Spark 3.0 中七个必须知道的 SQL 性能优化
本文来自 IBM 东京研究院的高级技术人员 Kazuaki Ishizaki 博士在 Spark Summit North America 2020 的 《SQL Performance Improvements at a Glance in Apache Spark 3.0》议题的分享,本文视频参见今天的推文第三条。PPT 请关注过往记忆大数据并后台回复 sparksql3 获取。
Spark 3.0 正式版在上个月已经发布了,其中更新了很多功能,参见过往记忆大数据的 Apache Spark 3.0.0 正式版终于发布了,重要特性全面解析。本文将介绍 Spark 3.0 在 SQL 方面的优化。

SQL 方面的优化主要包括四个方向:
面向开发者交互方面;
动态优化;
Catalyst 方面的提升;
基础设施的更新。

我们在早期的文章也说了 Spark 3.0 一共处理了 3464 个 ISSUES!这么多的 ISSUES 我们很难一一都过一遍,所以这个 session Kazuaki Ishizaki 博士给我们过一下 SQL 方面的提升。

SQL 方面的提升主要包括七个方面:
EXPLAIN 新的格式;
所有的 Join 都支持 hints;
自适应查询执行;
动态分区裁剪;
增强嵌套列的裁剪和下推;
增强聚合的代码生成;
支持新的 Scala 和 Java 版本。
EXPLAIN 新的格式

如果想提升查询性能,我们需要理解一个查询是怎么优化的,首先就需要理解查询计划这些。假设我们有一个如下的查询:
SELECT key, Max(val)
FROM temp
WHERE key > 0
GROUP BY key
HAVING max(val) > 0
我们来看下 Spark 2.4 和 Spark 3.0 对这条 SQL 的查询计划都是怎么样的。

如果在 Spark 2.4 上使用 EXLPAIN 来查看查询计划,可以看到,输出太长了!!因为每行都有很多不必要的 Attribute。我们很难一眼就看出这个是干嘛的。

Spark 3.0 在 EXPLAIN 的基础上加了 FORMATTED 的支持,以非常简洁的格式展现出详细的信息,这个输出主要包含两部分。
第一部主要是一系列的算子;
第二部分是一系列的 Attribute
上面的输出我们一眼就可以看出 Spark SQL 如何处理这个查询,如果你想看比较详细的信息,比如输出输出,那你可以看第二部分的 Attribute。
所有的 Join 都支持 hints

SQL 的第二个优化是 Join Type Hint。
在 Spark 2.4,我们只能对 Broadcast 进行 Hint 提示,其他类型的 Join 是不支持的。到了 Spark 3.0,所有类型的 Join 都支持 Hint 提示。我们既可以在 SQL 中直接使用 hint,也可以在 DSL 中使用。这个在 Spark 选择的 Join 策略不是我们想要的时候非常有用。
自适应查询执行

第三个优化是自适应查询优化。
通过运行统计信息,实现三方面的优化:
自动设置好比较合理的 Reduce 个数;
选择更好的 Join 策略来提升性能;
优化倾斜 Join 中的数据。
这些优化完全不用手动去调优。在 TPC-DS 的 Q77 查询中,性能提升了8倍。

上面是 2.4 中 SQL 的运行情况,如果有 5 个 reduce 分别处理 5个分区,可以看到,Reduce0 可以很快就完成,因为其数据很少;其次就是 Reduce 4;最慢的是 Reduce 3,这就导致这个 SQL 查询的时间消耗主要花在 Reduce 3 上,而其他 CPU 却处于空闲状态!
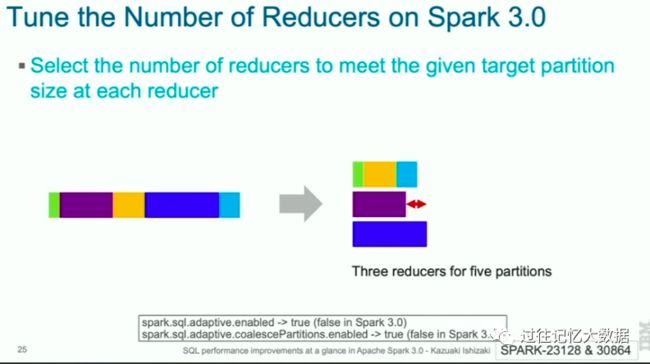
Spark 3.0 的话会自动选择合适的 Reduce 个数,这样就可没有 Redue 处于空闲。
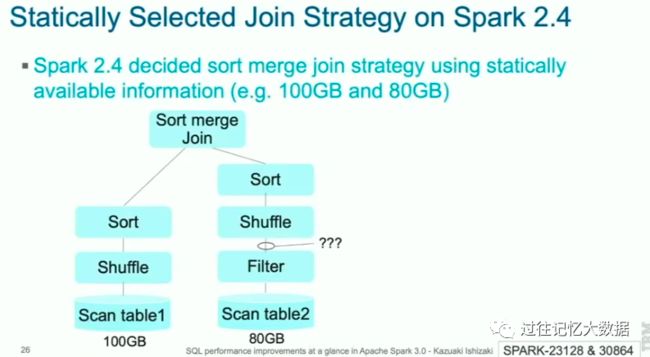
Spark 2.4 选择 Join 策略的时候根据静态的统计信息的,比如上面的 table1 和 table2 的静态统计大小分别为 100GB 和 80GB,所以上面的 Join 采用 Sort merge Join。
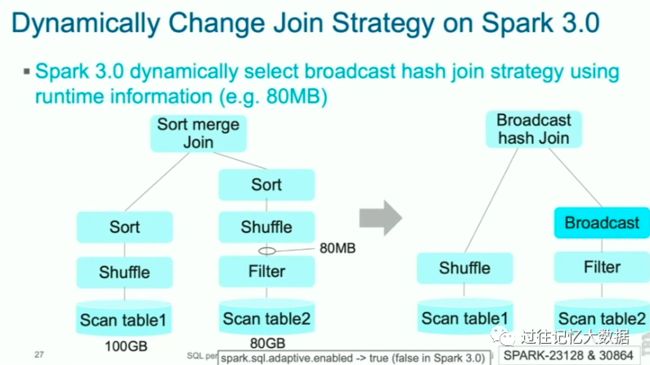
而 Spark 3.0 根据运行时的统计信息,得知这个 Join 应该选择 broadcast Join。
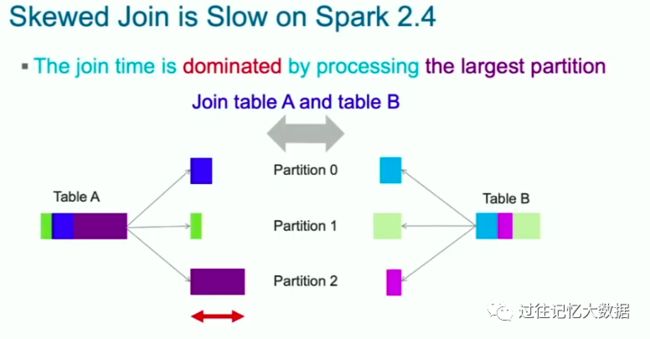
两张表的 Join 耗时取决于最大分区的耗时。所以如果 Join 的过程中有一个分区出现数据倾斜,处理时间可想而知。
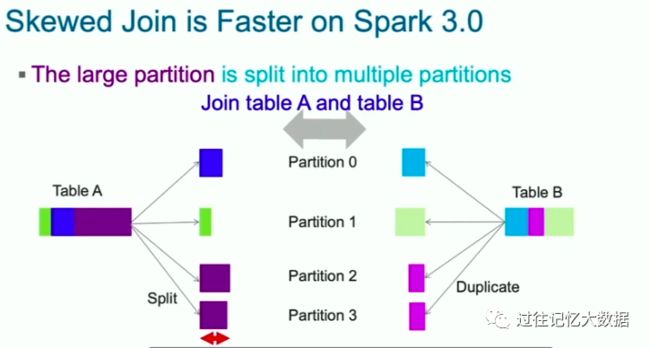
Spark 3.0 的自适应执行可以将倾斜的分区进行拆分。从而达到一个比较可观的运行时间。关于Spark 3.0 的自适应执行可以参见过往记忆大数据的 Spark 3.0 自适应查询优化介绍,在运行时加速 Spark SQL 的执行性能 这篇文章。
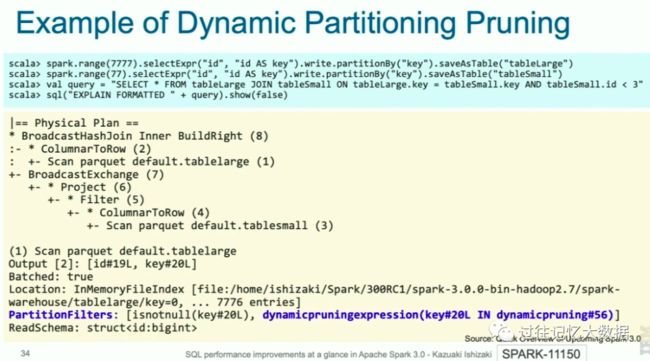
动态分区裁剪

第四个优化是动态分区裁剪。这个可以参见 一文了解 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning)以及 一文了解 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning)的使用。这里我就不再介绍了。下面是动态分区裁剪的例子
增强嵌套列的裁剪和下推
第五个优化是嵌套列的优化。

Spark 2.4 支持对 Parquet 中的嵌套列进行优化,只读取需要的部分,但是这个功能很有限。比如 Repartition 就不支持嵌套列的裁剪,它需要将整个列进行 repartition,然后才选择需要的部分。
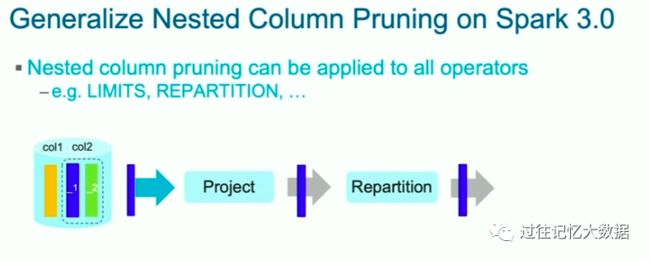
Spark 3.0 优化了这部分,使得嵌套列的裁剪支持所有的算子,包括上面的 repartition,大大减少了 IO,因为我们减少了数据的读取。下面就是一个嵌套列裁剪的例子:


Spark 2.4 对嵌套列(Parquet 和 ORC)不支持下推,需要读取所有的数据,然后再进行 Filter 操作。

Spark 优化了这部分,现在对 Parquet 和 ORC 的嵌套列都支持过滤下推。
增强聚合的代码生成
第六个优化是增强聚合的代码生成

Spark 2.4 的复杂聚合非常慢,这是因为 Spark 2.4 的复杂查询没有编译成本地代码。所以你在跑 TPC-DS 的时候会发现 Q66很慢。
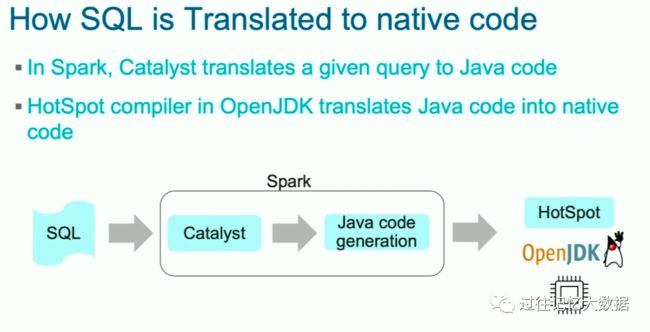
在 Spark 中,Catalyst 负责将查询翻译成 Java 代码。OpenJDK 中的 HotSpot 编译器负责将 Java 代码翻译成本地代码。
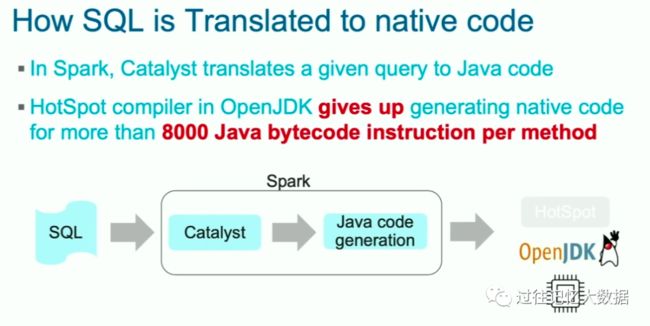
但是方法中的指令超过 8000 Java 字节码的时候,HotSpot 编译器放弃将 Java 代码翻译成本地代码。

Spark 3.0 的 Catalyst 通过将聚合的逻辑拆分成多个小的方法,使得 HotSpot 编译器可以将他转换成本地代码,这样查询性能比 2.4 快不少。下面就是一个例子;
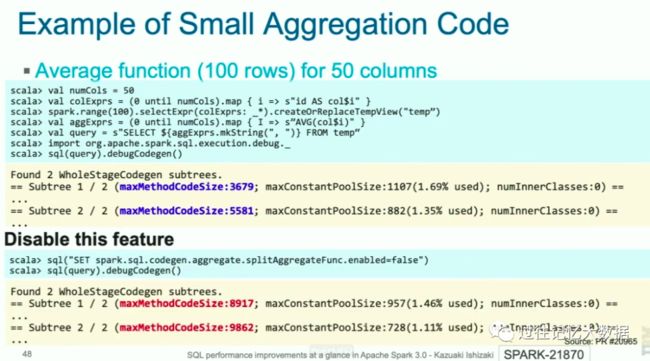
上图的上部分是使用 Spark 3.0,您可以看到最大的方法大小都小于8000,而下图是关闭这个功能,最大的方法大小已经超过了8000。
支持新的 Scala 和 Java 版本

猜你喜欢
1、Spark 背后的商业公司收购的 Redash 是个啥?
2、马铁大神的 Apache Spark 十年回顾
3、YARN 在字节跳动的优化与实践
4、Apache Spark 3.0.0 正式版终于发布了,重要特性全面解析

过往记忆大数据微信群,请添加微信:fangzhen0219,备注【进群】