流处理应用开发(SequoiaDB)
实验 1
基于 SequoiaDB 的 Flink 应



Flink API 抽象级别:
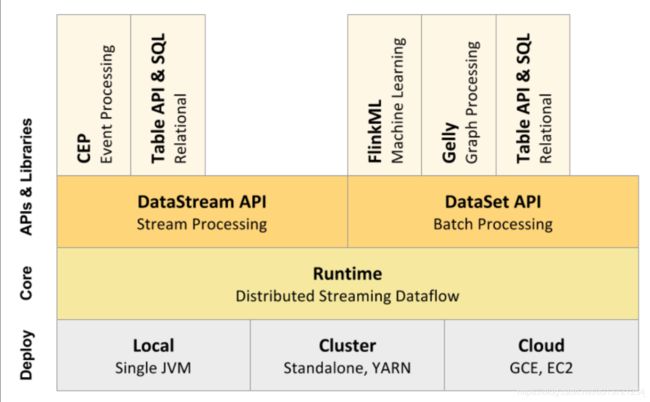
从上图中可以看到,Flink 的 Core(也称之为 Runtime )可运行在常见的资源环境中,如本地 JVM,集群和云平台中。其基础 API 可以看到分为用于流场景的 DataStream 与批场景的 DataSet,基于这两种 API,Flink 又抽象出 Table API 与 CEP 和 ML 等高级接口,本次课程只演示 DataStream API 和 Table API 的使用。
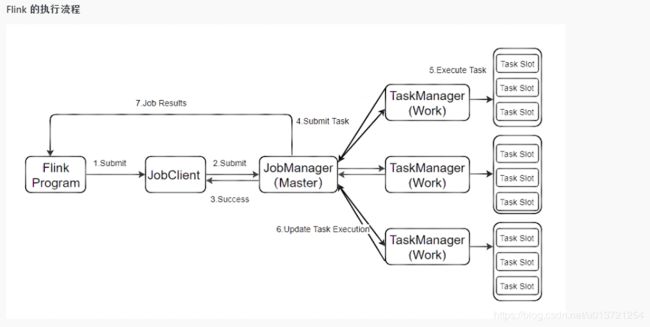

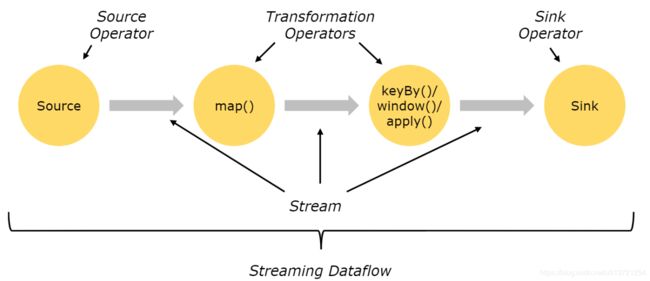
获取执行环境
一个 Flink 程序由 Source,Transformation,Sink 三部分组成。首先需要获取到 Flink 的流作业的执行环境。
// Get the execution environment
env = StreamExecutionEnvironment.getExecutionEnvironment();
使用Source获取DataStream
// Generate some random data rows through RandomSource
dataSource = env.addSource(new RandomSource());
Transformation的使用
Transformation可以对数据做转换操作,代码中的算子使用规则详见下一小节,此处仅做演示。
将数据进行切分转换之后统计每个单词出现的次数
// Conversion the operator
SingleOutputStreamOperator<String> flatMapData = lineData.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
for (String word : line.split(" ")) {
collector.collect(word);
}
}
});
// Filter the operator
SingleOutputStreamOperator<String> filterData = flatMapData.filter(s -> !s.equals("java"));
// Conversion the operator
SingleOutputStreamOperator<Tuple2<String, Integer>> mapData = filterData.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s, 1);
}
});
// Group aggregation the operator
sumData = mapData.keyBy(0).sum(1);
Sink算子的使用
sumData.print();
执行流作业
上述代码仅仅只是定义了一个流的转换逻辑,如果想让该流作业执行,还需要一个调用一个执行函数。
// The parameter is the name of the current work
env.execute("flink intro demo");
实验 2
Flink 流作业的 Java 实现

flatmap 算子的使用
flatmap 算子中需要传递一个对象,该对象有两个泛型,分别为输入数据的类型及输出数据的类型,其有一个抽象方法 flatmap,用于实现转换的具体逻辑。
该代码段将会把每个数据行按空格切分为多个单词,并向下游输出每行包含一个单词的数据行。
flatMapData = dataStream.flatMap(new FlatMapFunction<String, String>() {
/**
* Execute once on each data row and it can output multiple data
* @param s Raw data
* @param collector Output result collector, which can send multiple data out through this object
* @throws Exception
*/
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
// Divide raw data into multiple words by spaces
String[] strings = s.split(" ");
for (int i = 0; i < strings.length; i++) {
// Send each word as a new data row
collector.collect(strings[i]);
}
}
});
filter 算子的作用
filter 算子是 Transformation 的其中一种。该算子在每个数据行上被调用一次,可以帮助去除掉某些数据行,该内部实现返回一个布尔类型,当其值为 false 时当前数据行被丢弃。
filter 的使用
由于单词 “java” 与其他单词不属于同一类型,现想把数据行中 “java” 单词去掉则可以使用该算子。
将过滤掉流中值为 “java” 的数据行。
// Filter the word "java"
filterData = dataStream.filter(new FilterFunction<String>() {
/**
* Execute on each data row
* @param s Data row
* @return Return false, and the current data row is discarded
* @throws Exception
*/
@Override
public boolean filter(String s) throws Exception {
return !s.equals("java");
}
});
拓展提高(可选)
本步骤为可选,由于在 filter 算子中,输入的数据类型与输出的数据类型一致,则该算子中可以使用函数式的写法。如果有兴趣,可将 filter 函数中修改为下列代码块后重新执行当前程序。
filterData = dataStream.filter(i -> !i.equals("java"));
map 算子的作用
map 算子也是 Transformation 的其中一种。map 算子同样在每个数据行上被调用一次。值得注意的是与flatmap 算子不同,map 算子在一个数据行上的调用中仅能输出一个新的数据行,而 flatmap 可以输出多行(包含零)。
map 算子的使用
本实验中使用了一个在 Flink 中的新的数据类型,Tuple (元组)可以理解为能保存不同数据类型的列表。同时在map 算子的输出结果中添加了一个整数1,表示当前记录的单词数。
将每个数据行上的数据转换为一个 Tuple2 ,其包含一个字符串类型的单词和整数型的值,表示当前行上的单词数量
mapData = dataStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
/**
* Be called on each data row
* @param s Original data
* @return Converted data
* @throws Exception
*/
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s, 1);
}
});
keyBy 算子的作用
keyBy 算子可以通过指定 key 对数据进行分组,类似于 SQL 中的 “group by” 。值得注意的是,使用 keyBy 算子之后我们将得到一个 KeyedStream 对象,表示将无法在 keyBy 之后再次使用 keyBy。
sum算子的作用
sum 算子接收一个 KeyedStream,可以对指定的字段进行求和操作,类似 SQL中的 “sum()”函数。
实现单词数的统计
在 DataStream 的泛型为 Tuple 时,可以通过下标索引进行 keyBy 与 sum,当前实验使用第一个字段进行分组,对第二个字段进行求和。
按单词进行聚合,求和单词个数用以计算单词的出现次数。
// When the generic type of DataStream is Tuple, users can directly sum keyBy through the subscript index.
sumData = tupleData.keyBy(0).sum(1);
reduce 算子的作用
reduce 算子定义任意两个数据行合并为一个的数据行的逻辑。其内部实现 reduce 方法,该方法有两个参数,代表当前数据组内的任意两条数据,在该方法中需要定义内部每两条数据的聚合逻辑。
reduce 算子的使用
上述示例中使用了 sum 进行求和,但是如果有较为复杂的需求(如求平均值等)则必须使用 reduce 算子,此处同样使用 reduce 算子实现求和逻辑。
定义了分组之后每个数据组内,Tuple2 的第二个值相加,第一个值取其中一条数据的原始值(在相同数据组内 Tuple2.f0 实际是相同的)。
// The following code is only for demonstration. It has the same effect as the sum operator, and implementing one is fine.
sumData = keyedData.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1,
Tuple2<String, Integer> t2) throws Exception {
return Tuple2.of(t1.f0, t1.f1 + t2.f1);
}
});
实验 3
Flink 流作业 的 Scala 实现
flatmap算子的使用
flatmap 算子中需传入一个函数或 FlatmapFunction 对象,简单的操作一般传入函数。在该函数中完成数据的压扁操作,即将一个包含多个单词的数据行转换为包含一个单词的多个数据行。
// "_" means each data row
flatmapData = dataStream.flatMap(_.split(" "))
filter的使用
现在想把数据行中“java”单词去掉。
// Remove the word "java"
filterData = dataStream.filter(!_.equals("java"))
map算子的使用
本实验中使用了 Scala 中的元组类型,用一对小括号表示,可以理解为能保存不同数据类型的列表。同时在 map 算子的输出结果中添加了一个整数1,表示当前记录的单词数。
// Convert data into tuples. 1 means there is a word in the current data row.
mapData = dataStream.map((_, 1))
实现单词数的统计
在 DataStream 的泛型为元组时,可以通过下标索引进行 keyBy 与 sum,当前实验使用第一个字段进行分组,对第二个字段进行求和。
// Users can group by the first field (words) in the tuple, and sum the second field (number of words).
sumData = dataStream.keyBy(0).sum(1)
reduce 算子的使用
上述示例中使用了 sum 进行求和,但是如果有较为复杂的需求(如求平均值等)则必须使用 reduce 算子,此处同样使用 reduce 算子实现求和逻辑。
// x and y respectively represent two pieces of data. The output is the words in x, and the number is the sum of the words in x and y.
sumData = keyedData.reduce((x, y) => (x._1, x._2 + y._2))
实验 4
Flink Window API 的 Java 实现
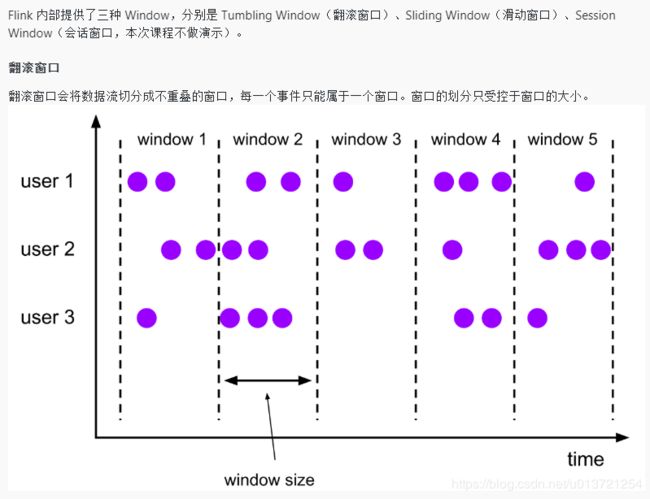
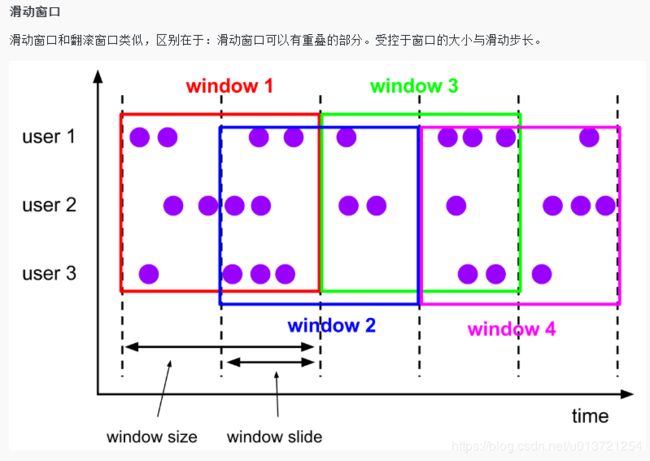
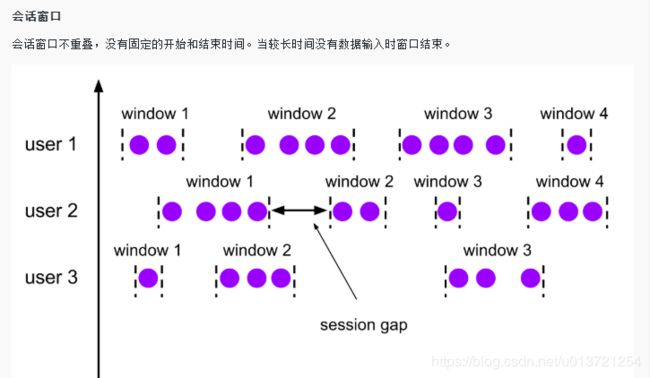
Tumbling Count Window 的实现
SequoiadbSource 的使用
SequoiadbSource 可以非常容易地从 SequoiaDB 中读取一个流。
// Build the connection Option
SequoiadbOption option = SequoiadbOption.bulider()
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("TRANSACTION_FLOW")
.build();
// Add a data source to the current environment (SequoiadbSource needs to build a stream through the time field "create_time")
sourceData = env.addSource(new SequoiadbSource(option, "create_time"));
map 算子的使用
使用 map 算子对流上的数据类型进行转换,该方法中接收一个 DataStrem,返回一个DataStream
resultData = dataStream.map(new MapFunction<BSONObject,
Tuple2<Double, Integer>>() {
/**
* Call once on each event
* @param object Original event
* @return Converted event
* @throws Exception
*/
@Override
public Tuple2<Double, Integer> map(BSONObject object) throws Exception {
// The money field in the event is extracted here. 1 means that the current event contains 1 transaction.
return Tuple2.of(((BSONDecimal) object.get("money"))
.toBigDecimal().doubleValue(), 1);
}
});
Window 划分
使用 windowAll 算子对流上数据进行分桶,此处使用翻滚计数窗口,窗口长度为100条,该算子返回一个 AllWindowedStream
resultData = dataStream.countWindowAll(100);
聚合计算
使用 reduce 对数据进行聚合求和,此处将的聚合结果为 Tuple2
resultData = dataStream.reduce(new ReduceFunction<Tuple2<Double,
Integer>>() {
/**
* Aggregation operation
* @param t1 One of the events on the stream
* @param t2 Another event on the stream
* @return Merged event
* @throws Exception
*/
@Override
public Tuple2<Double, Integer> reduce(Tuple2<Double, Integer> t1,
Tuple2<Double, Integer> t2) throws Exception {
// The total transaction amount and total transaction volume will be counted here
return Tuple2.of(t1.f0 + t2.f0, t1.f1 + t2.f1);
}
});
Tumbling Time Window 的实现

SequoiadbSource 的使用
通过 SequoiadbSource 完成 soucre 函数。
// Build the connection Option
SequoiadbOption option = SequoiadbOption.bulider()
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("TRANSACTION_FLOW")
.build();
// Add a data source to the current environment (SequoiadbSource needs to build a stream through the time field "create_time")
sourceData = env.addSource(new SequoiadbSource(option, "create_time"));
类型转换
通过 map 算子获取到交易名,交易金额,将 BSONObject 转换为 Tuple2。
resultData = dataStream.map(new MapFunction<BSONObject,
Tuple3<String, Double, Integer>>() {
/**
* Execute on every event
* @param object Original event
* @return
* @throws Exception
*/
@Override
public Tuple3<String, Double, Integer> map(BSONObject object)
throws Exception {
// Extract the required fields
return Tuple3.of(object.get("trans_name").toString(), ((BSONDecimal) object.get("money")).toBigDecimal().doubleValue(), 1);
}
});
分组
keyBy 算子通过“trans_name”进行分组,keyBy 返回一个 KeyedStream
resultData = dataStream.keyBy(new KeySelector<Tuple3<String,
Double, Integer>, String>() {
/**
* Grouping function. Use KeySelector to display the type of the grouped field
* @param t Data set before grouping
* @return Group field value
* @throws Exception
*/
@Override
public String getKey(Tuple3<String, Double, Integer> t) throws Exception {
return t.f0;
}
});
在 keyedStream 上使用 Window
本案例使用时间进行划分窗口,窗口大小为5秒。
resultData = keyedData.timeWindow(Time.seconds(5));
聚合求和
通过聚合算子求出每个时间窗口中的交易名称,总交易额,总交易量,以及每个 Window 的结束时间。
resultData = windowData.apply(new WindowFunction<Tuple3<String, Double, Integer>,
Tuple4<String, Double, Integer, java.sql.Time>, String, TimeWindow>() {
/**
* Execute once in each window
* @param key Group field value
* @param timeWindow Current window object
* @param iterable All events in the current window
* @param collector Returned result collector
* @throws Exception
*/
@Override
public void apply(String key, TimeWindow timeWindow,
Iterable<Tuple3<String, Double, Integer>> iterable,
Collector<Tuple4<String, Double, Integer,
java.sql.Time>> collector) throws Exception {
double sum = 0;
int count = 0;
Iterator<Tuple3<String, Double, Integer>> iterator =
iterable.iterator();
// Traverse all events in the current window
while (iterator.hasNext()) {
Tuple3<String, Double, Integer> next = iterator.next();
sum += next.f1;
count += next.f2;
}
// Add the end event of the Window where the event is to each event
collector.collect(Tuple4.of(key, sum, count,
new java.sql.Time(timeWindow.getEnd())));
}
});
Sliding Count Window 的实现
SequoiadbSource 的使用
通过 SequoiadbSource 完成 soucre 函数。
// Build the connection Option
SequoiadbOption option = SequoiadbOption.bulider()
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("TRANSACTION_FLOW")
.build();
// Add a data source to the current environment (SequoiadbSource needs to build a stream through the time field "create_time")
dataSource = env.addSource(new SequoiadbSource(option, "create_time"));
类型转换
通过 map 算子获取到交易名,交易金额。
resultData = transData.map(new MapFunction<BSONObject,
Tuple3<String, Double, Integer>>() {
@Override
public Tuple3<String, Double, Integer> map(BSONObject object)
throws Exception {
return Tuple3.of(object.get("trans_name").toString(),
((BSONDecimal) object.get("money")).toBigDecimal().doubleValue(), 1);
}
});
分组
keyBy 算子通过“trans_name”进行分组,keyBy 返回一个 KeyedStream
resultData = moneyData.keyBy(0);
在 keyedStream 上使用 Window
案例中使用 Sliding Count Window,窗口大小100,滑动步长50。
resultData = keyedData.countWindow(100, 50);
聚合求和
使用 reduce 对数据进行聚合求和,此处将的聚合结果为 Tuple3
resultData = countWindow.apply(new WindowFunction<Tuple3<String, Double, Integer>, Tuple2<String, Double>, Tuple, GlobalWindow>() {
/**
* Execute when the window meets the conditions, which similar to the flatMap operator
* @param tuple Group field value. Since the subscript was used for grouping, the specific data type cannot be obtained, so the Tuple abstract representation is used here.
* @param globalWindow Global window reference
* @param iterable References to all data sets in the current window
* @param collector Result collector
* @throws Exception
*/
@Override
public void apply(Tuple tuple, GlobalWindow globalWindow, Iterable<Tuple3<String, Double, Integer>> iterable,
Collector<Tuple2<String, Double>> collector) throws Exception {
double sum = 0;
Iterator<Tuple3<String, Double, Integer>> iterator = iterable.iterator();
while (iterator.hasNext()) {
sum += iterator.next().f1;
}
collector.collect(Tuple2.of(tuple.getField(0), sum));
}
});
将元组转换为 BSONObject
bsonData = dataStream.map(new MapFunction<Tuple2<String, Double>, BSONObject>() {
@Override
public BSONObject map(Tuple2<String, Double> value) throws Exception {
BasicBSONObject obj = new BasicBSONObject();
obj.append("trans_name", value.f0);
obj.append("total_sum", value.f1);
return obj;
}
});
通过 SequoiadbSink 完成 sink 函数
// Build the connection Option
SequoiadbOption option = SequoiadbOption.bulider()
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("LESSON_4_COUNT")
.build();
streamSink = dataStream.addSink(new SequoiadbSink(option));
Watermark 和 SlidingTimeWindow 的使用
本案例使用 Sliding Time Window 统计一个交易流水中每5秒中,每种交易的总交易额,总交易量。本例使用EventTime,且使用 Watermark 解决数据延迟问题。
SequoiadbSource 的使用
// Build the connection Option
SequoiadbOption option = SequoiadbOption.bulider()
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("TRANSACTION_FLOW")
.build();
// Add a data source to the current environment (SequoiadbSource needs to build a stream through the time field "create_time")
dataSource = env.addSource(new SequoiadbSource(option, "create_time"));
添加Watermark
向流中添加 Watermark。
resultData = transData.assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarks<BSONObject>() {
// Delay time (ms)
private final static int maxOutOfOrderness = 3000;
private long maxTimestamp = 0L;
/**
* Get rowtime in current data
* @param object Current data row
* @param timestamp Timestamp of the previous data
* @return Current timestamp
*/
@Override
public long extractTimestamp(BSONObject object, long timestamp) {
int currentTimestamp = ((BSONTimestamp) object.get("create_time")).getTime();
if (maxTimestamp < currentTimestamp) maxTimestamp = currentTimestamp;
return currentTimestamp;
}
/**
* Get watermark
* @return watermark object
*/
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(maxTimestamp - maxOutOfOrderness);
}
});
类型转换
通过 map 算子获取到交易名,交易金额。
resultData = transData.map(new MapFunction<BSONObject, Tuple3<String, Double, Integer>>() {
@Override
public Tuple3<String, Double, Integer> map(BSONObject object) throws Exception {
return Tuple3.of(object.get("trans_name").toString(),((BSONDecimal) object.get("money")).toBigDecimal().doubleValue(), 1);
}
});
分组
keyBy 算子通过“trans_name”进行分组,keyBy 返回一个 KeyedStream
resultData = dataStream.keyBy(new KeySelector<Tuple3<String, Double, Integer>,
String>() {
@Override
public String getKey(Tuple3<String, Double, Integer> t) throws Exception {
return t.f0;
}
});
在 keyedStream 上使用 Window
此处使用了 SlidingEventTimeWindow,窗口大小为5秒,滑动步长为2秒。
resultData = keyedStream.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(2)));
聚合求和
本例在聚合时使用了 process 算子,该算子与 apply 作用一致,区别在于 process 中可以获取到上下文对象。
resultData = windowedStream.process(new ProcessWindowFunction<Tuple3<String, Double, Integer>, Result, String, TimeWindow>() {
/**
* @param s key
* @param context Context objects,the essence of this operator
* @param iterable Event reference in current window
* @param collector Event collector
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable<Tuple3<String, Double, Integer>> iterable, Collector<Result> collector) throws Exception {
double sum = 0;
int count = 0;
Iterator<Tuple3<String, Double, Integer>> iterator = iterable.iterator();
while (iterator.hasNext()) {
Tuple3<String, Double, Integer> next = iterator.next();
count += next.f2;
sum += next.f1;
}
collector.collect(new Result(s, sum, count, new java.sql.Time(context.window().getEnd())));
}
});
将POJO转换为 BSONObject
resultData = dataStream.map(new MapFunction<Result, BSONObject>() {
@Override
public BSONObject map(Result result) throws Exception {
BasicBSONObject object = new BasicBSONObject();
object.append("count", result.getCount());
object.append("total_sum", result.getTotalSum());
object.append("trans_name", result.getTransName());
object.append("win_time", result.getWindowTime());
return object;
}
});
通过 SequoiadbSink 完成 sink 函数
SequoiadbOption option = SequoiadbOption.bulider()
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("LESSON_4_TIME")
.build();
streamSink = dataStream.addSink(new SequoiadbSink(option));
实验 5
Flink Window API 的 Scala 实现
Tumbling Count Window 的实现
本案例通过 Tumbling Count Window 统计一个交易流水中每 100次交易中的总交易额。

SequoiadbSource 的使用
SequoiadbSource 可以非常容易地从 SequoiaDB 中读取一个流。
// Build the connection Option
val option: SequoiadbOption = SequoiadbOption.bulider
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("TRANSACTION_FLOW")
.build
// Add a data source to the current environment (SequoiadbSource needs to build a stream through the time field "create_time")
resultData = env.addSource(new SequoiadbSource(option, "create_time"));
以上示例为 SequoiadbSource 的使用,需要构建一个 Option,包含巨杉数据库的连接信息。而且由于数据库中录入数据无法像消息队列做到时间态的有序,其还需要一个时间字段名用于构建流,该字段值必须是时间戳类型。
map算子的使用
使用map算子对流上的数据类型进行转换,该方法中接收一个 DataStrem[BSONObject],返回一个 DataStream[(String, Double, Int)]。
resultData = transData.map(obj => (obj.get("money"), 1))
Window划分
使用windowAll对流上数据进行分桶,此处使用翻滚计数窗口,窗口长度为100条,该算子返回一个AllWindowedStream[(Double, Integer), GlobalWindow] 对象,表示 Window 中的数据类型,以及 Window 的引用,在 CountWindow 中引用是一个全局的 Window 对象。
resultData = moneyData.countWindowAll(100)
聚合计算
使用reduce对数据进行聚合求和,此处将的聚合结果为 Tuple2
resultData = windowData.reduce((x, y) => (x._1 + y._1, x._2 + y._2))
Tumbling Time Window的实现
本案例通过 Tumbling Time Window 统计一个交易流水中每 5 秒中,每种交易的总交易额,总交易量。
 SequoiadbSource的使用
SequoiadbSource的使用
通过 SequoiadbSource 完成 source 函数。
val option: SequoiadbOption = SequoiadbOption.bulider
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("TRANSACTION_FLOW")
.build
// Add a data source to the current environment (SequoiadbSource needs to build a stream through the time field "create_time")
resultData = env.addSource(new SequoiadbSource(option, "create_time"))
类型转换
通过 map 算子获取到交易名,交易金额。
resultData = transData.map(obj => (obj.get("trans_name"), obj.get("money"), 1))
分组
keyBy算子通过元组的第一个字段(交易名 “trans_name”)进行分组,keyBy 返回一个 KeyedStream[(String, Double, Integer), String] 对象,泛型中包含数据行和一个分组字段值。
resultData = moneyData.keyBy(_._1)
在keyedStream上使用 Window
本案例使用时间进行划分窗口,窗口大小为 5 秒。
resultData = keyedData.timeWindow(Time.seconds(5))
聚合求和
通过聚合算子求出每个时间窗口中的交易名称,总交易额,总交易量,以及每个 Window 的结束时间。
resultData = value.apply(new WindowFunction[(String, Double, Int),
(String, Double, Int, java.sql.Time), String, TimeWindow] {
/**
* Execute once in each window
*
* @param key Group field value
* @param window Current window object
* @param input Iterator of all data in the current window
* @param out Returned result collector
*/
override def apply(key: String, window: TimeWindow,
input: Iterable[(String, Double, Int)],
out: Collector[(String, Double, Int, sql.Time)]): Unit = {
var sum: Double = 0
var count: Int = 0
input.foreach(item => {
sum += item._2
count += item._3
})
out.collect((key, sum, count, new java.sql.Time(window.getEnd)))
}
})
Sliding Count Window 的实现
本案例使用 Sliding Count Window 统计一个交易流水中每种交易类型中 100 次交易的总交易额。
SequoiadbSource 的使用
通过 SequoiadbSource 完成 soucre 函数。
val option: SequoiadbOption = SequoiadbOption.bulider
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("TRANSACTION_FLOW")
.build
// Add a data source to the current environment (SequoiadbSource needs to build a stream through the time field "create_time")
resultData = env.addSource(new SequoiadbSource(option, "create_time"))
类型转换
通过 map 算子获取到交易名,交易金额。
resultData = value.map(obj => Trans(obj.get("trans_name"), obj.get("money"), 1))
分组
keyBy 算子通过“trans_name”进行分组,keyBy 返回一个 KeyedStream
resultData = value.keyBy("name")
在keyedStream上使用 Window
案例中使用 Sliding Count Window,窗口大小 100,滑动步长 50。
resultData = value.countWindow(100, 50)
聚合求和
使用 reduce 对数据进行聚合求和,此处将的聚合结果为 Tuple3
resultData = value.apply(new WindowFunction[Trans, (String, Double),
Tuple, GlobalWindow] {
/**
* Execute when the window meets the conditions
* @param key Group field
* @param window Global window reference
* @param input References to all data sets in the current window
* @param out Result collector
*/
override def apply(key: Tuple, window: GlobalWindow, input: Iterable[Trans],
out: Collector[(String, Double)]): Unit = {
var sum: Double = 0
input.foreach(sum += _.money)
out.collect((key.getField[String](0), sum))
}
})
将元组转换为 BSONObject
resultData = value.map(item => {
val nObject = new BasicBSONObject
nObject.append("trans_name", item._1)
nObject.append("total_sum", item._2)
nObject
})
通过 SequoiadbSink 完成 sink 函数
// Build the connection Option
val option = SequoiadbOption.bulider
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("LESSON_5_COUNT")
.build
streamSink = value.addSink(new SequoiadbSink(option))
Watermark 和 SlidingTimeWindow 的使用
equoiadbSource 的使用
通过 SequoiadbSource 完成 soucre 函数。
val option: SequoiadbOption = SequoiadbOption.bulider
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("TRANSACTION_FLOW")
.build
// Add a data source to the current environment (SequoiadbSource needs to build a stream through the time field "create_time")
resultData = env.addSource(new SequoiadbSource(option, "create_time"))
添加 Watermark
向流中添加 Watermark。
resultData = value.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[BSONObject] {
// Maximum out-of-order time
private val maxOutOfOrderness: Long = 5000
private var maxTimestamp: Long = 0
/**
* Return a watermark
*
* @return
*/
override def getCurrentWatermark: Watermark = {
new Watermark(maxTimestamp - maxOutOfOrderness)
}
/**
* Extract the timestamp of the current data
*
* @param t Current data
* @param l Timestamp of the previous data
* @return Timestamp of the current data
*/
override def extractTimestamp(t: BSONObject, l: Long): Long = {
val currentTimestamp: Long = t.get("create_time")
.asInstanceOf[BSONTimestamp].getTime
maxTimestamp = if (maxTimestamp > currentTimestamp) maxTimestamp
else currentTimestamp
currentTimestamp
}
})
类型转换
通过 map 算子获取到交易名,交易金额。
resultData = value.map(obj => (obj.get("trans_name"), obj.get("money"), 1))
分组
keyBy 算子通过“trans_name”进行分组,keyBy 返回一个 KeyedStream[(String, Double, Int), String] 对象,泛型中包含数据行和一个 Tuple 类型的分组字段值。
resultData = value.keyBy(_._1)
在 keyedStream 上使用Window
resultData = value.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(2)))
聚合求和
resultData = value.process(new ProcessWindowFunction[(String, Double, Int),
BSONObject, String, TimeWindow] {
/**
* window Aggregation method, call once per window
* @param key Group field value
* @param context Context objects, the essence of this operator
* @param elements Event reference in current window
* @param out Event collector
*/
override def process(key: String, context: Context,
elements: Iterable[(String, Double, Int)],
out: Collector[BSONObject]): Unit = {
var sum: Double = 0
var count: Int = 0
elements.foreach(i => {
sum += i._2
count += i._3
})
// Construct a BsonObject object
val nObject = new BasicBSONObject
nObject.append("trans_name", key)
nObject.append("total_sum", sum)
nObject.append("count", count)
out.collect(nObject)
}
})
通过 SequoiadbSink 完成 sink 函数
val option = SequoiadbOption.bulider
.host("localhost:11810")
.username("sdbadmin")
.password("sdbadmin")
.collectionSpaceName("VIRTUAL_BANK")
.collectionName("LESSON_5_TIME")
.build
value.addSink(new SequoiadbSink(option))
实验 6
Flink Table API 与 SQL

DataStream 与表的转换
本例使用 Flink Table 实现 word count。演示从 DataStream转换 Table,经中间转换过程后将在 Table 转换为DataStream,最后输出结果到控制台。

从已有的 DataStream 中创建 Table
本案例中已存在一个 DataStream
table = tbEnv.fromDataStream(wordData, "name, num");
SQL 算子的使用
SQL 算子的用途与标准sql中关键字一致。
/**
* Equivalent to sql
* select word, sum(num)
* from
* ( select name as word, num
* from "current table" )
* where word != 'java'
* group by word
*/
resultTable = initTable.as("word, num") // Rename field
.where("word != 'java'") // where operator filtering
.groupBy("word") // Aggregate by groupby
.select("word, sum(num)"); // Sum
Table转换为DataStream

dataStream = tbEnv.toRetractStream(table, TypeInformation.of(
new TypeHint<Tuple2<String, Integer>>() {}));
通过表描述器注册表
通过描述器创建一个 Source 表
tbEnv.connect(
new Sdb()
.version("3.4") // Version of sdb
.hosts("localhost:11810") // Connection address of sdb
.username("sdbadmin") // Username
.password("sdbadmin") // Password
.collectionSpace("VIRTUAL_BANK") // CollectionSpace
.collection("TRANSACTION_FLOW") // Collection
.timestampField("create_time") // Stream Timestamp field
).withFormat(
new Bson() // Use Bson data format
.deriveSchema() // Map data fields with the same name automatically
.failOnMissingField() // When a field value cannot be obtained, the task fails
).withSchema(
new Schema() // Define the structure of the table
.field("account", Types.STRING) // Account
.field("trans_name", Types.STRING) // Transaction name
.field("money", Types.BIG_DEC) // Transaction amount
.field("create_time", Types.SQL_TIMESTAMP) // Transaction hour
).inAppendMode()
.registerTableSource("TRANSACTION_FLOW"); // Register as a data source table
通过描述器创建一个 Sink 表
tbEnv.connect(
new Sdb()
.version("3.4") // Version of sdb
.hosts("localhost:11810") // Connection address of sdb
.username("sdbadmin") // Username
.password("sdbadmin") // Password
.collectionSpace("VIRTUAL_BANK") // CollectionSpace
.collection("LESSON_6_CONNECT") // Collection
).withFormat(
new Bson() // Use Bson data format
.deriveSchema() // Map data fields with the same name automatically
.failOnMissingField() // When a field value cannot be obtained, the task fails
).withSchema(
new Schema() // Define the structure of the table
.field("total_sum", Types.BIG_DEC)
.field("trans_name", Types.STRING)
).inUpsertMode()
.registerTableSink("LESSON_6_CONNECT"); // Register as a data source table
编写统计 SQL
编写 sql 统计结果并将结果输出到巨杉数据库,统计每种交易的交易总额。
tbEnv.sqlUpdate(
"INSERT INTO LESSON_6_CONNECT " +
"SELECT " +
"SUM(money) AS `total_sum`, " +
"trans_name " +
"FROM TRANSACTION_FLOW " +
"GROUP BY " +
"trans_name");
通过 DDL 创建表
创建 Source 表
通过 DDL 创建 Flink Source 表。
tbEnv.sqlUpdate(
"CREATE TABLE TRANSACTION_FLOW (" +
" account STRING, " + // Account number
" trans_name STRING, " + // Name of transaction
" money DECIMAL(10, 2), " + // Transaction amount
" create_time TIMESTAMP(3)" + // Transaction time
") WITH (" +
" 'connector.type' = 'sequoiadb', " + // Connection media type
" 'connector.version' = '3.4', " + // Version of SequoiaDB
" 'connector.hosts' = 'localhost:11810', " + // Connection address
" 'connector.username' = 'sdbadmin', " + // Username
" 'connector.password' = 'sdbadmin', " + // Password
" 'connector.collection-space' = 'VIRTUAL_BANK', " + // CollectionSpace
" 'connector.collection' = 'TRANSACTION_FLOW', " + // CollectionName
" 'connector.timestamp-field' = 'create_time', " + // Stream Timestamp field
" 'format.type' = 'bson', " + // Data type bson
" 'format.derive-schema' = 'true', " + // Map data fields with the same name automatically
" 'format.fail-on-missing-field' = 'true', " + // When a field cannot be obtained, the task fails
" 'update-mode' = 'append'" + // append mode
")");
创建 Sink 表
tbEnv.sqlUpdate(
"CREATE TABLE LESSON_6_DDL (" +
" trans_name STRING, " + // Transaction name
" `total_sum` DECIMAL(10, 2)" + // Transaction sum
") WITH (" +
" 'connector.type' = 'sequoiadb', " +
" 'connector.version' = '3.4', " + // Version of SequoiaDB
" 'connector.hosts' = 'localhost:11810', " +
" 'connector.username' = 'sdbadmin', " +
" 'connector.password' = 'sdbadmin', " +
" 'connector.collection-space' = 'VIRTUAL_BANK', " +
" 'connector.collection' = 'LESSON_6_DDL', " +
" 'format.type' = 'bson', " +
" 'format.derive-schema' = 'true', " +
" 'format.fail-on-missing-field' = 'true', " +
" 'update-mode' = 'upsert'" + // upsert mode, which can execute aggregate statements
")");
编写查询 SQL
执行统计,统计每种交易的交易总额。
tbEnv.sqlUpdate(
"INSERT INTO LESSON_6_DDL " +
"SELECT " +
"trans_name, " +
"SUM(money) AS `total_sum` " +
"FROM TRANSACTION_FLOW " +
"GROUP BY " +
"trans_name");
Table API 中 Watermark 与 Window 的使用
使用描述器中定义一个使用 EventTime 和 Watermark
// Connection table via descriptor
tbEnv.connect(
new Sdb()
.version("3.4") // Version of sdb
.hosts("localhost:11810") // Connection address of sdb
.username("sdbadmin") // Username
.password("sdbadmin") // Password
.collectionSpace("VIRTUAL_BANK") // CollectionSpace
.collection("TRANSACTION_FLOW") // Collection
.timestampField("create_time") // Stream Timestamp field
).withFormat(
new Bson() // Use Bson data format, when using rowtime, users must display the specified format
.bsonSchema( // Bson serializer allows BsonFormat to be represented using a json string
"{" +
"account: 'string', " +
"trans_name: 'string', " +
"money: 'decimal', " +
"create_time: 'timestamp'" +
"}")
.failOnMissingField() // Exception thrown when a field value cannot be obtained
).withSchema(
new Schema() // Define the structure of the table
.field("account", Types.STRING) // Account
.field("trans_name", Types.STRING) // Transaction name, for example: interest settlement, withdrawal, and etc.
.field("money", Types.BIG_DEC) // Transaction amount
.field("create_time", Types.SQL_TIMESTAMP) // Transaction time
.field("rowtime", Types.SQL_TIMESTAMP) // EventTime field
.rowtime(
new Rowtime()
.timestampsFromField("create_time") // Extract timestamp from field
.watermarksPeriodicAscending() // Set watermark generation rules
)
).inAppendMode()
.registerTableSource("TRANSACTION_FLOW");

编写 SQL
执行统计,统计每种交易的交易总额。
// Execute sql data statistics
tbEnv.sqlUpdate(
"INSERT INTO LESSON_6_SQL ( " +
"SELECT " +
"trans_name, " +
"SUM(money) AS total_sum, " +
"TUMBLE_END(`rowtime`, INTERVAL '5' SECOND) as `timestamp`, " +
"DATA_FORMAT(TUMBLE_END(`rowtime`, INTERVAL '5' SECOND), " +
"'HH:mm:ss') AS win_time " +
"FROM TRANSACTION_FLOW " +
"GROUP BY " +
"TUMBLE(`rowtime`, INTERVAL '5' SECOND), " +
"trans_name )"
);
实验 7
交易统计分析案例
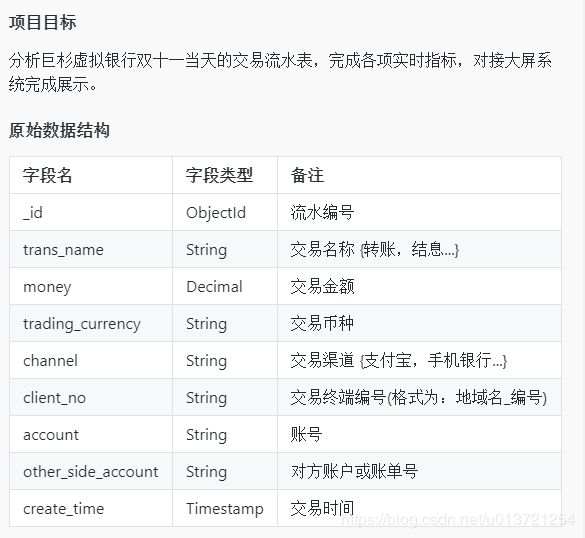



执行查询
在实验环境中,流水表名为 TRANSACTION_FLOW,需求一的结果需要写入到集合 COUNT。
tbEnv.sqlUpdate(
"INSERT INTO `COUNT` " +
"SELECT " +
"SUM(money) AS sum_money, " +
"COUNT(1) AS num_trans, " +
"COUNT(DISTINCT SPLIT_INDEX(client_no, '_', 0)) AS num_active_area, " +
"DIVISION( COUNT(1), (MAX(EXTRACT_TIME(rowtime)) - MIN(EXTRACT_TIME(rowtime))) / 60) AS frequency_trans " +
"FROM TRANSACTION_FLOW");
流作业的编写-需求二

执行查询
在实验环境中,流水表名为 TRANSACTION_FLOW,需求二的结果需要写入到集合 MAP。
tbEnv.sqlUpdate(
"INSERT INTO `MAP` " +
"SELECT " +
"COUNT(1) AS num_trans, " +
"SPLIT_INDEX(client_no, '_', 0) AS area_name " +
"FROM TRANSACTION_FLOW " +
"GROUP BY " +
"SPLIT_INDEX(client_no, '_', 0)");
流作业的编写-需求三
 执行查询
执行查询
tbEnv.sqlUpdate(
"INSERT INTO `PIE` " +
"SELECT " +
"COUNT(1) AS num_trans, " +
"channel " +
"FROM TRANSACTION_FLOW " +
"GROUP BY " +
"channel");
流作业的编写-需求四


执行查询
tbEnv.sqlUpdate(
"INSERT INTO `LINE` " +
"SELECT " +
"SUM(money) as sum_money, " +
"COUNT(1) AS num_trans, " +
"TUMBLE_END(`rowtime`, INTERVAL '1' MINUTE) AS `timestamp`, " +
"DATA_FORMAT(TUMBLE_END(`rowtime`, INTERVAL '1' MINUTE), " +
"'HH:mm:ss') AS format_time " +
"FROM TRANSACTION_FLOW " +
"GROUP BY " +
"TUMBLE(rowtime, INTERVAL '1' MINUTE)");