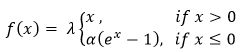tensorflow激活函数总结分析
每个神经元都必须有激活函数。它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性。该函数取所有输入的加权和,进而生成一个输出信号。你可以把它看作输入和输出之间的转换。使用适当的激活函数,可以将输出值限定在一个定义的范围内。
如果 xi 是第 j 个输入,Wj 是连接第 j 个输入到神经元的权重,b 是神经元的偏置,神经元的输出(在生物学术语中,神经元的激活)由激活函数决定,并且在数学上表示如下:
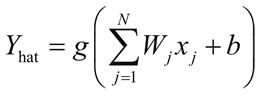
这里,g 表示激活函数。激活函数的参数 ΣWjxj+b 被称为神经元的活动。
这里对给定输入刺激的反应是由神经元的激活函数决定的。有时回答是二元的(是或不是)。例如,当有人开玩笑的时候...要么不笑。在其他时候,反应似乎是线性的,例如,由于疼痛而哭泣。有时,答复似乎是在一个范围内。
下面整理了tensorflow中提供的激活函数:
1、sigmoid激活函数
sigmoid函数也被称为S型函数,它可以将整个实数区间映射到(0,1)区间,因此经常被用来计算概率,它也是在传统神经网络中被经常使用的一种激活函数。
sigmoid函数可以由下列公式定义
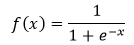

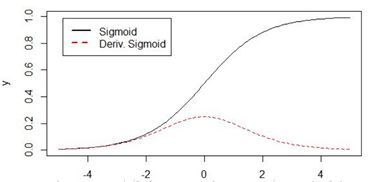
sigmoid函数对x求导的公式:
![]()
sigmoid激活函数的优点:
1)输出的映射区间(0,1)内单调连续,非常适合用作输出层;
2)比较容易求导;
3)输出范围有限,数据不会发散
sigmoid激活函数的缺点:
1)导数从0开始很快就又趋近于0了(如上图所示),易造成“梯度消失”现象。
sigmoid的tensoflow函数
x = tf.constant([[-1,-2],[3,4],[5,6]],dtype=tf.float32)
sess = tf.Session()
print(sess.run(tf.sigmoid(x)))
2、log_sigmoid激活函数
对sigmoid函数求log,它将整个实数区间映射到了(负无穷,0)

log_sigmoid的tensoflow函数:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
if __name__ == "__main__":
x = tf.constant(np.arange(-10,10),dtype=tf.float32)
sess = tf.Session()
y = sess.run(tf.log_sigmoid(x))
print(y)
plt.plot(np.arange(-10,10),y)
plt.show()3、tanh激活函数
tanh是双曲正切函数,它将整个实数区间映射到了(-1,1),tanh函数也具有软饱和性。它的输出是以0为中心,tanh的收敛速度比sigmoid要快,由于存在软饱和性,所以tanh也存在梯度消失的问题。

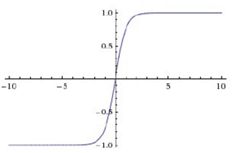
通过对比tanh与sigmoid函数,可以发现
![]()
tanh可以由sigmoid缩放平移得到。
优点:
1)输出范围[-1,1],解决了sigmoid非零均值的问题。
缺点:
1)仍然存在梯度消失和幂运算的问题。
2)如果给tanh的输入值很大,那在反向求梯度的时候就很小(从下图的斜率可以看出),不利于网络收敛。
tanh的tensoflow函数:
x = tf.constant(np.arange(-10,10),dtype=tf.float32)
sess = tf.Session()
y = sess.run(tf.tanh(x))
print(y)
plt.plot(np.arange(-10,10),y)
plt.show()
4、ReLU激活函数
relu激活函数现在是最受欢迎的激活函数,经常被使用在神经网络中。
relu函数在x<0时,输出始终为0。由于x>0时,relu函数的导数为1,所以relu函数能够在x>0时保持梯度不断衰减,从而缓解梯度消失的问题,还能加快收敛速度,还能是神经网络具有稀疏性表达能力,这也是relu激活函数能够被使用在深层神经网络中的原因。
由于当x<0时,relu函数的导数为0,导致对应的权重无法更新,这样的神经元被称为"神经元死亡"。
![]()
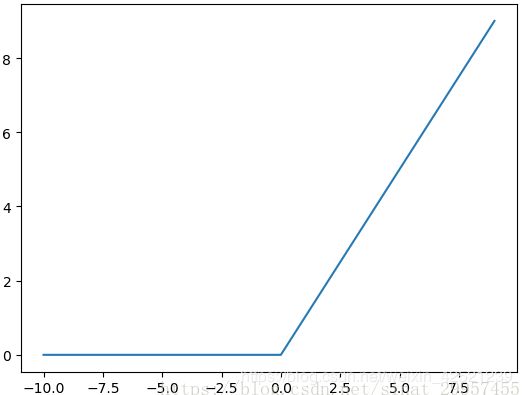
优点:
1)使网络可以自行引入稀疏性,提高了训练速度;
2)计算复杂度低,不需要指数运算,适合后向传播。
缺点:
1)输出不是零均值,不会对数据做幅度压缩;
2)容易造成神经元坏死现象,某些神经元可能永远不会被激活,导致相应参数永远不会更新。
relu的tensorflow函数:
x = tf.constant(np.arange(-10,10),dtype=tf.float32)
sess = tf.Session()
y = sess.run(tf.nn.relu(x))
print(y)
plt.plot(np.arange(-10,10),y)
plt.show()
5、relu6激活函数
定义min(max(features,0),6),也就是说它的取值区间被限定在了[0,6]之间。
![]()
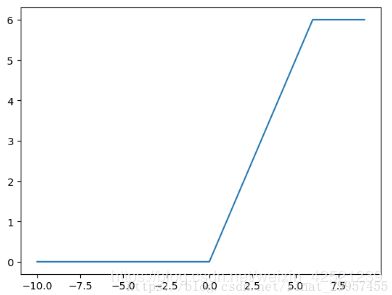
relu6的tensorflow函数:
x = tf.constant(np.arange(-10,10),dtype=tf.float32)
sess = tf.Session()
y = sess.run(tf.nn.relu6(x))
print(y)
plt.plot(np.arange(-10,10),y)
plt.show()
6、crelu激活函数
定义为[relu(x),relu(-x)]相对于relu(x),crelu的输出会增加一倍。
CReLU的全称Concatenated RectifiedLinear Units,相当于把两个ReLU级联起来,输出维度会自动加倍,比如:CeLU(−3)= [0,3],CeLU(3) = [3,0]。因此,在使用CReLU时要有意识的将滤波器数量减半,否则会将输入的feature map的数量扩展为两倍,网络参数将会增加。
crelu的tensorflow函数为:
x = tf.constant(np.arange(-10,10),dtype=tf.float32)
sess = tf.Session()
y = sess.run(tf.nn.crelu(x))
print(y)
7、softplus激活函数
定义为log((e^x)+1),被称为平滑的relu。

softplus的tensorflow函数为:
x = tf.constant(np.arange(-10,10),dtype=tf.float32)
sess = tf.Session()
y = sess.run(tf.nn.leaky_relu(x,alpha=0.2))
print(y)
plt.plot(np.arange(-10,10),y)
plt.show()
8、leak_relu激活函数
leak_relu激活函数会给x<0,一个斜率,而不是将所有x<0都输出0,默认斜率是0.2,x>0的部分仍然输出是x,即斜率为1,保持不变。

alpha称为slope系数,一般是一个比较小的非负数,在tensorflow中默认alpha = 0.2。
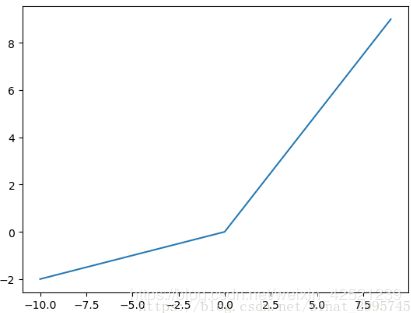
优点:
1)Leaky ReLU与ReLU的区别在于,当x<0时,不再输出0。因此可以解决ReLU带来的神经元坏死的问题。
缺点:
2)实际表现不一定就比ReLU好。
x = tf.constant(np.arange(-10,10),dtype=tf.float32)
sess = tf.Session()
y = sess.run(tf.nn.leaky_relu(x,alpha=0.2))
print(y)
plt.plot(np.arange(-10,10),y)
plt.show()
9、PReLU激活函数
![]()
PReLU即Parametric Leaky ReLU,它与Leaky ReLU的差别在于,Leaky ReLU的系数是一个标量,而PReLU的系数是形如的一组向量,在不同通道系数不同,上式中i表示第i个通道的系数,且系数本身是可以进行学习的。
10、RReLU激活函数
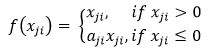
RReLU即Randomized Leaky ReLU,其中系数a_ji服从均匀分布U(l, u),l RReLU是Leaky ReLU的随机化改进。在训练阶段,a_ji是从均匀分布U(l, u)上随机采样得到的;在测试阶段则采用固定的参数a_test = (l+u)/2。 总结来说,Leaky ReLU中的是固定的;PReLU中的a_i是根据数据变化的;RReLU中a_ij的是在给定的范围内随机抽取的值,这个值在测试环节就会固定下来。 ELU全称为Exponential Linear Unit,a是一个可调的参数,它控制ELU负值部分在何时饱和。 优点: 1)右侧线性部分使得ELU能够缓解梯度消失,左侧的软饱和提升了对噪声的鲁棒性。 2)ELU的输出均值接近于0,收敛速度更快。 但是在tensorflow的代码中,设置a=1,该参数不可调。 SeLU全称是scaled exponential linearunits,是在ELU的基础上增加了一个scale因子,即,使得经过该激活函数后使得样本分布自动归一化到0均值和单位方差,网络具有自归一化功能。 其中,λ=1.050700987355480493419334985,α=1.67326324235437728481704299。

11、ELU (tf.nn.elu)激活函数

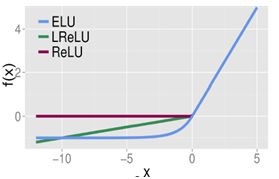
12、SeLU (tf.nn.selu)激活函数