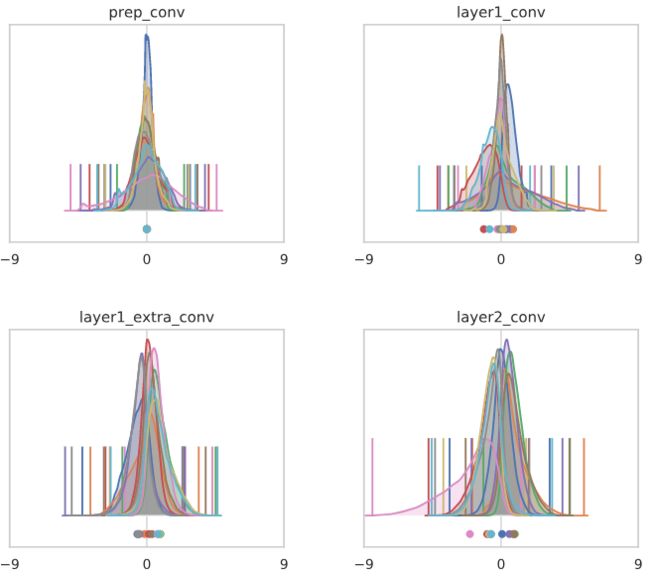
每个通道的直方图
我们来到第一个关键点。batch norm作用于每个通道上的激活直方图(通过偏移和重新调整方差),这意味着这些是非常值得监视的。似乎很少有人这么做,即使在研究batch norm的论文中也是如此。一个值得注意的例外是Luther and Seung最近的论文:https://arxiv.org/abs/1902.04942,我们将很快对此进行讨论。
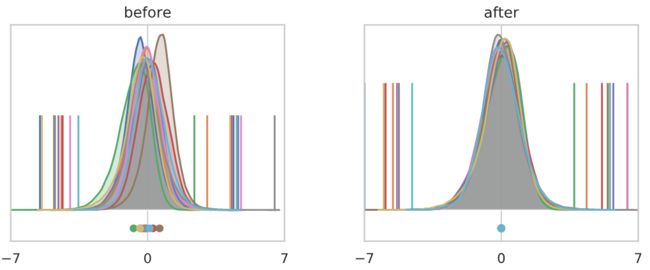
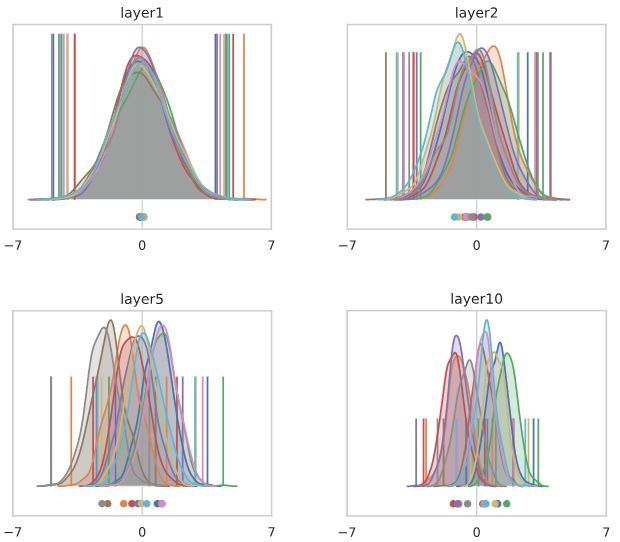
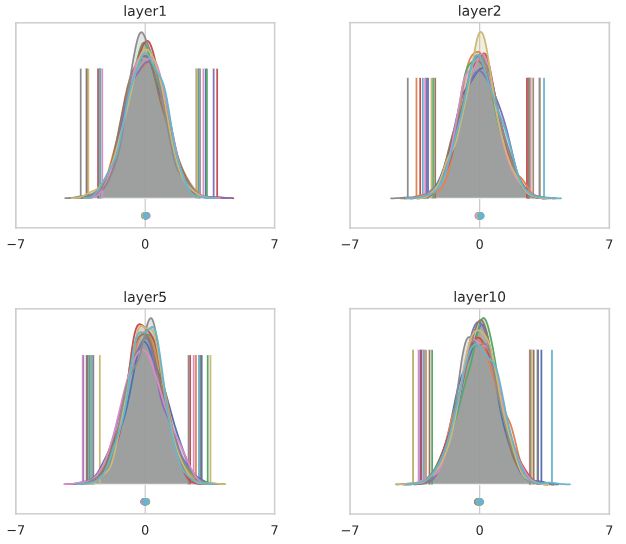
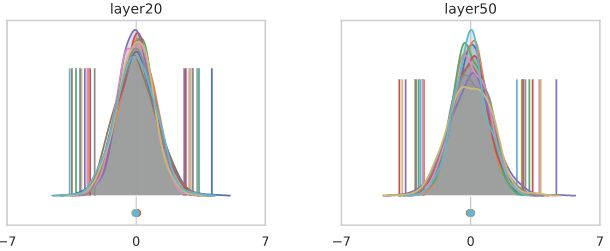
下图显示了激活值的直方图,这些值在batch中跨越像素和样本,在batch norm层之前和之后。不同的通道用不同的颜色表示,每个通道的平均值显示在下面,每个通道的最小/最大值由垂直ticks表示。严格地说,这些是核密度估计,而不是直方图。我们每层最多显示10个任意选择的通道,以避免过度拥挤。
在接下来的文章中,我们将会看到很多类似的情节,所以请花点时间来理解细节……
按照Luther和Seung的方法,让我们考虑一个非常无聊的网络,它由交替的全连接层和ReLU层组成,大小相同,没有batch norm。以下是前10层:
![]()
我们使用标准的He-et-al初始化随机初始化权重,该初始化的目的是,如果我们将一个层中的通道合并在一起,则可以保持整个网络中层输出的平均值和方差。实际上,这并不是He-et-al初始化的真正作用——如果我们将权重分布边缘化,它将保持输出的均值和方差,但这与通道池化非常接近,我们将忽略这里的差异。
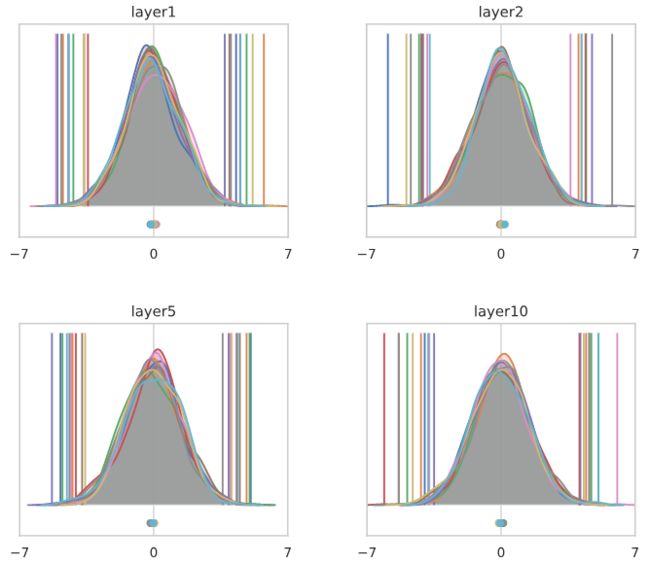
我们来看看网络中不同深度的通道激活的直方图,其中有N(0,1)个输入。首先,我们看通道池化直方图,以检查初始化做了它该做的事情:
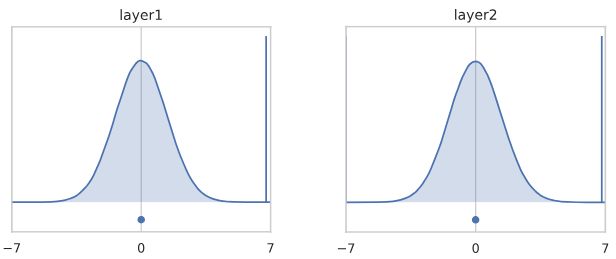

在第50层的时候,会变得有点不稳定,但是通常情况下应该是这样的。
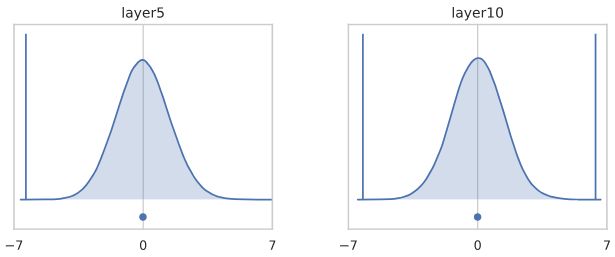
现在让我们看看同样的直方图,按通道分割:
直方图表现出来的是非常不同的东西!
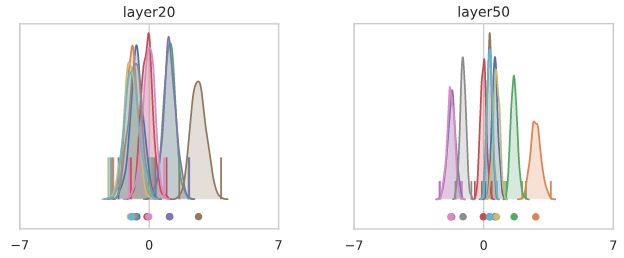
到第50层时,每个通道都高效地选择了一个要取的常数,与输入无关。假设第50层是softmax分类器之前的最后一层(只包含显示的10个通道)。大多数输入将被归类为“橙色”类,只有少量“绿色”,除此之外别无其他。从这个意义上说,一个随机初始化的网络喜欢计算(大多数)常数函数!
如果我们移除ReLUs并适当地重新调整权重,这样我们就得到了一个纯线性网络,问题就解决了。在较深的地层中,我们最终观察到不同通道之间的差异,但效果相当温和。
其他的方法:SVDs,随机矩阵等等
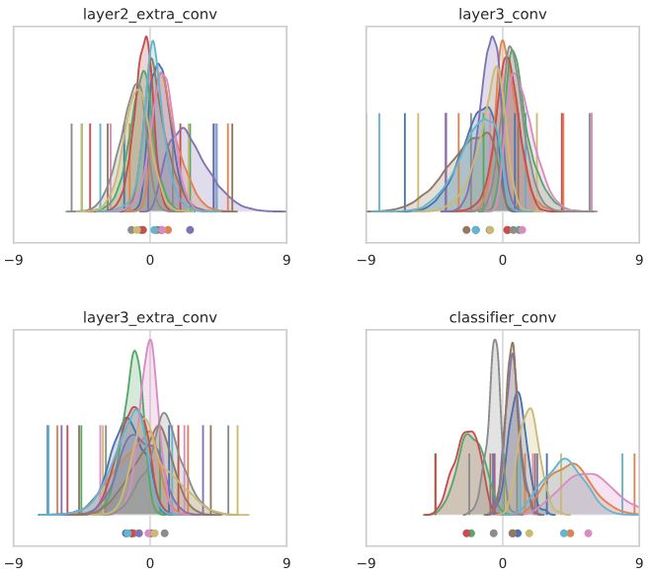
事实上,每个通道的直方图并不能说明全部情况,在深层的通道之间有显著的相关性。如果我们计算线性网络表示的线性映射到不同深度的奇异值分解,可以看到:
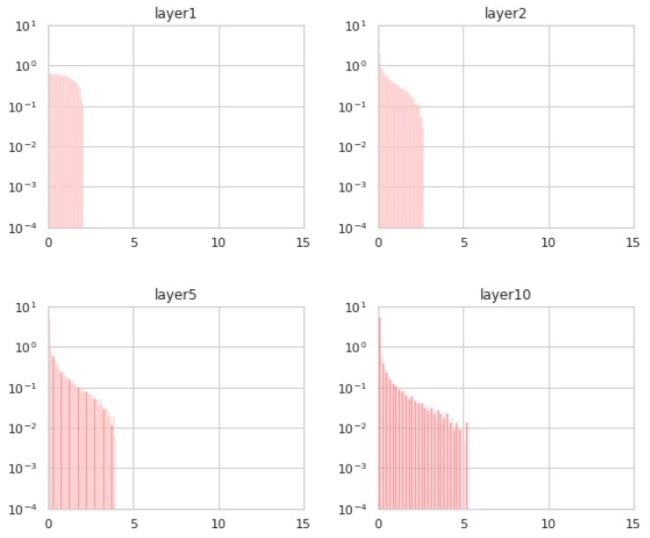
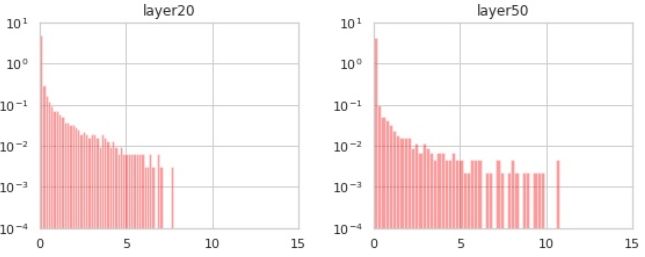
到第50层时,某些通道的组合被拉伸了约10倍,这在每个通道直方图中是不可见的。在Pennington-et-al ' 17中有一个基于随机矩阵理论的优雅分析,解释了这里发生的事情。关于这个问题我们就不多说了,因为与添加ReLU层的效果相比,效果很小,由于这种效果在添加残差连接后将大大改善,而且由于batch norm的影响,只看到每个通道的统计数据,很大程度上是正交的。
在初始化的时候固定ReLU网络
那么,包含ReLUs是如何导致我们在上面观察到的问题的呢?结果表明,由ReLU层引入的非零通道是问题的根源。
由于ReLUs只返回正值,当我们第一次通过ReLU层传递一个集中的输入分布时,我们得到一个输出分布,其中每个通道的平均值都为正值。在下面的线性层之后,通道仍然有非零的平均值,尽管这些平均值现在可以是正的或负的,这取决于特定通道的权重。这是因为线性层的输出均值等于应用于输入均值的线性层,由于前面的ReLU,输入均值是非零的。关键是,对于固定的权重,每个通道的平均值现在都是非零的,而如果我们对权重进行平均,这种影响就会消失(通过权重分布在零附近的对称性)。
不太明显的是,这种影响应该通过网络继续增长,其幅度随深度增加。这可以通过Luther and Seung ' 19中的直接计算得到,也可以从ReLU的直接性质和权值分布关于零的对称性得到。
相应损失的方差在每个通道遵循总方差法则,也就是说总方差,由权值分布集成而来—在使用He-et-al初始化的时候是保持不变的—分解成每个通道的方差的均值和每个通道的方差的和。(这种分解在上面ReLU网络的每个通道直方图中可见。)每一通道意味着每增加一层方差都会增加,而总方差是固定的,因此每一层通道内的方差必须减小。在足够的深度下,到达一个不动点,此时通道内没有更多的方差,并且在每个通道均值的分布中实现了完全方差。此时网络正在计算一个常数函数。
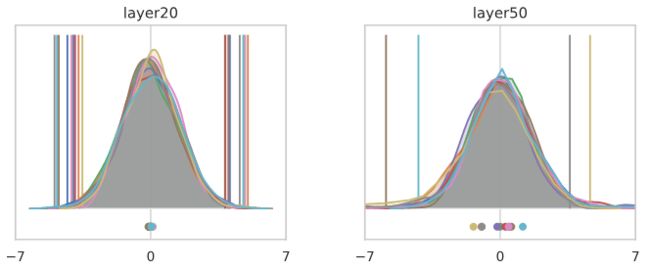
所有这些建议了一个相当简单的解决方案:我们应该减去每个ReLU层后的平均值,然后重新缩放以恢复总方差。在这个有N(0,1)输入数据的简单网络中,我们可以分析地计算相关的均值和比例因子,但更一般地说,这对应于使用“冻结的batch norm”层进行初始化,该层计算静态偏差和比例,以标准化初始化时的每个通道均值和方差。
有了这个修正,秩序恢复了,网络不再计算一个常数函数:
真实的网络是什么情况?
在使用卷积、池化和实际数据的更现实的环境中会发生什么?
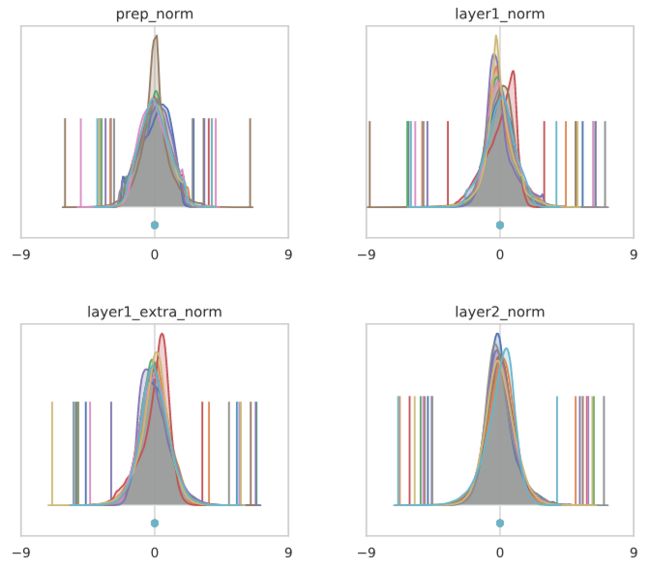
让我们考虑之前的8层无分支conv网络,没有batch norm层。在初始化独立的N(0,1)输入数据时,每个通道的输出分布如下:
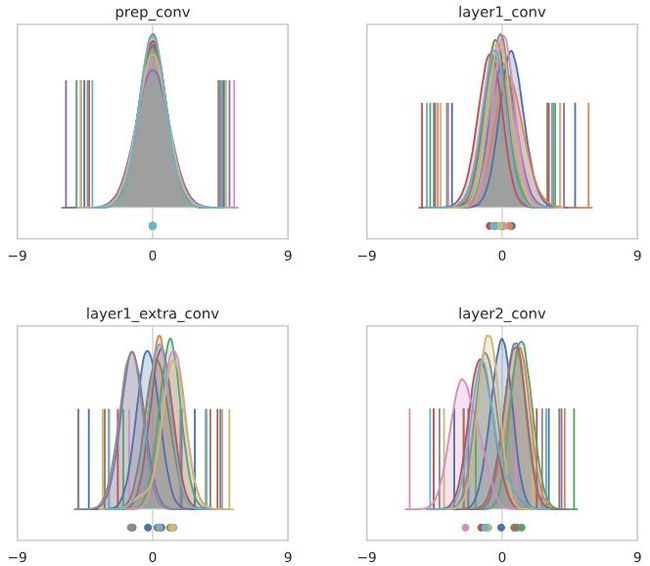
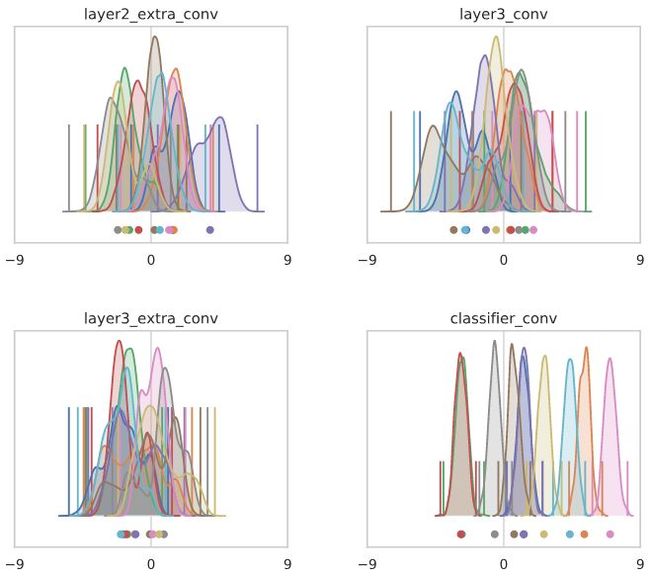
在这个网络中,常数函数崩溃的速度更快!这在一定程度上是因为包含了最大池化层,它还可以增加每个通道的均值。使用CIFAR10输入,情况略有改善,但效果明显还在:
如果我们重新引入batch norm层(或冻结的batch norm层),那么通过设计,中间层将恢复为均值为零,每个通道的方差为1。这阻止了整个网络中每个通道的任何增长。然而,最终的分类器并没有受到batch norm层的影响(这可能会限制表达性并影响训练性能)。由于分类器的输入同时经过ReLU和max-pooling层,所以这些输入已经具有相当大的正均值,导致分类器输出时每个通道均值的变化。与没有batch norm的网络相比,这种影响稍微温和一些,但在这种情况下并不是不存在的:
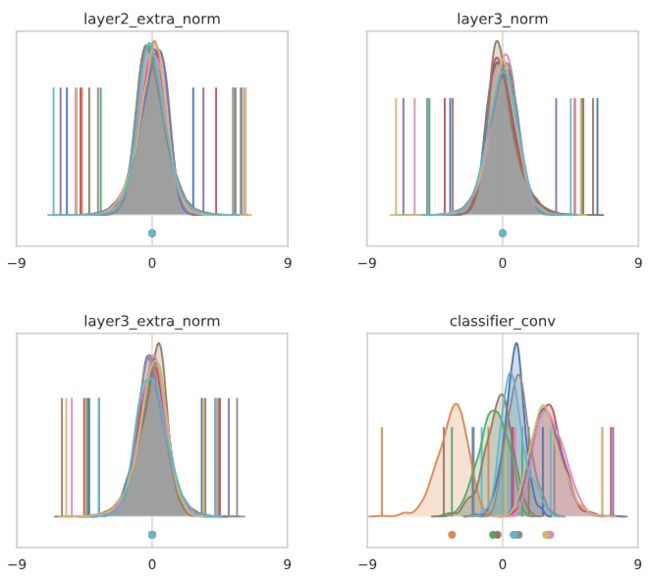
做个小结
到目前为止我们学到了什么?
在没有batch norm的情况下,深度网络的标准初始化方案会导致“糟糕”的配置,在这种配置中,网络可以有效地计算出常数函数。通过设计,batch norm在解决这个问题上走了很长的路。就初始化而言——基于初始化时的激活统计数据的“冻结的batch norm”也同样有效。
下一个更有趣的问题是,当我们开始训练时会发生什么?我们将发现,在初始化时,坏的网络配置的普遍性反映了一个更深层次的问题:在没有batch norm的情况下,在训练运行期间所遍历的好的配置的一个小邻域中存在坏的配置。这些错误配置的接近性—高训练损失—表明在损失范围内存在高度弯曲的方向,并限制了可实现的学习率。
训练稳定性
其余部分的结构如下。
首先,我们描述了三个部分训练的网络进行比较:一个有batch norm,一个没有batch norm,第三个是冻结的batch norm。
我们证明,对于没有活动batch norm的两个网络,可以使用backprop找到附近产生恒定输出的参数配置,从而获得较高的训练损失。
我们以Hessian征值的形式研究了训练损失的曲率与SGD不稳定性之间的关系。
然后计算三个网络的主要特征值和特征向量。我们发现,没有batch norm的网络具有少量的孤立特征值,这极大地限制了可达的学习率。我们展示了相应的特征向量是如何与我们发现的附近的“坏”参数配置相关联的。
网络
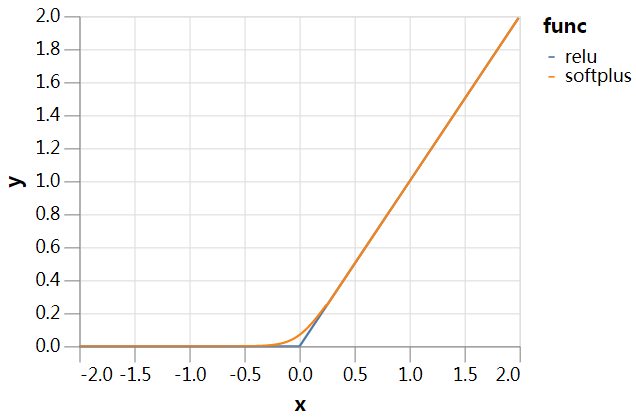
我们将继续使用上面的8层无分支网络,使用或不使用batch norm,只有一个小的改动。由于我们将很快使用autograd计算二阶导数,我们将用一个平滑的版本替换ReLU非线性——它的二阶导数几乎到处都是消失的,因此autograd看不到它。我们选择使用所谓的“softplus”非线性,但细节并不重要。这可能是不必要的预防措施,但至少不应该造成伤害。我们继续把(平滑的)非线性称为下面的ReLU。
我们想了解网络在训练过程中的典型状态。我们将使用前一篇文章中的线性热身和衰减策略,研究经过10个训练阶段后的网络——典型训练运行的中途阶段。由于没有batch norm的网络在较高的学习率下是不稳定的,因此最大学习率必须根据网络进行调整。这些选择相当武断,但结论似乎是可靠的。特别是在经过整整20个epochs的训练后所进行的实验产生了类似的结果,而准确的最高学习率和策略似乎并没有多大区别。
我们考虑第三个网络,与batch norm相同,经过10个训练阶段后,batch norm层将冻结。这使我们能够将初始化和训练轨迹的问题与batch norm的持续稳定效果分离开来。我们将发现,没有激活的batch norm层的两个网络的行为相似,并且与batch norm网络完全不同。
关于学习率大小、梯度、Hessian特征值和参数空间中的扰动的表述只有在我们确定权重的比例时才真正有意义。正如我们在前一篇文章中所讨论的,有许多其他方法可以参数化这些权重尺度不同的相同网络,特别是在存在batch norm的情况下。
找到不好的配置
我们给自己设定了以下任务:对于这三个部分训练过的网络,我们能否在参数空间中找到近似于常数函数的配置,并且相应的训练损失也很高?事实上,让我们将问题细化如下。我们能否在参数空间中找到附近的配置,使网络(大部分)输出一个固定的、选定的类?第二个问题适用于使用backprop的解决方案——我们可以根据所选类的平均分类器输出的模型参数计算梯度。我们可以在那个方向上扰动。
首先,我们计算每个网络的10个分类器输出的平均值的梯度,然后在每个梯度方向上用一个固定长度的向量扰动。这三个部分训练的网络的可学习参数向量具有近似相同的范数——实际上“batch norm”和“冻结的batch norm”网络具有相同的可学习参数。
我们看看如果我们被固定长度的向量扰动1%的基础参数向量的长度会发生什么。作为基线,我们首先用一个长度为1%的随机向量来检查未扰动的、通道分布以及扰动参数的影响:
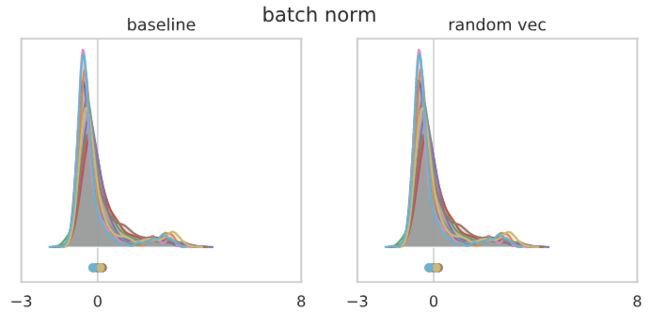
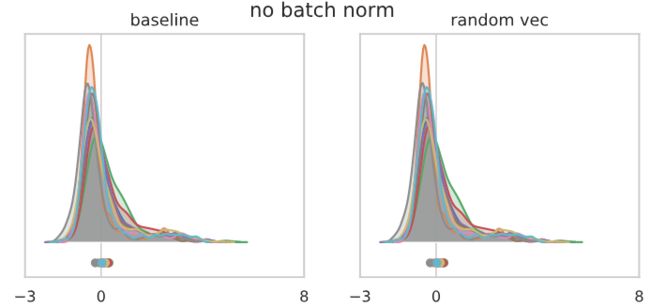
关于上面的图,有几点需要注意。(注意,我们正在查看最后一层输出的缩放版本,而在初始化时,我们正在监视未缩放版本——输出的缩放是通过训练过程实现的。)
首先,这三个网络产生了类似的输出分布——实际上,“batch norm”和“冻结的batch norm”的输出几乎是不可区分的,正如人们可能希望的那样。分布由一个主模式和另一个较小的模式组成,该模式在一定距离的右侧,这是网络的特点,开始对每个输入的单个类进行有信心的预测。不同类的总体分布情况相似,没有单一的类占主导地位,与现阶段所观察到的训练正确率约85%一致。最后,1%长度随机向量扰动后的分布与基线在视觉上无法区分。
接下来,让我们看看当我们被上面计算的通道平均值的梯度扰动时会发生什么,它也被归一化为底层参数向量长度的1%。为了节省空间,我们将只显示与前四通道平均值对应的扰动。
首先是“batch norm”模型:
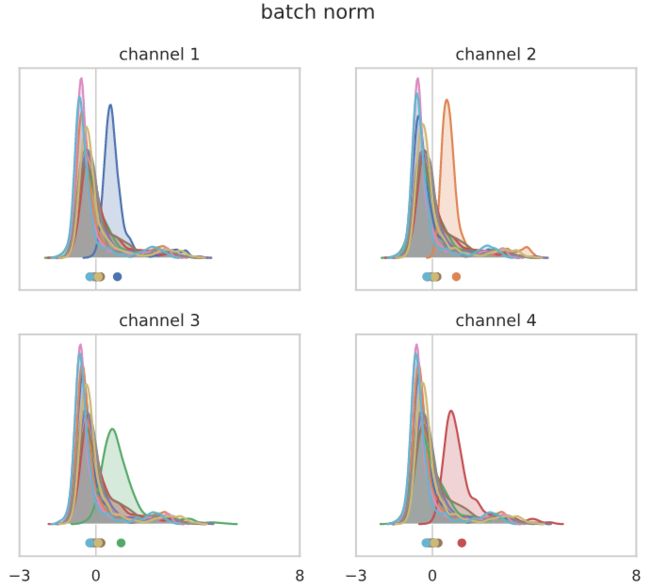
与相同长度的随机向量不同,目标扰动的影响是明显可见的。然而,这种长度的扰动并不足以产生恒定的输出和灾难性的训练精度损失。
下一个是“冻结的batch norm”模型:
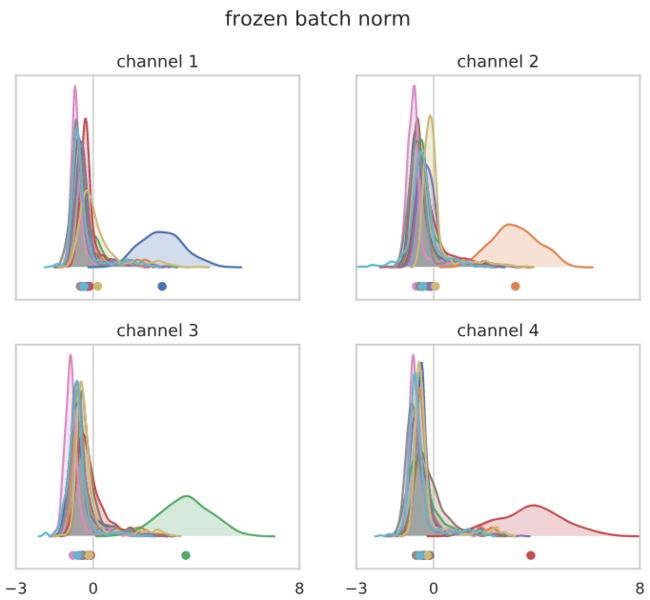
这里的效果更强!受干扰的网络根据大多数输入预测所选的类别,导致训练损失的急剧增加。
“没有batch norm”模型的行为类似于“冻结的batch norm”模型:
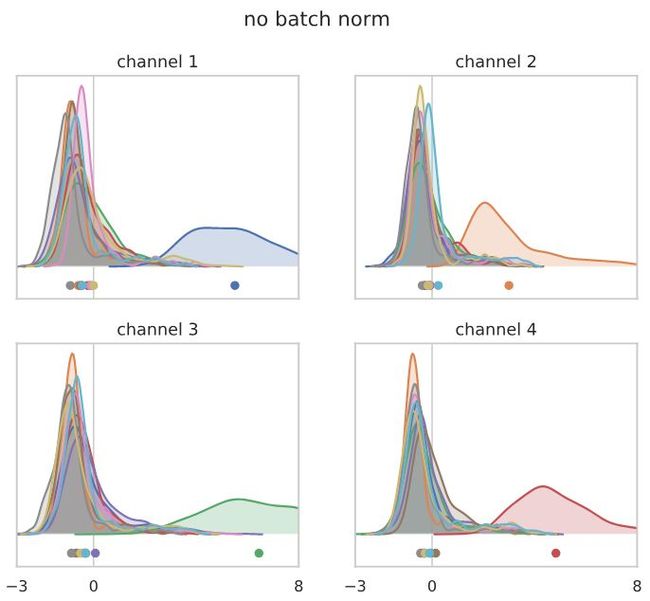
这是怎么回事?为了得到更深入的了解,让我们看看上面计算的平均通道输出的梯度。特别地,让我们看看这些梯度的平方范数,以及它如何在每个网络的层之间分布。由于所有10个输出通道的效果都是相似的,所以我们只显示第一个通道的梯度:
有几件事需要注意。首先,对于两个没有激活batch norm的网络,梯度范数要大得多。这与上面的结果一致:对于梯度方向上的定长扰动,梯度越大,对通道输出的影响越大。重要的是,梯度集中在“batch norm”网络的最后一层,而分布在其他两层。我们可以这样理解。
对于没有激活batch norm的网络,输出在前一层分布的变化可以传播到后一层分布的变化。换句话说,内部协变量偏移能够在输出层传播到外部偏移。这与初始化时的问题密切相关,在初始化时,非零意味着在较早的层传播到较晚的层。由于较早的层接收经过ReLU并具有正平均值的输入(即使ReLU之前的平均值为零),因此可以很容易地调整权重,以产生输出平均值的变化。对于“batch norm”网络,通过后续的batch norm可以消除对早期层的平均值和方差的更改,因此早期层影响输出分布的机会很小。
在第一个输出通道的正态梯度扰动后,我们可以透过观察整个网络的通道分布,直观地了解“冻结的batch norm”网络的情况:
较早的层—由于冻结的batch norm,在扰动之前的平均值为零—在我们通过这些层时具有越来越大的平均值,这导致了输出中目标通道的较大变化。除了平均值的变化外,每个通道直方图中与基线相比几乎没有其他变化。
在ReLu之后使用batch norm
在上面的讨论中,重要的一点是,由于ReLUs,早期层的传入激活具有非零均值,即使pre-ReLU激活具有零均值。这进而允许权重的扰动影响输出平均值。如果我们在ReLU层之后应用batch norm,然后在部分训练之后冻结,我们可能会看到另一种情况,在这种情况下,早期层的权重扰动的影响会大大减弱。(这与初始化时的情况很不一样,我们在简单的、全连接的网络中在ReLU之后使用了分析移位和缩,发现传播均值和常数输出的问题消失了。)
我们通过计算这样一个网络的输出通道均值的梯度,并绘制扰动的效果,来检验是否存在这种情况:
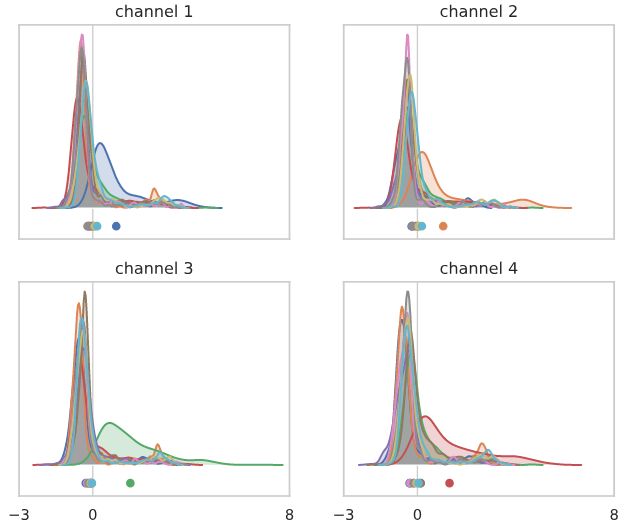
扰动的影响要比没有batch norm的其他网络小得多,并且与batch norm网络的影响相似!同样地,如果我们检查单个输出通道梯度的平方范数,我们会发现这个网络的范数要小得多,而且主要集中在最后一层。
这是一个解决稳定性问题的解决方案,而不需要激活的batch norm吗?不完全是。
首先,batch norm后,由于后续训练过程中的随机漂移,均值在早期层重新出现,一旦这些均值回来,不稳定性就会重新出现。此外,正如我们将在下一节中看到的,除了输出均值之外,还有其他问题。例如,即使在没有非零输入均值的情况下,由于ReLU是一个凸函数,递增的,早期层仍然可以通过重新调整权重来控制其输出方差。传递给ReLU的分布的方差是增加ReLU均值的另一种方法。
尽管如此,在ReLUs之后,使用batch norm的网络要比通常的网络稳定得多,这是进一步研究的方向。
什么时候梯度下降会出问题
人们很容易陷入拟人化算法的陷阱,但梯度下降是一种相当原始的生物。它只有蚂蚁对周围景观的视角,没有记忆。由于发现自己处于一个足够陡峭的山谷中,这个算法观察到,当它沿着山谷两侧振荡时,梯度在不断增大。
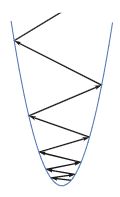
对于两个没有激活的batch norm的网络,我们发现了附近的配置大多是输出的是常数且训练损失高的配置,说明我们发现自己处于这样一个陡峭的山谷中。如果我们能够证明这些是损失领域中“最”弯曲的方向,而类似的弯曲方向不存在于batch norm中,那么我们将相当准确地理解batch norm稳定优化和提高学习率的机制。为了进一步证明这一点,我们需要找到一种方法,来识别损失域中最弯曲的方向——那些对可达的学习率有最严格限制的方向。
在一维中,对于损失函数l(x),一个步骤之后的梯度x←x–ηv:
![]()
在梯度下降之中,v=l′(x),在l′中的更新为:
![]()
假设l”(x)>0,最高的稳定学习率为:
![]()
超过这个范围,梯度和损失会随着时间呈指数增长,如上图所示。
在高维情况下,向v方向迈出一步后的梯度为:
![]()
其中,H是l的二阶导数矩阵,也就是Hessian矩阵,在l′中的更新为:
![]()
假设所有H的特征值是正的,稳定的最高学习率由最大的特征值λmax:
![]()
增加momentum带来一些额外的稳定性,但最大的学习率仍然受限于一个常数乘以λmax的倒数。这在温和的、局部的非凸性和良好的随机梯度存在时仍然成立。
如果SGD突然在损失和参数值中出现 ‘nan’错误,Hessian矩阵的大特征值通常(总是)是罪魁祸首。如果参数空间中几乎所有的方向都表现得很好,这并不重要——只要有一个方向对应于Hessian矩阵的一个大特征值,SGD就会发现自己的振荡失去了控制。
在下一节课中,我们将展示如何计算H的主要特征值/向量,并看看这些与我们前面确定的具有常数输出的邻近配置之间的关系。
计算Hessian矩阵
我们每个网络都有超过400万个可训练参数,因此直接计算Hessian矩阵将是非常痛苦的。幸运的是,如果我们只对主要特征值和特征向量感兴趣我们不需要这样做。
当初始化一个随机向量时,同样的导致梯度下降不稳定的Hessian定理的重复应用,最终将生成一个与最大特征向量成比例的向量。由此可以很容易地计算出最大特征值。对这个向量进行正交并重复这个过程可以分离出子引导特征向量和特征值。这就是著名的Power方法。我们将使用稍微复杂一点的Lancsoz算法,基于相同的原则,通过scipy中的实现。
我们还需要一种计算Hessian向量积的方法,这可以使用autograd通过著名的Pearlmutter技巧来完成。这个repo:https://github.com/noahgolmant/pytorch-hessian-eigenthings为开发我们的实现提供了一个有用的参考。
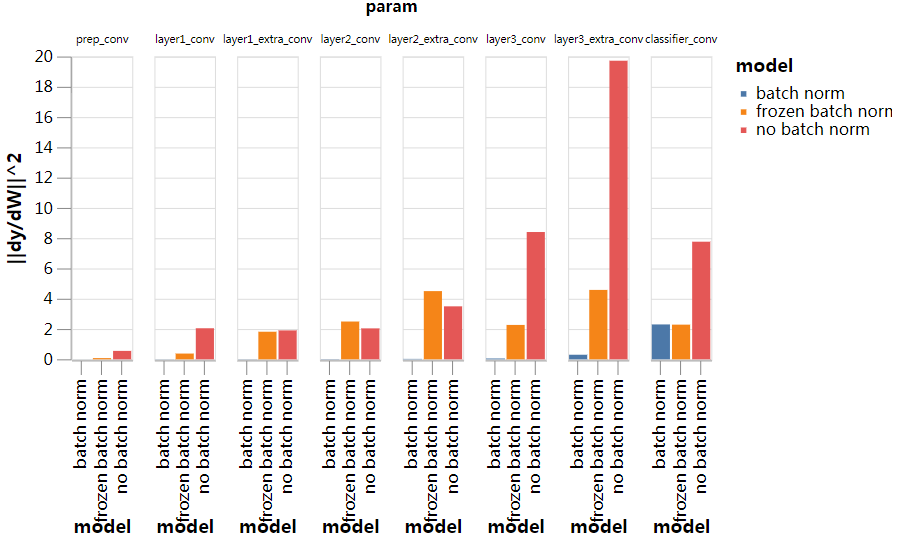
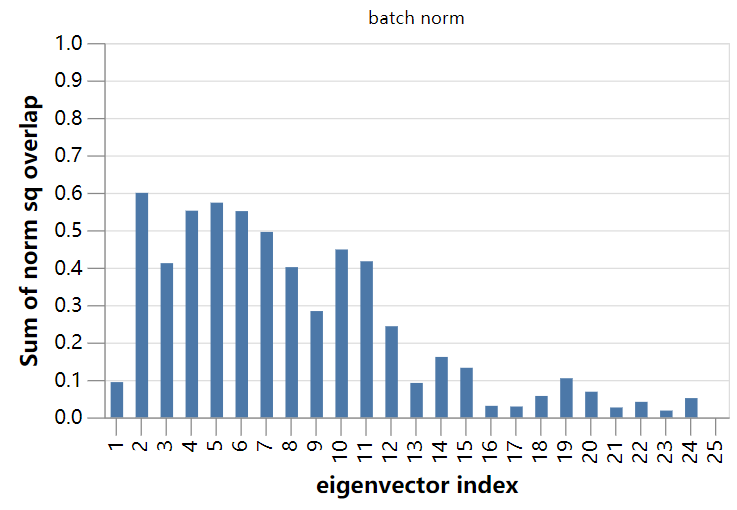
我们来绘制这三个网络的主要特征值:
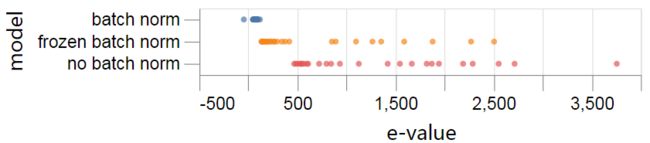
batch norm模型的特征值比其他两个网络的主特征值小1-2个数量级,这与该模型较高的稳定学习率相一致。
冻结的batch norm模型有9个或10个外围特征值,和在其他地方发现的结果是一样的,发现异常值的数量大致是类别的数量。我们将在下一节中把这些与10个输出通道的平均扰动联系起来。
最后,在此阶段的训练中,“无batch norm”网络的情况显得更为复杂,具有较大的边缘特征值集。
排在前面特征向量的解释
现在是时候通过将Hessian的外围特征向量与我们之前发现的附近的“坏”配置联系起来了。Hessian的特征向量对应于损失视角中最弯曲的方向,负责限制可实达的学习率。
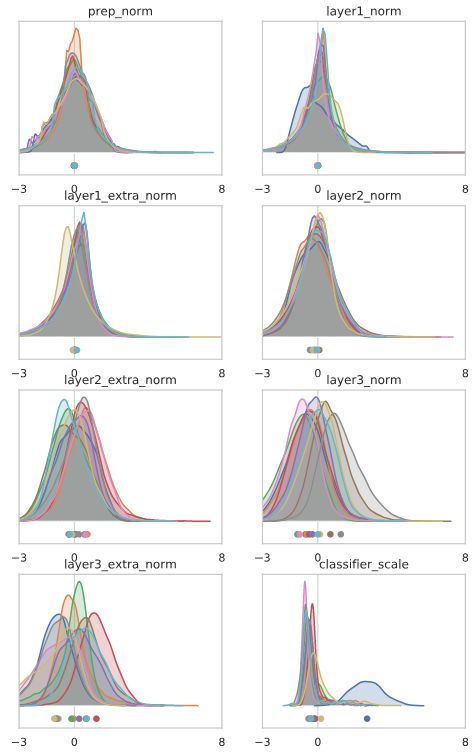
作为第一步,让我们来观察这些主要特征向量对网络参数的扰动作用——像以前一样缩放到底层长度的1%。我们将观察输出层的每个通道直方图的影响,并显示前10个特征值v1-v10的结果。
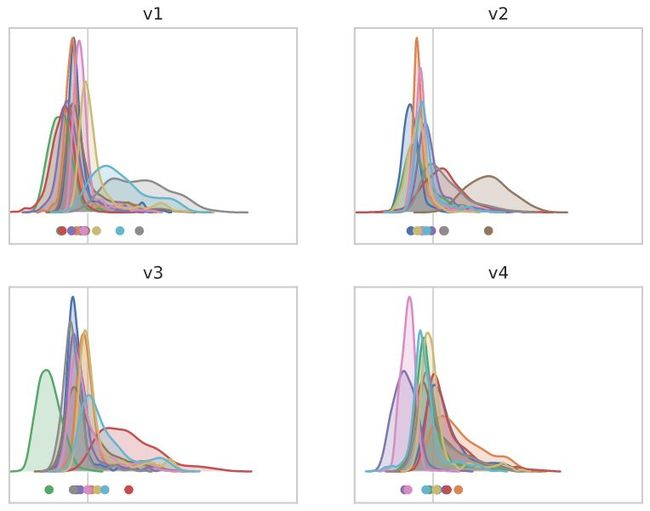
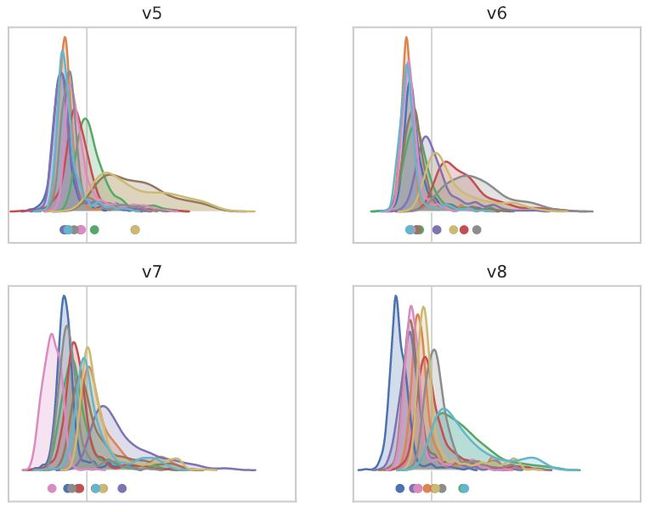
对于“batch norm’”模型,不同渠道的均值受到一定的影响,但影响较轻。
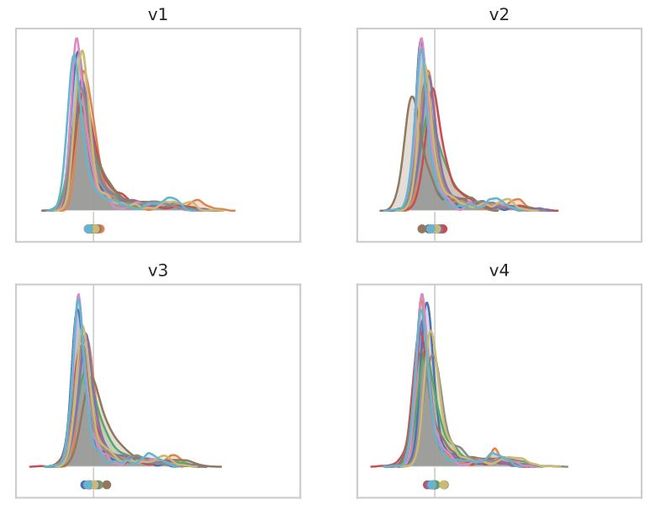

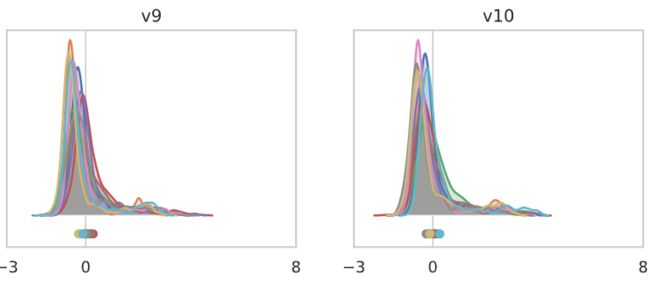
对于“冻结的batch norm”模型,出现了一个清晰的图像,其中,通常少数通道的均值受到来自v1-v9的每个特征向量的影响,而v10似乎主要对应于输出的重新缩放。
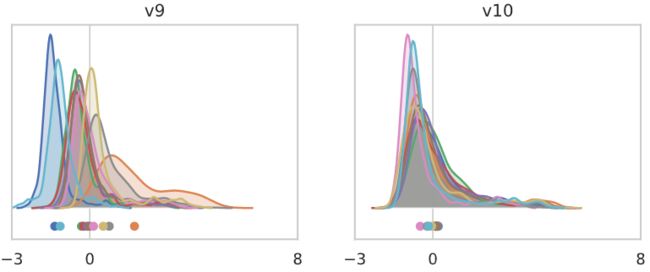
对于“无batch norm”模型,这10个特征向量似乎对应于不同通道的均值扰动和重新缩放的混合。
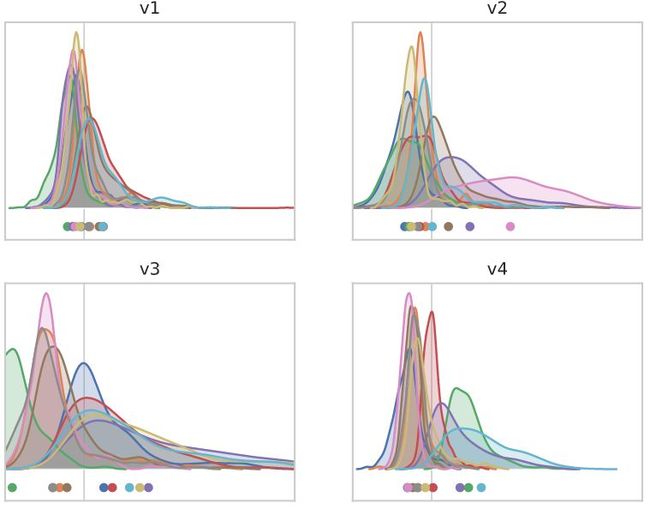
我们如何把这个分析变得更加精准一些?
我们手头有10个向量对应于每个输出通道均值的梯度。有了这些,我们可以计算它们张成的10维子空间并测量给定特征向量的范数平方在这个子空间中占多少。请注意,相同维数的随机向量(> 400万)在给定的10维子空间中有一个小于10−5的模平方分量,并且具有很高的概率。
实际上,并行移动所有输出意味着不会对损失产生影响,因为类的概率是通过应用softmax函数来计算的,而softmax函数在这样的整体移位下是不变的。因此,影响损失的通道平均梯度的相关子空间为9维,而不是10维。损失的方向恰好是平坦的,而Hessian的特征值在总位移方向上对应为零。从现在开始,我们将把通道平均梯度的子空间描述为9维,尽管为了简单起见,下面的代码使用完整的10维空间。
我们来计算特征向量和9维子空间之间的范数平方的重叠部分:
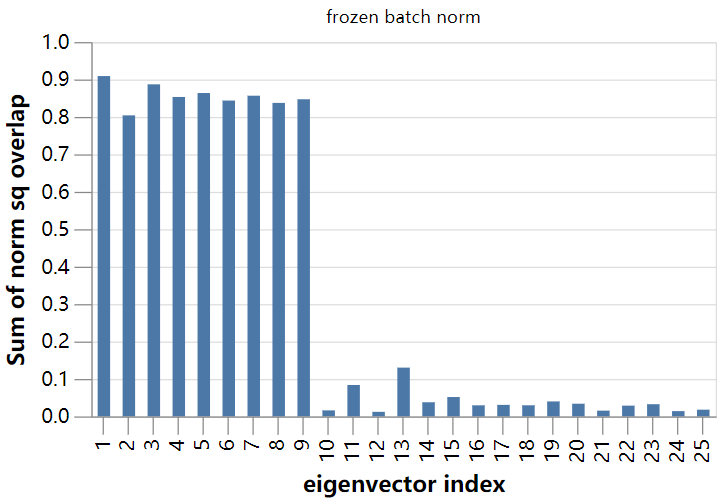
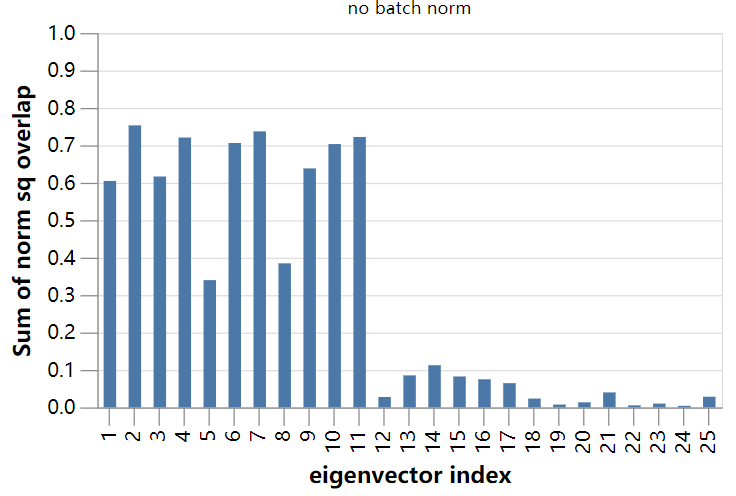
看到了吧,这并不是巧合!
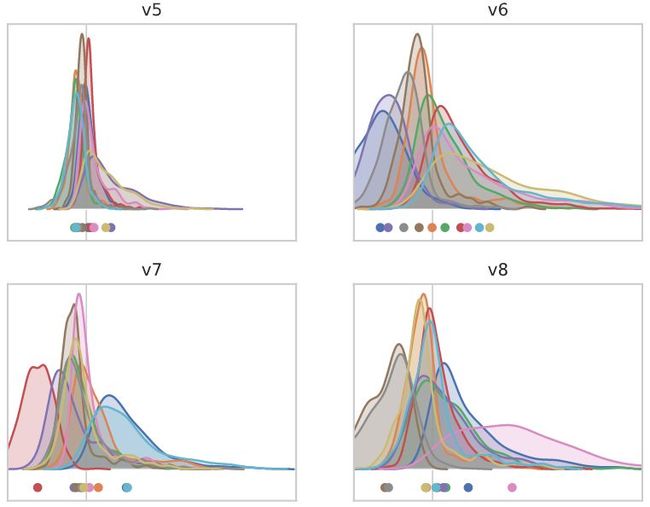
对于“冻结的batch norm”模型,我们立即对9个独立特征向量有了清晰的理解。这些几乎完全位于输出通道均值梯度的9维子空间中。我们的结论是,对于这个模型,SGD的主要不稳定性仅仅是由于无法控制输出的均值造成的。
我们能更好地解释其他模型的主要特征向量的更大比例吗?
在前面的图中可以看出,这些特征向量也影响输出方差。一个合理的想法是将我们的9维子空间扩展到19维,包括10个输出通道方差的梯度,甚至包括29维,包括输出通道的3阶矩或“倾斜”。重新缩放输出通道是另一种有效地破坏所有训练示例损失的方法,而且由于输出分布高度倾斜——为了让它们能够自信地预测给定的类——改变倾斜也可能产生影响。
让我们使用上面机制来测试一下。首先计算各模型输出通道的方差和倾斜的梯度,然后计算特征向量与子空间之间的范数平方的重叠:
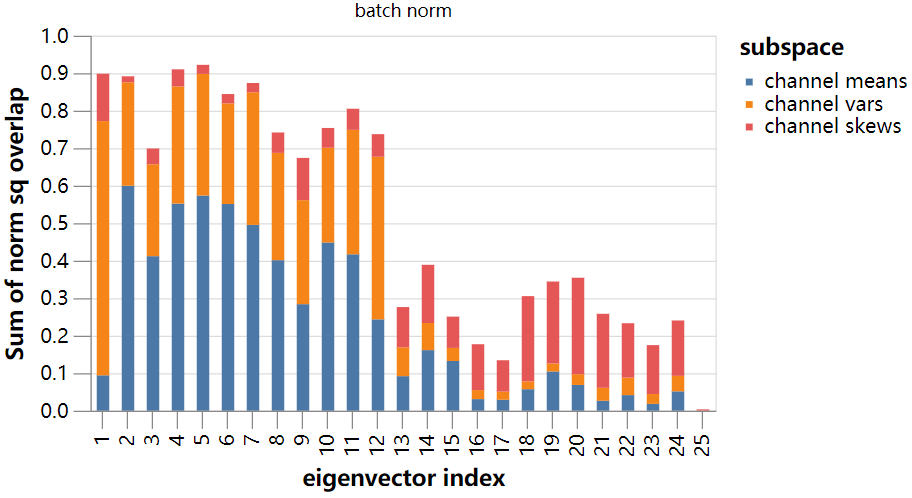
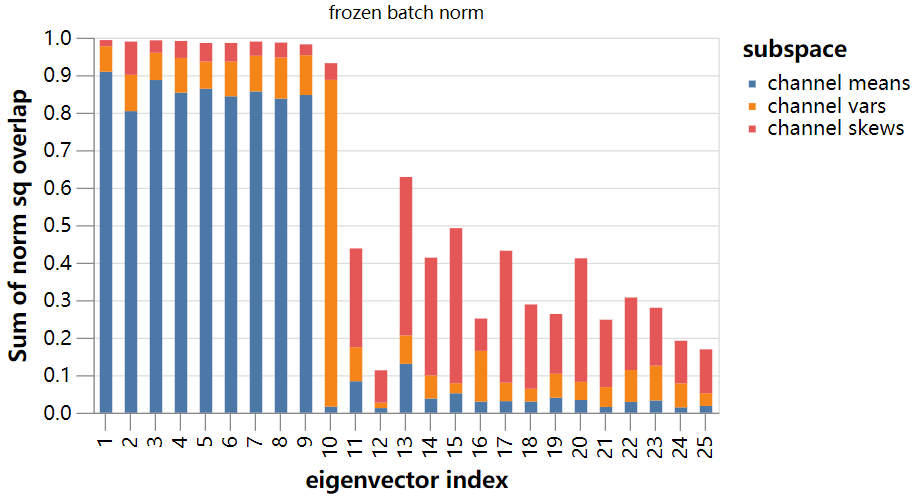
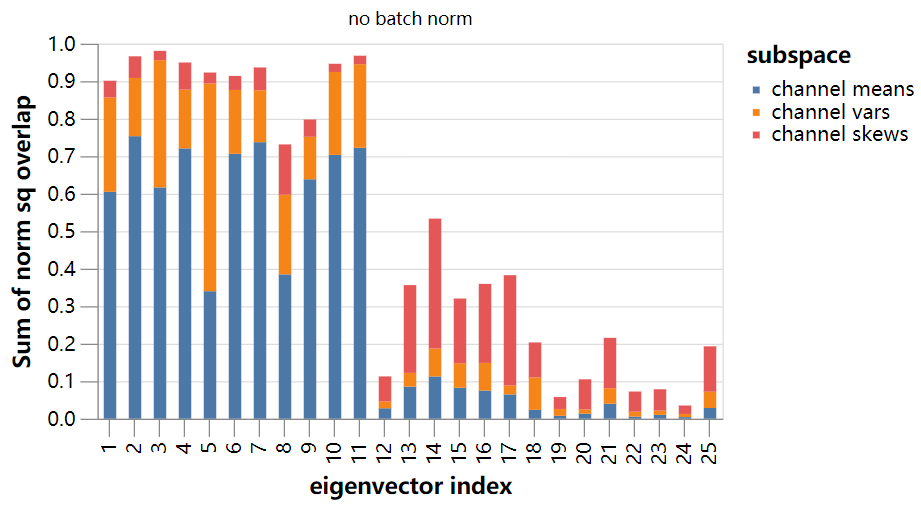
结果更加明显!
我们已经证明,“冻结的batch norm”模型的前10个特征向量几乎完全位于完整的> 400万维参数空间的29维子空间(由每个类输出分布的前三个矩的梯度张成)的可解释范围内。对于“无batch norm”模型,甚至对于“batch norm”模型,结果几乎同样惊人。
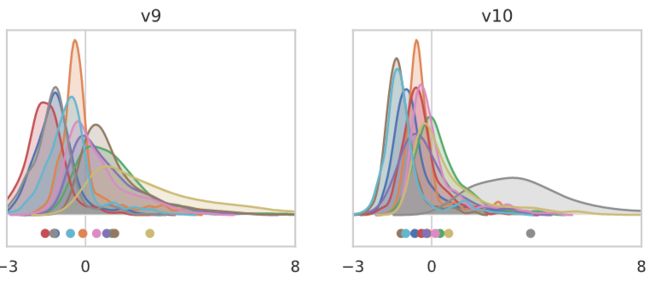
最后一点可能看起来很奇怪,但是回想一下,对于batch norm模型,主特征值要小得多。下面我们通过对应的特征值重新调整了bar。我们可以看到,即使我们从输出的前三个时刻确定了不稳定性,没有激活的batch norm的两个模型仍然比batch norm模型稳定得多。
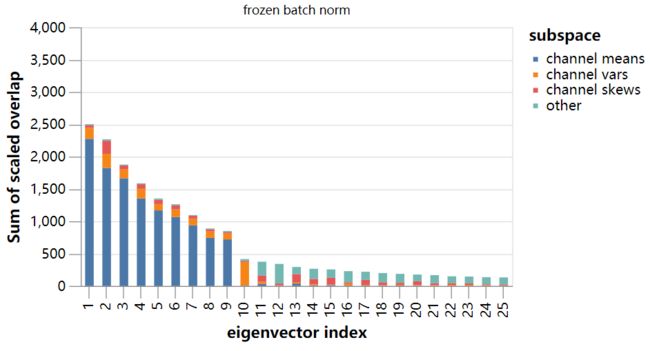
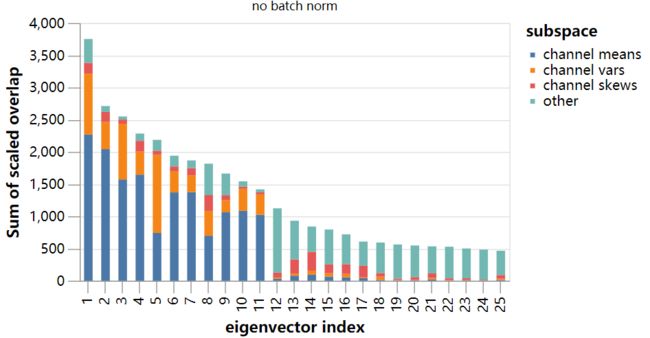
更精确的方法是重新计算被限制在与三个输出力矩的梯度的29维子空间正交的子空间上的Hessian矩阵的主导特征值:
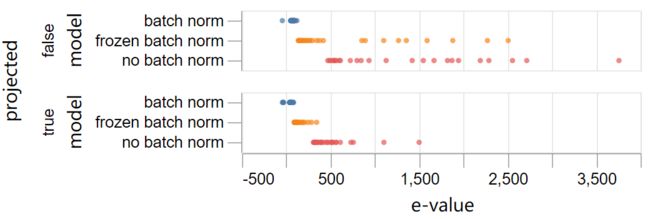
我们发现,“无batch norm”和“冻结的batch norm”模型比以前稳定了很多,但是在它们达到“batch norm”模型的稳定性之前,还有很多工作要做。我们在下面讨论这个问题。
讨论
我们学到了点什么?
首先,我们回顾了结果,在没有batch norm的情况下,具有标准初始化的深度网络往往会产生“坏的”,几乎是常数的输出分布,其中的输入被忽略。我们讨论了batch norm是如何防止这种情况发生的,并且可以通过使用“冻结”batch norm在初始化时修复这种情况。
接下来,我们转向训练,并展示了“坏”配置存在于典型训练运行期间遍历的参数配置附近。通过计算每个通道输出分布平均值的梯度,我们明确地发现了这样的邻近配置。稍后,我们通过计算每个通道输出分布的方差和倾斜的梯度来扩展这一点,我们认为改变这些高阶统计量也会导致损失的大量增加。我们解释了batch norm如何通过防止对内部层分布统计信息的更改传播,从而大大降低这些方向上的梯度。
最后,我们研究了导致SGD失稳的主要特征值和损失Hessian特征向量,并证明了主要特征向量主要位于我们之前计算的输出统计量梯度的低维子空间。对这一事实的解释是,不稳定的“原因”实际上是由于未能对输出分布的矩施加适当的约束而产生的高度弯曲的损失情况。
退后一步,我们得到的最主要的教训是深度网络提供了一个方便的参数化的非常大不同类别的函数,能表达许多感兴趣的计算,但在这个参数化有一定的约束,需要产生有用的函数,而不是常量。在训练过程中,必须保持这些约束,这给SGD这样的一阶优化器带来了沉重的负担,SGD的学习率受到正交于“好”子空间方向的陡峭曲率的限制。
一个可能的解决方案是使用二阶优化器来处理有问题的曲率。(事实上,我们的研究结果为使用所谓的“广义高斯-牛顿”近似于Hessian定理的二阶方法的成功提供了一些线索,因为我们确定的孤立特征值来自于这一项。)然而,上述结果可能会让人相信,与一阶优化器相结合的batch norm(通过改进函数空间的参数化,直接解决存在问题的曲率背后的问题)等方法将很难被击败。
尽管我们关注的是输出层中通道的分布,但是仅仅解决这些问题是不够的。如果是的话,我们可以在网络的末端放置一个单独的batch norm层,这可以和分布在整个网络中的batch norm一样有效。上面的最后一个图显示了在固定输出分布的前几个矩之后剩余的不稳定性的大小,表明这样做不太可能接近网络的稳定状态,因为整个网络中都有batch norm层。
一个合理的预期是,为了保持由网络计算的函数的表达性,内部层分布也很重要。例如,如果在某个中间层,少数通道占主导地位,就会带来瓶颈,从而大大减少了网络能够表示的函数集。我们期望直接处理这种“内部”分配的转移是batch norm的进一步作用,这是未来研究的一个有趣方向。
另一个教训是,batch norm似乎几乎是为解决关键优化问题而设计的,而优化问题实际上是传播对信道分布的更改。研究已经提出的batch norm的各种替代方案,了解它们是否以及如何实现类似的功能,将是非常有趣的。这些见解还应在开发新的稳定机制方面提供指导,潜在地提供一个比另一种观望的方法更为敏锐的工具。
在结束之前,我想总结一些“元”经验。首先,可视化很重要!这个项目被卡住的时间比我想起来的要长,直到我终于咬紧咬住了重点,开发了贯穿全文的通道直方图。有了这些,就有可能可视化Hessian的特征向量,并对实际发生的事情发展出一种直觉。
其次,这是一个关于函数空间的优化器和参数化的故事——它几乎与数据集无关!在ImageNet上运行这个函数不仅会大大降低速度,而且类的数量越多,在大量的数字噪音下,就会掩盖关键问题。我预测,在基础问题上的进展将继续使用小型模型和数据集。
下一篇:回到让模型训练的更快上面

—END—
英文原文:https://myrtle.ai/how-to-train-your-resnet-7-batch-norm/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!