深度之眼【Pytorch】-读取自己的数据 Dataset 和 ImageFolder
本文为深度之眼pytorch训练营二期学习笔记,详细课程内容移步:深度之眼 https://ai.deepshare.net/index
目录
重写Dataset类
例子一:通过 包含 数据路径 与 标签 的文件读取
例子二: 通过标签文件读取
例子三: 没有标签文件,代码中自己构造
文件夹读取 :ImageFolder
例子一:
重写Dataset类
Pytorch文档里的源码解说

#源码
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
#这个函数就是根据索引,迭代的读取路径和标签。因此我们需要有一个路径和标签的 ‘容器’供我们读
def __getitem__(self, index):
raise NotImplementedError
#返回数据的长度
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
想要制作自己的图像数据集供DataLoader拿取,首先就要自己重写Dataset类,重写这个类主要就是完成从哪里读取数据和标签的功能。因此这里最主要就是__getitem__ (返回数据 和标签) 和 __len__(返回数据的长度)这两个方法。
完成这个Dataset类里面的两个主要功能之后。
训练的时候再把数据集传给DataLoader就可以获取自己想要的batch数据了,这个我们感受不到,但是内部它会自己去完成批量的读取。
例子一:通过 包含 数据路径 与 标签 的文件读取
这个比较简单,就是读取图片路径,标签,保存到txt文件中,这里注意格式就好特别注意的是,txt中的路径,是以训练时的那个py文件所在的目录为工作目录,所以这里需要提前算好相对路径!

# coding: utf-8
from PIL import Image
from torch.utils.data import Dataset
#集成Dataset类
class MyDataset(Dataset):
def __init__(self, txt_path, transform = None, target_transform = None):
"""
tex_path : txt文本路径,该文本包含了图像的路径信息,以及标签信息
transform:数据处理,对图像进行随机剪裁,以及转换成tensor
"""
fh = open(txt_path, 'r') #读取文件
imgs = [] #用来存储路径与标签
#一行一行的读取
for line in fh:
line = line.rstrip() #这一行就是图像的路径,以及标签
words = line.split()
imgs.append((words[0], int(words[1]))) #路径和标签添加到列表中
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index] #通过index索引返回一个图像路径fn 与 标签label
img = Image.open(fn).convert('RGB') #把图像转成RGB
if self.transform is not None:
img = self.transform(img)
return img, label #这就返回一个样本
def __len__(self):
return len(self.imgs) #返回长度,index就会自动的指导读取多少
# 博客链接:https://blog.csdn.net/u011995719/article/details/85102770
例子二: 通过标签文件读取
#首先集成Dataset这个类
class DealDataset(Dataset):
"""
下载数据、初始化数据,都可以在这里完成
"""
def __init__(self):
#这里xy 就是一个容器,通过读取一个包含有数据和标签信息的文件
xy = np.loadtxt('../dataSet/diabetes.csv.gz', delimiter=',', dtype=np.float32)
self.x_data = torch.from_numpy(xy[:, 0:-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
#长度,可以给__len__返回用。
self.len = xy.shape[0]
def __getitem__(self, index):
#通过索引index,索引到指定的数据以及对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
#博客链接:https://blog.csdn.net/zw__chen/article/details/82806900例子三: 没有标签文件,代码中自己构造
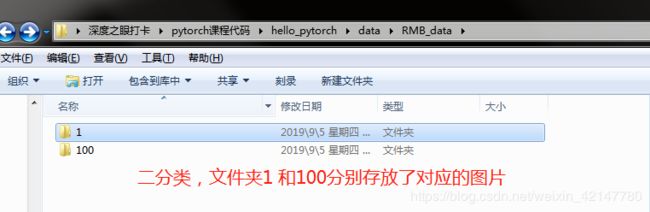
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index] #索引读取图像路径和标签
img = Image.open(path_img).convert('RGB') # 读取图像,返回Image 类型 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,把图像转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info ##返回的也就是图像路径 和 标签文件夹读取 :ImageFolder
例子一:
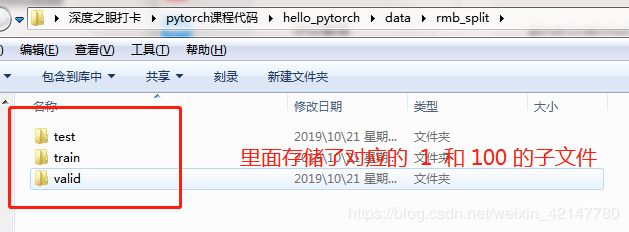
在pytorch中提供了:torchvision.datasets.ImageFolder让我们训练自己的图像。当时要求:先创建train和test文件夹,每个文件夹下按照类别名字存储对应的图像就可以了。
# 预处理 转为tensor 以及 标准化
transform = transform.Compose([transform.ToTensor(), transform.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
#使用torchvision.datasets.ImageFolder读取数据集 指定train 和 test文件夹
traindata = torchvision.datasets.ImageFolder('data/rmb_split/train/', transform=transform)
trainloader = torch.utils.data.DataLoader(traindata, batch_size=4, shuffle=True, num_workers=1)
testset = torchvision.datasets.ImageFolder('data/rmb_split/test/', transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=True, num_workers=1)
#测试集一样的
#参考:https://blog.csdn.net/iamsongyu/article/details/88283138