Java中提到持久层框架,相信没有人不知道mybatis的存在,相对于JDBC她多了一份干练(jdbc工作量大),相对于Hibernate她又多了一份灵动(HQL虽然方便,但太呆板)。今天我们就一起走进她的世界。
一、mybatis的简单实现
准备工作
1.创建实体类和表映射
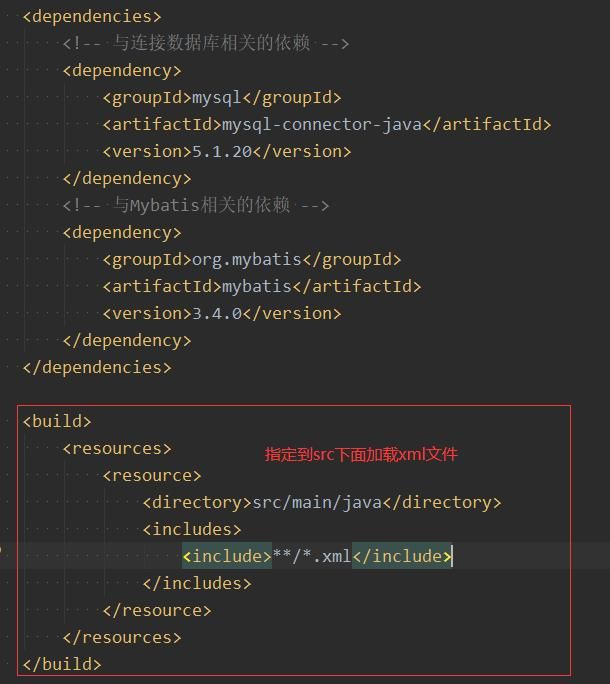
2.导入maven依赖
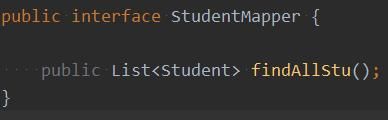
编写接口和mapper为文件

注意:在idea中,直接把资源文件放在src文件夹下,如果不进行设置,是不能被找到的,所以一定要在pom.xml(第一张图)中加入标记的代码,指定加载位置。
编写配置文件
![]()
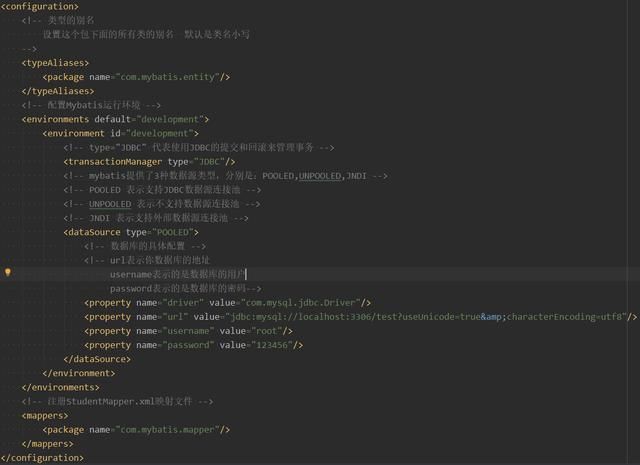
注意:配置文件要放在resources目录下
测试
二、mybatis的实现原理分析
原理分析之一:MyBatis的主要成员
Configuration :MyBatis所有的配置信息都保存在Configuration对象之中,配置文件中的大部分配置都会存储到该类中。
SqlSession :作为MyBatis工作的主要顶层API,表示和数据库交互时的会话,完成必要数据库增删改查功能。
Executor: MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护。
StatementHandler :封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数等。
ParameterHandler :负责对用户传递的参数转换成JDBC Statement 所对应的数据类型。
ResultSetHandler : 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合。
TypeHandler :负责java数据类型和jdbc数据类型(也可以说是数据表列类型)之间的映射和转换。
MappedStatement :MappedStatement维护一条
SqlSource:负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回。
BoundSql :表示动态生成的SQL语句以及相应的参数信息。
原理分析之二:Mybatis的执行流程

原理分析之三:初始化(配置文件读取和解析)
1. 准备工作
编写测试代码(具体请参考《Mybatis入门示例》),设置断点,以Debug模式运行,具体代码如下:
Java代码
String resource = "mybatis.cfg.xml"; Reader reader = Resources.getResourceAsReader(resource); SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(reader); SqlSession session = ssf.openSession();
我们此次就对上面的代码进行跟踪和分析,let's go。
首先我们按照顺序先看看第一行和第二行代码,看看它主要完成什么事情:
Java代码
String resource = "mybatis.cfg.xml"; Reader reader = Resources.getResourceAsReader(resource);
读取Mybaits的主配置配置文件,并返回该文件的输入流,我们知道Mybatis所有的SQL语句都写在XML配置文件里面,所以第一步就需要读取这些XML配置文件,这个不难理解,关键是读取文件后怎么存放。
我们接着看第三行代码(如下),该代码主要是读取配置文件流并将这些配置信息存放到Configuration类中。
Java代码
SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(reader);
SqlSessionFactoryBuilder的build的方法如下:
Java代码
public SqlSessionFactory build(Reader reader) { return build(reader, null, null); }
其实是调用该类的另一个build方法来执行的,具体代码如下:
Java代码
public SqlSessionFactory build(Reader reader, String environment, Properties properties) { try { XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties); return build(parser.parse()); } catch (Exception e) { throw ExceptionFactory.wrapException("Error building SqlSession.", e); } finally { ErrorContext.instance().reset(); try { reader.close(); } catch (IOException e) { // Intentionally ignore. Prefer previous error. } } }
我们重点看一下里面两行:
Java代码
//创建一个配置文件流的解析对象XMLConfigBuilder,其实这里是将环境和配置文件流赋予解析类 XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties); // 解析类对配置文件进行解析并将解析的内容存放到Configuration对象中,并返回SqlSessionFactory return build(parser.parse());
这里的XMLConfigBuilder初始化其实调用的代码如下:
Java代码
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) { super(new Configuration()); ErrorContext.instance().resource("SQL Mapper Configuration"); this.configuration.setVariables(props); this.parsed = false; this.environment = environment; this.parser = parser; }
XMLConfigBuilder的parse方法执行代码如下:
Java代码
public Configuration parse() { if (parsed) { throw new BuilderException("Each MapperConfigParser can only be used once."); } parsed = true; parseConfiguration(parser.evalNode("/configuration")); return configuration; }
解析的内容主要是在parseConfiguration方法中,它主要完成的工作是读取配置文件的各个节点,然后将这些数据映射到内存配置对象Configuration中,我们看一下parseConfiguration方法内容:
Java代码
private void parseConfiguration(XNode root) { try { typeAliasesElement(root.evalNode("typeAliases")); pluginElement(root.evalNode("plugins")); objectFactoryElement(root.evalNode("objectFactory")); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); propertiesElement(root.evalNode("properties")); settingsElement(root.evalNode("settings")); environmentsElement(root.evalNode("environments")); typeHandlerElement(root.evalNode("typeHandlers")); mapperElement(root.evalNode("mappers")); }catch (Exception e) { throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); } }
最后的build方法其实是传入配置对象进去,创建DefaultSqlSessionFactory实例出来. DefaultSqlSessionFactory是SqlSessionFactory的默认实现.
Java代码
public SqlSessionFactory build(Configuration config) { return new DefaultSqlSessionFactory(config); }
最后我们看一下第四行代码:
Java代码
SqlSession session = ssf.openSession();
通过调用DefaultSqlSessionFactory的openSession方法返回一个SqlSession实例,我们看一下具体是怎么得到一个SqlSession实例的。首先调用openSessionFromDataSource方法。
Java代码
public SqlSession openSession() { return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false); }
下面我们看一下openSessionFromDataSource方法的逻辑:
Java代码
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Connection connection = null; try { //获取配置信息里面的环境信息,这些环境信息都是包括使用哪种数据库,连接数据库的信息,事务 final Environment environment = configuration.getEnvironment(); //根据环境信息关于数据库的配置获取数据源 final DataSource dataSource = getDataSourceFromEnvironment(environment); //根据环境信息关于事务的配置获取事务工厂 TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); connection = dataSource.getConnection(); if (level != null) { //设置连接的事务隔离级别 connection.setTransactionIsolation(level.getLevel()); } //对connection进行包装,使连接具备日志功能,这里用的是代理。 connection = wrapConnection(connection);//从事务工厂获取一个事务实例 Transaction tx = transactionFactory.newTransaction(connection, autoCommit); //从配置信息中获取一个执行器实例 Executor executor = configuration.newExecutor(tx, execType); //返回SqlSession的一个默认实例 return new DefaultSqlSession(configuration, executor, autoCommit); } catch (Exception e) { closeConnection(connection); throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
传入参数说明:
(1)ExecutorType:执行类型,ExecutorType主要有三种类型:SIMPLE, REUSE, BATCH,默认是SIMPLE,都在枚举类ExecutorType里面。
(2)TransactionIsolationLevel:事务隔离级别,都在枚举类TransactionIsolationLevel中定义。
(3)autoCommit:是否自动提交,主要是事务提交的设置。
DefaultSqlSession是SqlSession的实现类,该类主要提供操作数据库的方法给开发人员使用。
这里总结一下上面的过程,总共由三个步骤:
步骤一:读取Ibatis的主配置文件,并将文件读成文件流形式(InputStream)。
步骤二:从主配置文件流中读取文件的各个节点信息并存放到Configuration对象中。读取mappers节点的引用文件,并将这些文件的各个节点信息存放到Configuration对象。
步骤三:根据Configuration对象的信息获取数据库连接,并设置连接的事务隔离级别等信息,将经过包装数据库连接对象SqlSession接口返回,DefaultSqlSession是SqlSession的实现类,所以这里返回的是DefaultSqlSession,SqlSession接口里面就是对外提供的各种数据库操作。
原理分析之四:一次SQL查询的源码分析
上回我们讲到Mybatis加载相关的配置文件进行初始化,这回我们讲一下一次SQL查询怎么进行的。
准备工作
Mybatis完成一次SQL查询需要使用的代码如下:
Java代码
String resource = "mybatis.cfg.xml"; Reader reader = Resources.getResourceAsReader(resource); SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(reader); SqlSession session = ssf.openSession(); try { UserInfo user = (UserInfo) session.selectOne("User.selectUser", "1"); System.out.println(user); } catch (Exception e) { e.printStackTrace(); } finally { session.close(); }
本次我们需要进行深入跟踪分析的是:
Java代码
SqlSession session = ssf.openSession(); UserInfo user = (UserInfo) session.selectOne("User.selectUser", "1");
第一步:打开一个会话,我们看看里面具体做了什么事情。
Java代码
SqlSession session = ssf.openSession();
DefaultSqlSessionFactory的 openSession()方法内容如下:
Java代码
public SqlSession openSession() { return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false); }
跟进去,我们看一下openSessionFromDataSource方法到底做了啥:
Java代码
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Connection connection = null; try { final Environment environment = configuration.getEnvironment(); final DataSource dataSource = getDataSourceFromEnvironment(environment); TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); connection = dataSource.getConnection(); if (level != null) { connection.setTransactionIsolation(level.getLevel()); }connection = wrapConnection(connection); Transaction tx = transactionFactory.newTransaction(connection, autoCommit); Executor executor = configuration.newExecutor(tx, execType); return new DefaultSqlSession(configuration, executor, autoCommit); } catch(Exception e) { closeConnection(connection); throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset();} }
这里我们分析一下这里所涉及的步骤:
(1)获取前面我们加载配置文件的环境信息,并且获取环境信息中配置的数据源。
(2)通过数据源获取一个连接,对连接进行包装代理(通过JDK的代理来实现日志功能)。
(3)设置连接的事务信息(是否自动提交、事务级别),从配置环境中获取事务工厂,事务工厂获取一个新的事务。
(4)传入事务对象获取一个新的执行器,并传入执行器、配置信息等获取一个执行会话对象。
从上面的代码我们可以得出,一次配置加载只能有且对应一个数据源。对于上述步骤,我们不难理解,我们重点看看新建执行器和DefaultSqlSession。
首先,我们看看newExecutor到底做了什么?
Java代码
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {executorType = executorType == null ? defaultExecutorType : executorType; executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Executor executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { executor = new SimpleExecutor(this, transaction); } if (cacheEnabled) { executor = new CachingExecutor(executor); } executor = (Executor) interceptorChain.pluginAll(executor); return executor; }
上面代码的执行步骤如下:
(1)判断执行器类型,如果配置文件中没有配置执行器类型,则采用默认执行类型ExecutorType.SIMPLE。
(2)根据执行器类型返回不同类型的执行器(执行器有三种,分别是 BatchExecutor、SimpleExecutor和CachingExecutor,后面我们再详细看看)。
(3)跟执行器绑定拦截器插件(这里也是使用代理来实现)。
DefaultSqlSession到底是干什么的呢?
DefaultSqlSession实现了SqlSession接口,里面有各种各样的SQL执行方法,主要用于SQL操作的对外接口,它会的调用执行器来执行实际的SQL语句。
接下来我们看看SQL查询是怎么进行的
Java代码
UserInfo user = (UserInfo) session.selectOne("User.selectUser", "1");
实际调用的是DefaultSqlSession类的selectOne方法,该方法代码如下:
Java代码
public Object selectOne(String statement, Object parameter) { // Popular vote was to return null on 0 results and throw exception on too many. List list = selectList(statement, parameter); if (list.size() == 1) { return list.get(0); } else if (list.size() > 1) { throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size()); } else { return null; } }
我们再看看selectList方法(实际上是调用该类的另一个selectList方法来实现的):
Java代码
public List selectList(String statement, Object parameter) { return selectList(statement, parameter, RowBounds.DEFAULT); } public List selectList(String statement, Object parameter, RowBounds rowBounds) { try { MappedStatement ms = configuration.getMappedStatement(statement); return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
第二个selectList的执行步骤如下:
(1)根据SQL的ID到配置信息中找对应的MappedStatement,在之前配置被加载初始化的时候我们看到了系统会把配置文件中的SQL块解析并放到一个MappedStatement里面,并将MappedStatement对象放到一个Map里面进行存放,Map的key值是该SQL块的ID。
(2)调用执行器的query方法,传入MappedStatement对象、SQL参数对象、范围对象(此处为空)和结果处理方式。
好了,目前只剩下一个疑问,那就是执行器到底怎么执行SQL的呢?
上面我们知道了,默认情况下是采用SimpleExecutor执行的,我们看看这个类的doQuery方法:
Java代码
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, rowBounds, resultHandler); stmt = prepareStatement(handler); return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } }
doQuery方法的内部执行步骤:
(1) 获取配置信息对象。
(2)通过配置对象获取一个新的StatementHandler,该类主要用来处理一次SQL操作。
(3)预处理StatementHandler对象,得到Statement对象。
(4)传入Statement和结果处理对象,通过StatementHandler的query方法来执行SQL,并对执行结果进行处理。
我们看一下newStatementHandler到底做了什么?
Java代码
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) { StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler); statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler); return statementHandler; }
上面代码的执行步骤:
(1)根据相关的参数获取对应的StatementHandler对象。
(2)为StatementHandler对象绑定拦截器插件。
RoutingStatementHandler类的构造方法RoutingStatementHandler如下:
Java代码
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) { switch (ms.getStatementType()) { case STATEMENT: delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler); break; case PREPARED: delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler); break; case CALLABLE: delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler); break; default: throw new ExecutorException("Unknown statement type: " + ms.getStatementType()); } }
根据 MappedStatement对象的StatementType来创建不同的StatementHandler,这个跟前面执行器的方式类似。StatementType有STATEMENT、PREPARED和CALLABLE三种类型,跟JDBC里面的Statement类型一一对应。
我们看一下prepareStatement方法具体内容:
Java代码
private Statement prepareStatement(StatementHandler handler) throws SQLException {Statement stmt; Connection connection = transaction.getConnection(); //从连接中获取Statement对象 stmt = handler.prepare(connection); //处理预编译的传入参数 handler.parameterize(stmt); return stmt; }