4-5 KNN的超参数,k\method\p
目录
超参数和模型参数
寻找最好的k
考虑距离作为投票权重的KNN---超参数weights=[uniform, distance]
曼哈顿距离和欧氏距离---超参数p,定义了计算距离的公式; 其中, p=1是曼哈顿,p=2是欧式
2. 网格搜素以及kNN中的更多超参数
网格搜索
超参数和模型参数
超参数: 在算法运行前需要决定的参数
模型参数: 算法过程中学习的参数
KNN没有模型参数
k是KNN的超参数
寻找好的超参数: 领域知识, 经验数值, 实验搜索(选实验效果最好的)
寻找最好的k
设置一个超参数的范围
注意如果超参数取在了范围的边界,应该再扩大边界进行搜索
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
print(X.shape)
print(y.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
best_score = 0.0
best_k = -1
for k in range(1, 11):
KNN_classifier = KNeighborsClassifier(n_neighbors=k)
KNN_classifier.fit(X_train, y_train)
score = KNN_classifier.score(X_test, y_test)
if score > best_score:
best_score = score
best_k = k
print(best_k)
print(best_score)
考虑距离作为投票权重的KNN
也可以解决平票的问题
best_score = 0.0
best_k = -1
best_method = " "
for method in ["uniform", "distance"]:
for k in range(1, 11):
KNN_classifier = KNeighborsClassifier(n_neighbors=k, weights=method)
KNN_classifier.fit(X_train, y_train)
score = KNN_classifier.score(X_test, y_test)
if score > best_score:
best_score = score
best_k = k
best_method = method
print(best_k)
print(best_score)
print(best_method)曼哈顿距离和欧氏距离

红紫黄三条线都是曼哈顿距离.三者相等
绿色的线是欧氏距离
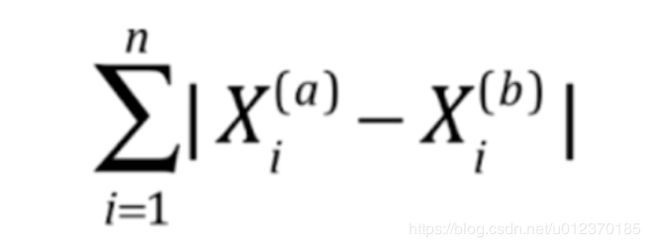
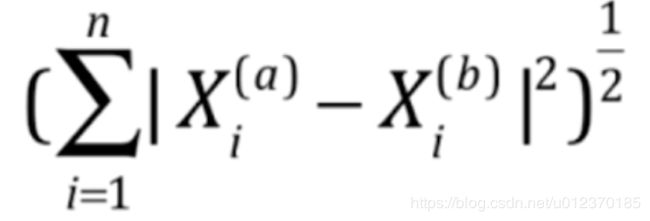
明科夫斯基距离:
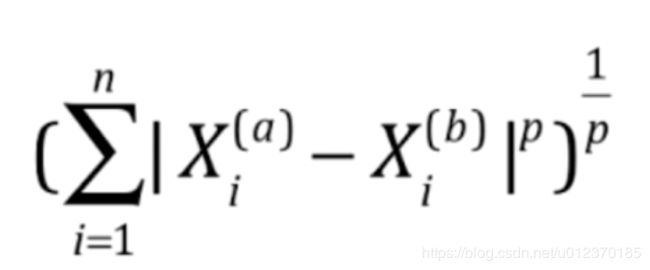
获得了新的超参数p(只有在weights = distance的情况下才有意义)
2. 网格搜素以及kNN中的更多超参数
网格搜索
(1) 定义网格,字典的形式,key: 参数名称; value: 参数的所有可能取值
(2) 定义算法
(3) 调用sklearn中的网格搜索, 传入参数---算法\网格
python中不是用户传入的参数,而是根据用户传入的参数, 类自己计算出来的结果, 对与这样的参数命名时在名字后面加下划线
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
print(X.shape)
print(y.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
# 自己写的参数搜索
# from sklearn.neighbors import KNeighborsClassifier
#
#
# best_score = 0.0
# best_k = -1
# best_method = " "
# for method in ["uniform", "distance"]:
# for k in range(1, 11):
# KNN_classifier = KNeighborsClassifier(n_neighbors=k, weights=method)
# KNN_classifier.fit(X_train, y_train)
# score = KNN_classifier.score(X_test, y_test)
# if score > best_score:
# best_score = score
# best_k = k
# best_method = method
# print(best_k)
# print(best_score)
# print(best_method)
"""sklearn中的网格搜索"""
# 定义网格
para_grid = [
{
'weights': ['uniform'],
'n_neighbors': [i for i in range(1, 11)]
},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 11)],
'p': [i for i in range(1, 6)]
}
]
# 定义算法
knn_classifier = KNeighborsClassifier()
# 网格搜索
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_classifier, para_grid, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)#对于所有的参数寻找最佳模型
print(grid_search.best_estimator_)
print(grid_search.best_score_)
print(grid_search.best_params_)
# 拿到最佳模型
knn_classifier = grid_search.best_estimator_
print(knn_classifier.score(X_test, y_test))