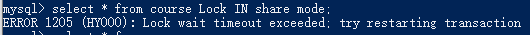MVCC和快照读丶当前读
文章目录
- MVCC的实现原理
- 版本链
- ReadView
- MVCC实现不同隔离级别
- Read Committed隔离级别下MVCC工作原理
- Repeatable Read隔离级别下MVCC工作原理
- 快照读和当前读
- 快照读
- 当前读
- 实例:
原博客地址
参考博文
MVCC的实现原理
为了方便描述,首先我们创建一个表book,就三个字段,分别是主键book_id, 名称book_name, 库存stock。然后向表中插入一些数据:
INSERT INTO book VALUES(1, '数据结构', 100);
INSERT INTO book VALUES(2, 'C++指南', 100);
INSERT INTO book VALUES(3, '精通Java', 100);
版本链
对于使用InnoDB存储引擎的表,其聚簇索引记录中包含了两个重要的隐藏列:
- trx_id:每当事务对聚簇索引中的记录进行修改时,都会把当前事务的事务id记录到trx_id中。
- roll_pointer:每当事务对聚簇索引中的记录进行修改时,都会把该记录的旧版本记录到undo日志中,通过roll_pointer这个指针可以用来获取该记录旧版本的信息。
如果在一个事务中多次对记录进行修改,则每次修改都会生成undo日志,并且这些undo日志通过roll_pointer指针串联成一个版本链,版本链的头结点是该记录最新的值,尾结点是事务开始时的初始值。
例如,我们在表book中做以下修改:
BEGIN;
UPDATE book SET stock = 200 WHERE id = 1;
UPDATE book SET stock = 300 WHERE id = 1;
那么id=1的记录此时的版本链就如下图所示:
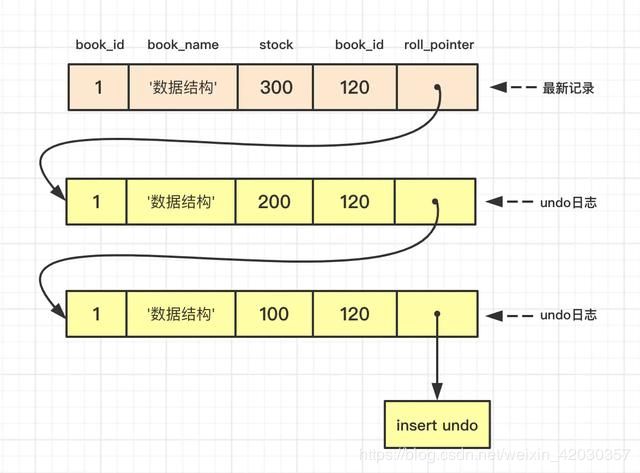
如果上面不能理解:则看下面这几张图:
![]()
比如现在有个事务id是60的执行的这条记录的修改语句
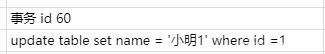
此时在undo日志中就存在版本链

ReadView
对于使用Read Uncommitted隔离级别的事务来说,只需要读取版本链上最新版本的记录即可;对于使用Serializable隔离级别的事务来说,InnoDB使用加锁的方式来访问记录。而Read Committed和Repeatable Read隔离级别来说,都需要读取已经提交的事务所修改的记录,也就是说如果版本链中某个版本的修改没有提交,那么该版本的记录时不能被读取的。所以需要确定在Read Committed和Repeatable Read隔离级别下,版本链中哪个版本是能被当前事务读取的。于是ReadView的概念被提出以解决这个问题。
首先我们需要知道的一个事实是:事务id是递增分配的。ReadView的机制就是在生成ReadView时确定了以下几种信息:
- m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
- min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。
- max_trx_id:表示生成ReadView时系统中将要分配给下一个事务的id值。
- creator_trx_id:表示生成该ReadView的事务的事务id。
这样事务id就可以分成3个区间:
- 区间(0, min_trx_id):如果被访问版本的 trx_id 小于 m_ids 中的最小值 up_limit_id,说明生成该版本的事务在 ReadView 生成前就已经提交了,所以该版本可以被当前事务访问
- 区间[min_trx_id, max_trx_id): 如果被访问版本的 trx_id 大于 m_ids 列表中的最大值 low_limit_id,说明生成该版本的事务在生成 ReadView 后才生成,所以该版本不可以被当前事务访问。需要根据 Undo Log 链找到前一个版本,然后根据该版本的 DB_TRX_ID 重新判断可见性
- 区间[max_trx_id, +∞):如果被访问版本的 trx_id 属性值在 m_ids 列表中最大值和最小值之间(包含),那就需要判断一下 trx_id 的值是不是在 m_ids 列表中。如果在,说明创建 ReadView 时生成该版本所属事务还是活跃的,因此该版本不可以被访问,需要查找 Undo Log 链得到上一个版本,然后根据该版本的 DB_TRX_ID 再从头计算一次可见性;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
下面我们根据ReadView提供的条件信息,顺着版本链从头结点开始查找最新的可被读取的版本记录:
1、首先判断版本记录的trx_id与ReadView中的creator_trx_id是否相等。如果相等,那就说明该版本的记录是在当前事务中生成的,自然也就能够被当前事务读取;否则进行第2步。
2、根据版本记录的trx_id以及上述3个区间信息,判断生成该版本记录的事务是否是已提交事务,进而确定该版本记录是否可被当前事务读取。
如果某个版本记录经过以上步骤判断确定其可被当前事务读取,则查询结果返回此版本记录;否则读取下一个版本记录继续按照上述步骤进行判断,直到版本链的尾结点。如果遍历完版本链没有找到可读取的版本,则说明该记录对当前事务不可见,查询结果为空。
在MySQL中,Read Committed和Repeatable Read隔离级别下的区别就是它们生成ReadView的时机不同。
MVCC实现不同隔离级别
之前说到ReadView的机制只在Read Committed和Repeatable Read隔离级别下生效,所以只有这两种隔离级别才有MVCC。在Read Committed隔离级别下,每次读取数据时都会生成ReadView;而在Repeatable Read隔离级别下只会在事务首次读取数据时生成ReadView,之后的读操作都会沿用此ReadView。
下面我们通过例子来看看Read Committed和Repeatable Read隔离级别下MVCC的不同表现。我们继续以表book为例进行演示。
Read Committed隔离级别下MVCC工作原理
假设在Read Committed隔离级别下,有如下事务在执行,事务id为10:
BEGIN; // 开启Transaction 10
UPDATE book SET stock = 200 WHERE id = 2;
UPDATE book SET stock = 300 WHERE id = 2;
此时该事务尚未提交,id为2的记录版本链如下图所示:
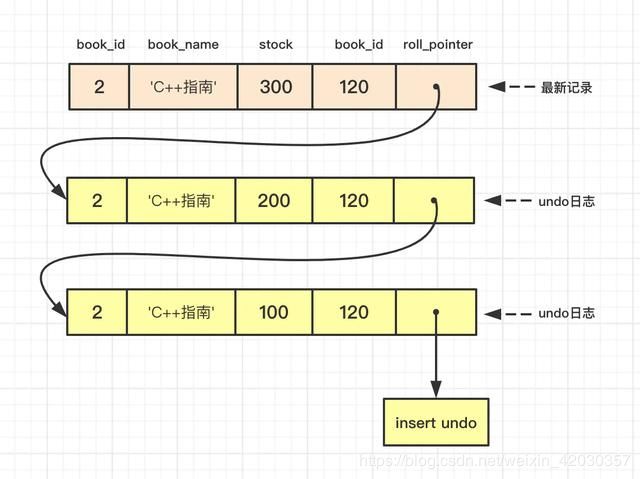
浅谈MySQL并发控制:隔离级别、锁与MVCC
然后我们开启一个事务对id为2的记录进行查询:
BEGIN;
当执行SELECT语句时会生成一个ReadView,该ReadView中的m_ids为[10],min_trx_id为10,max_trx_id为11,creator_trx_id为0(因为事务中当执行写操作时才会分配一个单独的事务id,否则事务id为0)。按照我们之前所述ReadView的工作原理,我们查询到的版本记录为
+----------+-----------+-------+
| book_id | book_name | stock |
+----------+-----------+-------+
| 2 | C++指南 | 100 |
+----------+-----------+-------+
然后我们将事务id为10的事务提交:
BEGIN; // 开启Transaction 10
UPDATE book SET stock = 200 WHERE id = 2;
UPDATE book SET stock = 300 WHERE id = 2;
COMMIT;
同时开启执行另一事务id为11的事务,但不提交:
BEGIN; // 开启Transaction 11
UPDATE book SET stock = 400 WHERE id = 2;
此时id为2的记录版本链如下图所示:
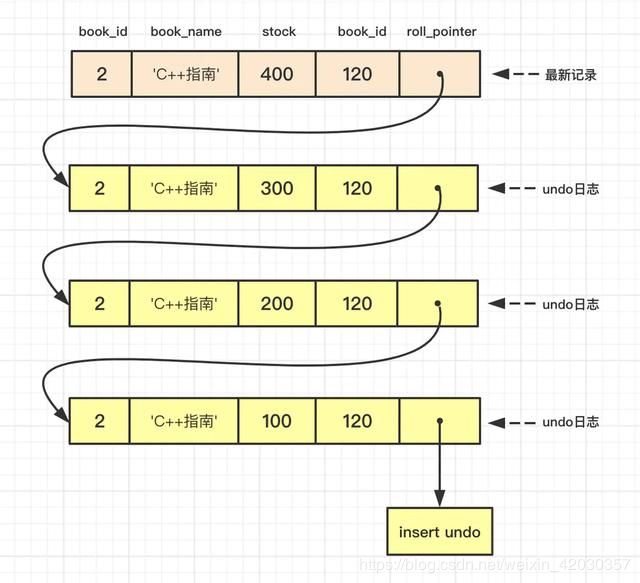
浅谈MySQL并发控制:隔离级别、锁与MVCC
然后我们回到刚才的查询事务中再次查询id为2的记录:
BEGIN;
SELECT * FROM book WHERE id = 2; // 此时Transaction 10 未提交
SELECT * FROM book WHERE id = 2; // 此时Transaction 10 已提交
当第二次执行SELECT语句时会再次生成一个ReadView,该ReadView中的m_ids为[11],min_trx_id为11,max_trx_id为12,creator_trx_id为0。按照ReadView的工作原理进行分析,我们查询到的版本记录为
+----------+-----------+-------+
| book_id | book_name | stock |
+----------+-----------+-------+
| 2 | C++指南 | 300 |
+----------+-----------+-------+
从上述分析可以发现,因为每次执行查询语句都会生成新的ReadView,所以在Read Committed隔离级别下的事务读取到的是查询时刻表中已提交事务修改之后的数据。
Repeatable Read隔离级别下MVCC工作原理
我们在Repeatable Read隔离级别下重复上面的事务操作:
BEGIN; // 开启Transaction 20
UPDATE book SET stock = 200 WHERE id = 2;
UPDATE book SET stock = 300 WHERE id = 2;
此时该事务尚未提交,然后我们开启一个事务对id为2的记录进行查询:
BEGIN;
SELECT * FROM book WHERE id = 2;
当事务第一次执行SELECT语句时会生成一个ReadView,该ReadView中的m_ids为[20],min_trx_id为20,max_trx_id为21,creator_trx_id为0。根据ReadView的工作原理,我们查询到的版本记录为
+----------+-----------+-------+
| book_id | book_name | stock |
+----------+-----------+-------+
| 2 | C++指南 | 100 |
+----------+-----------+-------+
然后我们将事务id为20的事务提交:
BEGIN; // 开启Transaction 20
UPDATE book SET stock = 200 WHERE id = 2;
UPDATE book SET stock = 300 WHERE id = 2;
COMMIT;
同时开启执行另一事务id为21的事务,但不提交:
BEGIN; // 开启Transaction 21
UPDATE book SET stock = 400 WHERE id = 2;
然后我们回到刚才的查询事务中再次查询id为2的记录:
``sql
BEGIN;
SELECT * FROM book WHERE id = 2; // 此时Transaction 10 未提交
SELECT * FROM book WHERE id = 2; // 此时Transaction 10 已提交
当第二次执行SELECT语句时不会生成新的ReadView,依然会使用第一次查询时生成ReadView。因此我们查询到的版本记录跟第一次查询到的结果是一样的:
```sql
+----------+-----------+-------+
| book_id | book_name | stock |
+----------+-----------+-------+
| 2 | C++指南 | 100 |
+----------+-----------+-------+
从上述分析可以发现,因为在Repeatable Read隔离级别下的事务只会在第一次执行查询时生成ReadView,该事务中后续的查询操作都会沿用这个ReadView,因此此隔离级别下一个事务中多次执行同样的查询,其结果都是一样的,这样就实现了可重复读。
快照读和当前读
快照读
在Read Committed和Repeatable Read隔离级别下,普通的SELECT查询都是读取MVCC版本链中的一个版本,相当于读取一个快照,因此称为快照读。这种读取方式不会加锁,因此读操作时非阻塞的,因此也叫非阻塞读。
在标准的Repeatable Read隔离级别下读操作会加S锁,直到事务结束,因此可以阻止其他事务的写操作;但在MySQL的Repeatable Read隔离级别下读操作没有加锁,不会阻止其他事务对相同记录的写操作,因此在后续进行写操作时就有可能写入基于版本链中的旧数据计算得到的结果,这就导致了提交覆盖的问题。想要避免此问题,就需要另外加锁来实现。
当前读
之前提到MySQL有两种锁定读的方式:
SELECT ... LOCK IN SHARE MODE; // 读取时对记录加S锁,直到事务结束
SELECT ... FOR UPDATE; // 读取时对记录加X锁,直到事务结束
这种读取方式读取的是记录的当前最新版本,称为当前读。另外对于DELETE、UPDATE操作,也是需要先读取记录,获取记录的X锁,这个过程也是一个当前读。由于需要对记录进行加锁,会阻塞其他事务的写操作,因此也叫加锁读或阻塞读。
当前读不仅会对当前记录加行记录锁,还会对查询范围空间的数据加间隙锁(GAP LOCK),因此可以阻止幻读问题的出现。
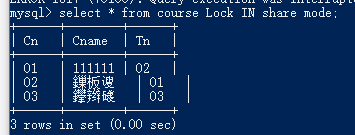
实例:
如果另一个事务没有提交,那么这个当前读就会在这里堵塞,直到事务提交,读取最新的值。
- 1.第一个窗口,开启事务,并进行update修改操作,但是事务未提交。
首先需要SET autocommit = 0;关闭代码自动提交。连接
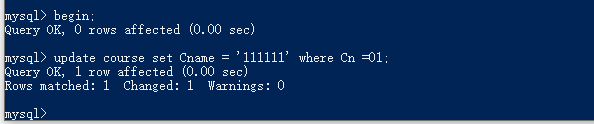
- 2.第二个窗口,直接读(快照读),读取的是版本链上以前的版本。
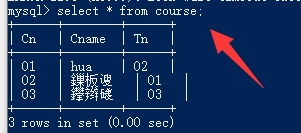
- 第二个窗口,使用锁(当前读),一直等到事务提交才能获取到值(最新的值)。如下图所示,第一张图,事务未提交(阻塞),第二张图事务提交之后(读取)。