机器学习是一门多学科交叉专业,涵盖概率论知识、统计学知识、近似理论知识和复杂算法知识。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。通过计算机对数据的处理和对算法的运用,实现对业务场景的深度分析,帮助人们更好的做决策。永洪深度分析模块是将机器学习算法封装成节点,用户通过拖拽的方式从而便捷的应用机器学习算法。
如何使用深度分析模块?首先需要安装永洪Desktop,里面会带有深度分析功能,目前可以免费试用3个月。其次根据需要安装R服务环境或Python服务环境,也可以两个都安装。如果不会安装可以查看在线帮助或到官网社区中的产品问答中看相关说明。再次,安装好后,打开Desktop,选择【管理系统】-【系统设置】-【R计算配置/Python计算配置】,如下图1所示。填写服务器地址和端口号,点击测试连接,如果连接正确,右上角会弹出测试成功。最后点击保存连接,至此,深度分析功能就可以使用了。
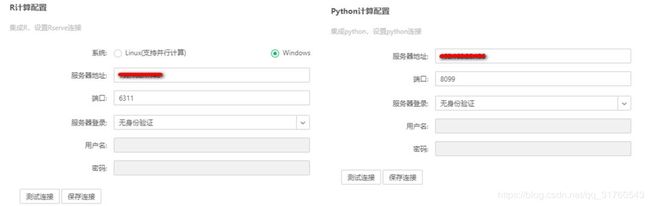
图1
想要对业务进行深度分析,就需要对机器学习的流程有一定的了解,通常的流程共有8步,如下图2。在永洪的产品中提供了几个常用的深度分析的场景,大家可以打开看看,也可以复用使用。
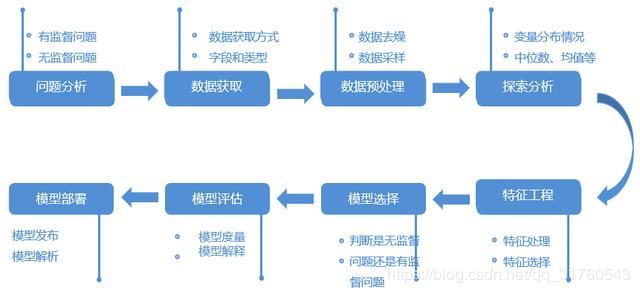
图2
第一步,问题分析,就是要确定对哪个问题进行分析。例如,对于银行业企业,通常会进行信用卡反欺诈分析、营销策略分析等。对于零售行业,通常会进行销售预测、用户画像分析等。对于政府,可以进行交通预测、人流量预测等。确定问题后就要判断问题是有监督问题还是无监督问题,以此来确定采用哪种技术方案。有监督学习是指输入数据中有标签,以概率函数、代数函数或人工神经网络为基函数模型,采用迭代计算方法,学习结果为函数。无监督学习是指输入数据中无标签,采用聚类方法,学习结果为类别。典型的无监督学习算法有降维、聚类等。如何判断有监督还是无监督,简单说就是主要看数据是否有打标签,如果有就是有监督,如果没有就是无监督。
第二步,数据获取,就是要把数据导入到产品中。在永洪产品中需要选择添加数据源模块,目前支持30多种数据源,如Excel、Mysql、Oracle等。设置好数据源后选择创建数据集,常用的为SQL数据集和Excel数据集,选择完数据后点击刷新数据,在右侧面板中可以看到获取的数据。
第三步,数据预处理,就是把导入到数据集的数据进行处理。如去重、拆分列、去空格、采样、分区等。这项工作用户可以在创建数据集模块进行设置,如下图3。

图3
此外,在深度分析模块也提供了一些数据处理的节点供用户使用,从这一步开始到第七步,我们就真正的进入到深度分析的领域了。下面,让我们来看看永洪的深度分析功能是如何使用的?基本流程如下图4。

图4
打开深度分析功能,可以看到,产品提供了一些案例可以帮助用户快速的学习和了解深度分析。选择新增实验模型,打开一个空白的实验创建面板,如下图5。
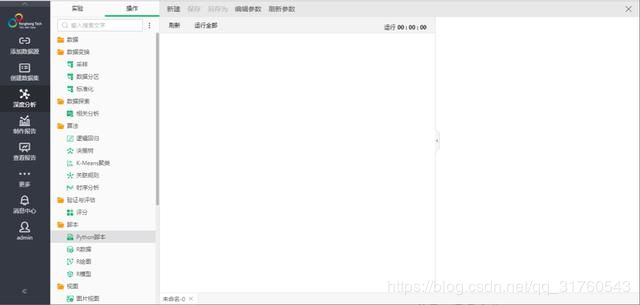
图5
左侧为操作节点,中间为画布,右侧为节点配置、实验探索等。操作中各个文件夹代表不同的功能节点。其中,数据里是用户上传后数据集保存的位置。数据变换里是可以对数据进行操作处理的节点。数据探索里是查看数据是否有缺失值、数据类型等。算法里目前支持(逻辑回归、决策树、K-Means、关联规则、时序分析)算法。验证与评估是评估模型预测结果(R)。脚本可以支持R、Python编程自定义开发。视图可以将实验结果进行可视化展示。导出中包括导出模型结果到数据库或数据集、保存训练模型或Excel等。训练模型显示的是用户保存的训练好的模型。
了解这些基本的操作后,我们来试试做一个简单的例子来运用深度分析。比如想要通过用户行为的历史数据进行预测分析,找出可能流失的客户,以采取对应策略挽留住老客户,如下图6。

图6
首先拖入已经创建的客户流失训练数据,在右侧可以看到元数据列名称和数据类型,要想了解客户流失,需要的数据有客户每天访问的总时间、客户每天总的费用、客户每天访问的平均时间、客户平均费用、客户流失与否等所有影响客户和与客户有关的数据,可以在探索数据中看到详细的数据值。当有数据后,还需要对数据进行处理,将采样节点拖入到画布中,对数据进行采样,一般我们使用随机采样的方式,采样比例视数据量大小而定,如果数据量很大的话可以使用稍小的采样比例,比如设置为10%,采样的结果可以在探索数据中查看。
在采样后我们需要对数据进行分区训练,以验证评估训练模型的好坏,一般训练集比例选择70%。分区后就需要选择合适的算法,由于数据属于有监督数据,且是预测分析,因此我们选择回归算法。将逻辑回归拖到画布上,与数据分区连接,在右侧配置项目中设置,如下图7,产品共支持两种回归算法,选择GLM(广义线性模型),回归方法选择逐步,因变量选择CustomerLeft列,然后点击选择,添加其余数值列为自变量。
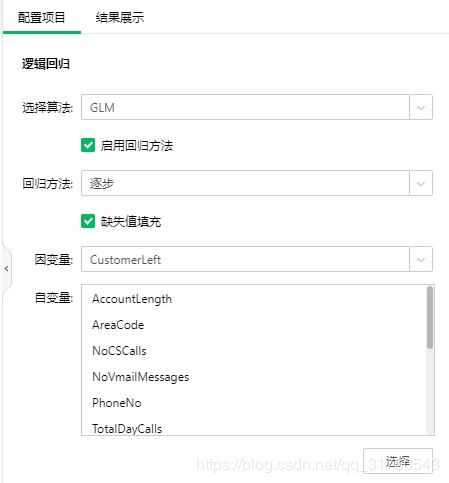
图7
这步配置好后,可以在节点上单击右键选择运行,查看预测的数据结果。运行成功后,会弹出结果展示,显示运行的结果,如下图8。从结果中我们可以看出,通过模型系数可以得到逻辑回归方程的系数,包括截距项、各自变量的系数以及它们的P值、标准误差。还可以看到模型训练集合验证集的准确率和均方误差。
可以看出,训练集的准确率高于验证集且P值都较小(P值越小结果越好)。通过ROC曲线可以看出数据训练后效果更好,训练集AUC值0.797大于验证集AUC值0.748(AUC值越大模型分类效果越好)。
训练好后可以保存为训练模型,将保存为训练模型节点拖到画布中与逻辑回归相连接,然后在右侧配置中选择保存的路径,运行实验后模型显示在训练模型文件夹中。保存的训练模型可以应用在制作报告模块或作为节点拖拽到画布上再次使用。
不会机器学习也能搞定深度分析,实操演练一看即会
图8
在对数据进行了预测分析后,我们还需要对训练数据进行评估,来验证数据的准确性。拖入“客户流失测试数据”节点和评分节点,评分节点连接逻辑回归和客户流失测试数据两个节点。点击顶部菜单栏中的运行全部,运行成功后选择评分节点,在数据探索里可以查看已经使用逻辑回归算法训练的模型应用于“客户流失测试数据“的结果,如下图9。
切换不同列,可以看到每列的数据,通过统计数据和可视化图表可以观察预测的准确性。数据中包括平均数、数据类型、唯一值、缺失值等,当缺失值为0时说明数据没有异常值。
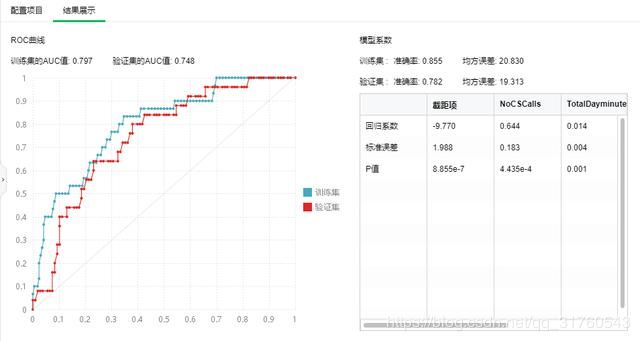
图9
实验创建成功后我们就可以进行最后一步发布和部署了,将保存为PMML文件节点拖入画布中,与逻辑回归连接,运行成功后,选择此节点,在右侧配置项目中可以选择下载到本地,你可以将这个PMML文件部署到其他平台,如下图10。产品还支持导出到数据库和保存为数据集。
图10
对于成功的实验,我们可以在可视化页面查看预测的数据,打开制作报告页面,拖入饼图组件,选择客户流失训练数据,然后在更多中选择已指定训练模型,选择刚刚保存的训练模型,可以看到维度和度量分别新增了类和概率,可以看到流失和不流失的占比。再拖入一个表格组件,拖入训练的数据,可以观察预测的概率(1是流失,0是非流失),如下图11。
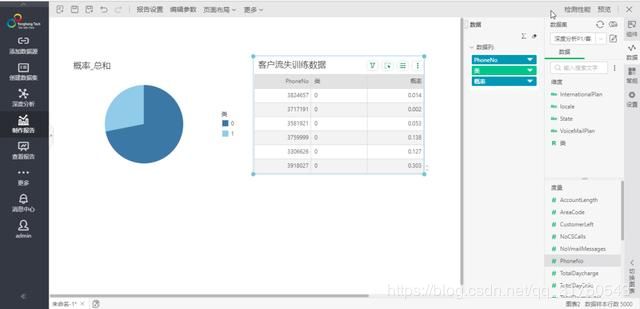
图11
通过以上这些,你对深度分析是不是有了一些了解呢?在国内,拥有深度分析功能的BI产品很少,永洪的深度分析模块便于没有机器学习基础的小白上手,对于机器学习模型部署方便、快捷、不需要定开,且支持R、Python 两种编程语言,用户可以通过脚本自定义数据处理和模型,并通过可视化展示模型运行结果。如果你也想要成为预测大师,就快来和我一起玩转起来吧!