准备工作
首先,需要在Face++的主页注册一个账号,在控制台去获取API Key和API Secret。
然后在本地文件夹准备好要进行情绪识别的图片/相片。
代码
介绍下所使用的第三方库
——urllib2是使用各种协议完成打开url的一个库
——time是对时间进行处理的一个库,以下代码中其实就使用了sleep()和localtime()两个函数,sleep()是用来让程序暂停几秒的,localtime()是格式化时间戳为本地的时间
——xlwt是对excel进行写入操作的一个库
——os是操作系统的相关功能的一个库,例如用来处理文件和目录之类的
——json (Emmmmmm……我也不知道该怎么解释这个)
——PIL是Python图像处理库
1 # -*- coding: utf-8 -*- 2 # version:python2.7.13 3 # author:Ivy Wong 4 5 # 导入相关模块 6 import urllib2 7 import time, xlwt, os,json 8 from PIL import Image 9 10 # 使用face++的api识别情绪 11 def useapi(img): 12 http_url = 'https://api-cn.faceplusplus.com/facepp/v3/detect' 13 boundary = '----------%s' % hex(int(time.time() * 1000)) 14 data = [] 15 data.append('--%s' % boundary) 16 data.append('Content-Disposition: form-data; name="%s"\r\n' % 'api_key') 17 data.append(key) 18 data.append('--%s' % boundary) 19 data.append('Content-Disposition: form-data; name="%s"\r\n' % 'api_secret') 20 data.append(secret) 21 data.append('--%s' % boundary) 22 fr = open(img, 'rb') 23 data.append('Content-Disposition: form-data; name="%s"; filename=" "' % 'image_file') 24 data.append('Content-Type: %s\r\n' % 'application/octet-stream') 25 data.append(fr.read()) 26 fr.close() 27 data.append('1') 28 data.append('--%s' % boundary) 29 data.append('Content-Disposition: form-data; name="%s"\r\n' % 'return_attributes') 30 data.append("gender,age,emotion,ethnicity")# 这里可以还可以返回其他参数,具体可以参看face++的api文档 31 data.append('--%s--\r\n' % boundary) 32 33 http_body = '\r\n'.join(data) 34 # build http request 35 req = urllib2.Request(http_url) 36 # header 37 req.add_header('Content-Type', 'multipart/form-data; boundary=%s' % boundary) 38 req.add_data(http_body) 39 try: 40 resp = urllib2.urlopen(req,timeout=5) 41 qrcont = json.load(resp) 42 except urllib2.HTTPError as e: 43 print e.read() 44 return qrcont 45 46 47 # 将json字典写入excel 48 # 变量用来循环时控制写入单元格,感觉这种方式有点傻,但暂时想不到优化方法 49 def writeexcel(img, worksheet, row, files_name): 50 parsed = useapi(img) 51 if not parsed['faces']: 52 print 'This picture do not have any face' 53 else: 54 if len(parsed['faces'])<=5: # 由于免费API限制,只能返回5张人脸信息 55 for list_item in parsed['faces']: 56 # 写入文件名 57 filename, extension = os.path.splitext(files_name) 58 worksheet.write(row, 0, filename) 59 60 # 写入时间戳 61 daystamp, timestamp, hourstamp = gettimestamp(img) 62 worksheet.write(row, 1, label=daystamp) 63 worksheet.write(row, 2, label=timestamp) 64 worksheet.write(row, 3, hourstamp) 65 66 # 写入api返回的数据 67 emotion = [] 68 for key1, value1 in list_item.items(): 69 if key1 == 'attributes': 70 for key2, value2 in value1.items(): 71 if key2 == 'age': 72 worksheet.write(row, 5, value2['value']) 73 elif key2 == 'emotion': 74 for key3, value3 in value2.items(): 75 if key3 == 'sadness': 76 worksheet.write(row, 8, value3) 77 emotion.append(value3) 78 elif key3 == 'neutral': 79 worksheet.write(row, 9, value3) 80 emotion.append(value3) 81 elif key3 == 'disgust': 82 worksheet.write(row, 10, value3) 83 emotion.append(value3) 84 elif key3 == 'anger': 85 worksheet.write(row, 11, value3) 86 emotion.append(value3) 87 elif key3 == 'surprise': 88 worksheet.write(row, 12, value3) 89 emotion.append(value3) 90 elif key3 == 'fear': 91 worksheet.write(row, 13, value3) 92 emotion.append(value3) 93 else: 94 worksheet.write(row, 14, value3) 95 emotion.append(value3) 96 elif key2 == 'gender': 97 worksheet.write(row, 6, value2['value']) 98 elif key2 == 'ethnicity': 99 worksheet.write(row, 7, value2['value']) 100 else: 101 pass 102 elif key1 == 'face_token': 103 worksheet.write(row, 4, value1) 104 else: 105 pass 106 worksheet.write(row, 15, emotion.index(max(emotion))) 107 108 # 写入概率最大的情绪,0-neutral,1-sadness,2-disgust,3-anger,4-surprise,5-fear,6-happiness 109 row += 1 110 else: 111 for list_item in parsed['faces'][0:5]: 112 # 写入文件名 113 filename, extension = os.path.splitext(files_name) 114 worksheet.write(row, 0, filename) 115 116 # 写入时间戳 117 daystamp, timestamp, hourstamp = gettimestamp(img) 118 worksheet.write(row, 1, label=daystamp) 119 worksheet.write(row, 2, label=timestamp) 120 worksheet.write(row, 3, hourstamp) 121 122 # 写入api返回的数据 123 emotion = [] 124 for key1, value1 in list_item.items(): 125 if key1 == 'attributes': 126 for key2, value2 in value1.items(): 127 if key2 == 'age': 128 worksheet.write(row, 5, value2['value']) 129 elif key2 == 'emotion': 130 for key3, value3 in value2.items(): 131 if key3 == 'sadness': 132 worksheet.write(row, 8, value3) 133 emotion.append(value3) 134 print '1' 135 elif key3 == 'neutral': 136 worksheet.write(row, 9, value3) 137 emotion.append(value3) 138 print '2' 139 elif key3 == 'disgust': 140 worksheet.write(row, 10, value3) 141 emotion.append(value3) 142 print '3' 143 elif key3 == 'anger': 144 worksheet.write(row, 11, value3) 145 emotion.append(value3) 146 print '4' 147 elif key3 == 'surprise': 148 worksheet.write(row, 12, value3) 149 emotion.append(value3) 150 print '5' 151 elif key3 == 'fear': 152 worksheet.write(row, 13, value3) 153 emotion.append(value3) 154 print '6' 155 else: 156 worksheet.write(row, 14, value3) 157 emotion.append(value3) 158 print '7' 159 elif key2 == 'gender': 160 worksheet.write(row, 6, value2['value']) 161 elif key2 == 'ethnicity': 162 worksheet.write(row, 7, value2['value']) 163 else: 164 pass 165 elif key1 == 'face_token': 166 worksheet.write(row, 4, value1) 167 else: 168 pass 169 worksheet.write(row, 15, emotion.index(max(emotion))) 170 # 写入概率最大的情绪,0-neutral,1-sadness,2-disgust,3-anger,4-surprise,5-fear,6-happiness 171 row += 1 172 print 'Success! The pic ' + str(files_name) + ' was detected!' 173 174 return row, worksheet 175 176 # 获取图片大小 177 def imagesize(img): 178 Img = Image.open(img) 179 w, h = Img.size 180 return w,h 181 182 # 获取时间戳 183 def gettimestamp(path): 184 statinfo = os.stat(path) 185 timeinfo = time.localtime(statinfo.st_ctime) 186 daystamp = str(timeinfo.tm_year) + '-' + str(timeinfo.tm_mon) + '-' + str(timeinfo.tm_mday) 187 timestamp = str(timeinfo.tm_hour) + ':' + str(timeinfo.tm_min) + ':' + str(timeinfo.tm_sec) 188 hourstamp = timeinfo.tm_hour + timeinfo.tm_min / 60.0 + timeinfo.tm_sec / 3600.0 189 return daystamp, timestamp, hourstamp 190 191 192 key = "your_key" 193 secret = "your_secret" 194 path = r"图片文件夹路径" 195 # 注意:由于我是对同一文件夹下的多个文件夹中的图片进行识别,所以这个path是图片所在文件夹的上一级文件夹。文件夹名尽量使用英文与数字,不然可能因为编码问题报错 196 197 # 创建excel 198 workbook = xlwt.Workbook(encoding='utf-8') 199 200 for root, dirs, files in os.walk(path, topdown=False): 201 for folder in dirs: 202 print 'Let us start dealing with folder ' + folder 203 204 # 创建一个新的sheet 205 worksheet = workbook.add_sheet(folder) 206 # 设置表头 207 title = ['PhotoID', 'daystamp', 'timestamp', 'hourstamp','faceID', 'age', 'gender', 'ethnicity', 'sadness', 208 'neutral','disgust', 'anger', 'surprise', 'fear', 'happiness', 'emotion'] 209 for col in range(len(title)): 210 worksheet.write(0, col, title[col]) 211 212 # 遍历每个folder里的图片 213 row = 1 214 for root2, dirs2, files2 in os.walk(path + '\\' + folder): 215 for files_name in files2: 216 img = path + '\\' + folder + '\\' + files_name 217 try: 218 print 'Now, the program is going to deal with ' + folder + ' pic' + str(files_name) 219 w,h=imagesize(img) 220 if w<48 or h<48 or w>4096 or h>4096:#API对图片大小的限制 221 print 'invalid image size' 222 else: 223 row, worksheet = writeexcel(img, worksheet, row, files_name) 224 225 except: 226 print '超过了并发数!等一下!' 227 time.sleep(3) 228 print 'The program is going to work' 229 print 'Now, the program is going to deal with ' + folder + ' pic' + str(files_name) 230 row, worksheet = writeexcel(img, worksheet, row, files_name) 231 232 233 workbook.save('detactface_facepp_flickr.xls') 234 print 'The current folder is done.' 235 236 # 保存文件 237 workbook.save('detectface.xls') 238 print 'All done!'
成果
最后生成的excel大概是这个样子。
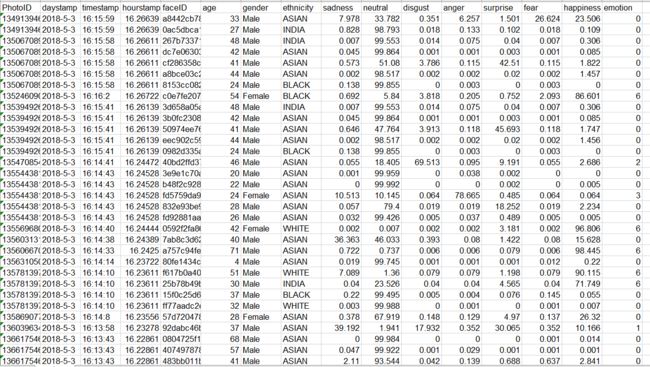
其中emotion就是概率最大的情绪,0-neutral,1-sadness,2-disgust,3-anger,4-surprise,5-fear,6-happiness。
探讨
在我自己运行过程中发现了一个问题,由于使用的是免费API,有并发限制,多次超过并发数,urlopen就会返回403。于是try失败,运行except,return时无定义的qrcont而报错。
1 try: 2 resp = urllib2.urlopen(req,timeout=5) 3 qrcont = json.load(resp) 4 except urllib2.HTTPError as e: 5 print e.read() 6 return qrcont
这就非常尴尬了,所以目前基本上都是大晚上在用这个代码跑……不知看到的各位有何高见?