kubernetes1.7如何部署elasticsearch7(使用本地PV,详细版,无坑版本)
前言
根据网络上的文章进行部署elasticsearch的时候发现了很多问题,现整理部署步骤,供大家学习.
一. 规划
由于涉及到很多内容,不进行规划,边做边规划,会导致混乱.
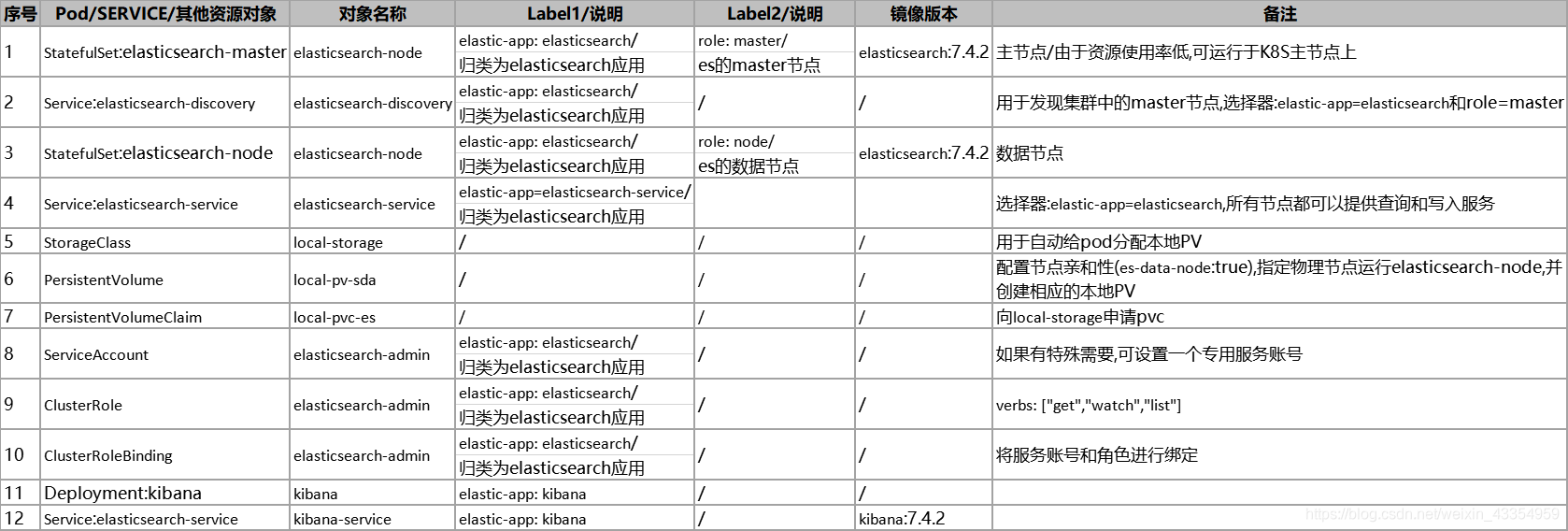
规划说明:
1.es的master节点至少需要三个,形成选举集群,防止脑裂.
2.master在配置中需要固定其主机名,所以需要使用StatefulSet.
3.node节点需要固定的主机名和固定的物理节点以及物理节点上的本地PV,所以需要使用StatefulSet,配合StorageClass来固定.
4.kibana为无状态服务,使用deployment.
二.镜像准备
2.1 拉取镜像
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2
注:需要配置阿里docker加速器(略),直接拉取镜像.
2.2 修改elasticsearch镜像
为什么要修改elasticsearch镜像,因为在部署elasticsearch的时候,建议配置memlock:true,这个要求系统必须配置ulimit.
经测试kubernetes并不支持配置系统的ulimit,通过 podStart 和 initContainer 都是无法生效。所以需要修改镜像,然其在容器内自动执行.
操作步骤如下.最终生成一个新的镜像elasticsearch:7.4.2-ulimit
[root@k8s-master dockerfile]# pwd
/root/dockerfile
[root@k8s-master dockerfile]# ll
-rw-r--r--. 1 root root 156 3月 5 16:28 Dockerfile
-rw-r--r--. 1 root root 98 3月 2 15:26 run.sh
### Dockerfile文件内容 ###
[root@k8s-master dockerfile]# vi Dockerfile
FROM elasticsearch:7.4.2
MAINTAINER dingyangzhuang [email protected]
COPY run.sh /
RUN chmod 775 /run.sh
CMD ["/run.sh"]
### 启动脚本内容 ###
[root@k8s-master dockerfile]# vi run.sh
#!/bin/bash
# 设置memlock无限制
ulimit -l unlimited
exec su elasticsearch /usr/local/bin/docker-entrypoint.sh
### 构建镜像 ###
[root@k8s-master dockerfile]# docker build --tag elasticsearch:7.4.2-ulimit
2.3 推送镜像到私有库–可选
由于K8S节点不能访问公网,需要经镜像推送到私有库,通过私有库获取镜像.
docker tag elasticsearch:7.4.2-ulimit 10.46.235.225:5000/elasticsearch:7.4.2-ulimit
docker tag kibana:7.4.2 10.46.235.225:5000/kibana:7.4.2
docker push 10.46.235.225:5000/elasticsearch:7.4.2-ulimit
docker push 10.46.235.225:5000/kibana:7.4.2
三.创建名字空间/服务账号
[root@node-1 elasticsearch]# cat namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: ns-elasticsearch
labels:
name: ns-elasticsearch
[root@node-1 elasticsearch]# cat serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
elastic-app: elasticsearch
name: elasticsearch-admin
namespace: ns-elasticsearch
[root@node-1 elasticsearch]# cat clusterrole.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: elasticsearch-admin
labels:
elastic-app: elasticsearch
rules: #根据需要配置相应的api/资源/权限
- apiGroups: [""]
resources: ["pods"]
verbs: ["get","watch","list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: elasticsearch-admin
labels:
elastic-app: elasticsearch
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: elasticsearch-admin
namespace: ns-elasticsearch
结果略
四.部署elasticsearch主节点
4.1 部署elasticsearch-master
[root@node-1 elasticsearch]# cat master-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
elastic-app: elasticsearch
role: master
name: elasticsearch-master
namespace: ns-elasticsearch
spec:
replicas: 3
serviceName: elasticsearch-discovery #用于给每一个pod提供一个podname.serviceName的域名进行访问.
selector:
matchLabels:
elastic-app: elasticsearch
role: master
template:
metadata:
labels:
elastic-app: elasticsearch
role: master
spec:
serviceAccountName: elasticsearch-admin
restartPolicy: Always
containers:
- name: elasticsearch-master
image: 10.46.235.225:5000/elasticsearch:7.4.2-ulimit #根据需要修改镜像
imagePullPolicy: IfNotPresent
securityContext:
privileged: true #获取root权限,这样才能进行初始化命令执行.
lifecycle:
postStart:#初始化命令,配置系统参数
exec:
command:
- /bin/bash
- -c
- sysctl -w vm.max_map_count=262144; ulimit -l unlimited;
ports: #开放端口一个是集群端口,一个是数据端口
- containerPort: 9200
protocol: TCP
- containerPort: 9300
protocol: TCP
env: #环境变量,非容器下在配置文件配置的,这里对应配置为环境变量就可以了
- name: cluster.name
value: "es_cluster"
- name: bootstrap.memory_lock
value: "true"
- name: node.master
value: "true"
- name: node.data
value: "false"
- name: discovery.seed_hosts
value: "elasticsearch-discovery"
- name: cluster.initial_master_nodes
value: "elasticsearch-master-0,elasticsearch-master-1,elasticsearch-master-2"
- name: node.ingest
value: "false"
- name: ES_JAVA_OPTS
value: "-Xms1g -Xmx1g"
tolerations: #使其可以运行在k8s主节点上
- effect: NoSchedule
key: node-role.kubernetes.io/master
4.2 elasticsearch-discovery-service
用于集群发现
[root@node-1 elasticsearch]# cat elasticsearch-discovery-service.yaml
kind: Service
apiVersion: v1
metadata:
labels:
elastic-app: elasticsearch
name: elasticsearch-discovery
namespace: ns-elasticsearch
spec:
ports:
- port: 9300
targetPort: 9300
selector:
elastic-app: elasticsearch
role: master
4.3 查看状态
[root@node-1 elasticsearch]# kubectl get pods -n ns-elasticsearch -o wide|grep master
elasticsearch-master-0 1/1 Running 0 8m25s 192.168.84.148 node-1 <none> <none>
elasticsearch-master-1 1/1 Running 0 8m42s 192.168.236.70 master-3 <none> <none>
elasticsearch-master-2 1/1 Running 0 8m48s 192.168.247.46 node-2 <none> <none>
[root@node-1 elasticsearch]# kubectl get svc -n ns-elasticsearch |grep elasticsearch-discovery
elasticsearch-discovery ClusterIP 10.107.14.26 <none> 9300/TCP 24h
[root@node-1 elasticsearch]#
五.部署elasticsearch数据节点
5.1 配置LocalPv
Local PV是从kuberntes 1.10开始引入,本质目的是为了解决hostPath的缺陷。通过PV控制器与Scheduler的结合,会对local PV做针对性的逻辑处理,从而,让Pod在多次调度时,能够调度到同一个Node上。
由于ES需要稳定的数据存储,所以我们使用LocalPV.
[root@node-1 elasticsearch]# cat pv.yaml
#使用StorageClass自动分配PV
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer #绑定模式为等待消费者,即当Pod分配到节点后,进行与PV的绑定
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-sda
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
local:
path: /data/pv #需要在指定的节点创建相应的目录
nodeAffinity: #指定节点,对节点配置label
required:
nodeSelectorTerms:
- matchExpressions:
- key: es-data-node
operator: In
values:
- "true"
persistentVolumeReclaimPolicy: Retain #回收策略为保留,不会删除数据,即当pod重新调度的时候,数据不会发生变化.
storageClassName: local-storage
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: local-pvc-es
namespace: ns-elasticsearch
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-storage
resources:
storage: 10Gi
5.3 es数据节点所在K8S节点配置
#配置K8S的label,用于选择节点调度ES
kubectl label nodes node-2 es-data-node=true
kubectl label nodes node-3 es-data-node=true
#在指定节点上创建目录,并给予权限
mkdir -p /data/pv
chmod 777 /data/pv #需要配置,否则容器没有写的权限
5.2 部署node-statefulset
[root@node-1 elasticsearch]# cat node-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
elastic-app: elasticsearch
role: node
name: elasticsearch-node
namespace: ns-elasticsearch
spec:
replicas: 2
serviceName: elasticsearch-service
selector:
matchLabels:
elastic-app: elasticsearch
role: node
template:
metadata:
labels:
elastic-app: elasticsearch
role: node
spec:
serviceAccountName: elasticsearch-admin
restartPolicy: Always
containers:
- name: elasticsearch-node
lifecycle:
postStart:
exec:
command: ["/bin/bash", "-c", "sysctl -w vm.max_map_count=262144; ulimit -l unlimited;"]
image: 10.46.235.225:5000/elasticsearch:7.4.2-ulimit
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
ports:
- containerPort: 9200
protocol: TCP
- containerPort: 9300
protocol: TCP
volumeMounts:
- name: esdata
mountPath: /usr/share/elasticsearch/data #需要localPV绑定到该目录,这个官方指定的容器内数据目录
env:
- name: cluster.name
value: "es_cluster"
- name: "bootstrap.memory_lock"
value: "true"
- name: node.master
value: "false"
- name: node.data
value: "true"
- name: discovery.seed_hosts
value: "elasticsearch-discovery"
- name: cluster.initial_master_nodes
value: "elasticsearch-master-0,elasticsearch-master-1,elasticsearch-master-2"
- name: node.ingest
value: "true"
- name: ES_JAVA_OPTS
value: "-Xms1g -Xmx1g"
volumes:
- name: esdata
persistentVolumeClaim:
claimName: local-pvc-es
5.4 创建elasticsearch-service
由于es集群可能需要外部系统访问,所以配置NodePort开放给外部系统.
[root@node-1 elasticsearch]# cat elasticsearch-service.yaml
kind: Service
apiVersion: v1
metadata:
labels:
elastic-app: elasticsearch-service
name: elasticsearch-service
namespace: ns-elasticsearch
spec:
ports:
- port: 9200
protocol: TCP
targetPort: 9200
selector:
elastic-app: elasticsearch
type: NodePort
5.4 查看状态
[root@node-1 elasticsearch]# kubectl get pods -n ns-elasticsearch -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
elasticsearch-master-0 1/1 Running 0 19m 192.168.84.148 node-1 <none> <none>
elasticsearch-master-1 1/1 Running 0 19m 192.168.236.70 master-3 <none> <none>
elasticsearch-master-2 1/1 Running 0 20m 192.168.247.46 node-2 <none> <none>
elasticsearch-node-0 1/1 Running 0 27m 192.168.247.44 node-2 <none> <none>
elasticsearch-node-1 1/1 Running 0 27m 192.168.139.112 node-3 <none> <none>
[root@node-1 elasticsearch]# kubectl get svc -n ns-elasticsearch
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-discovery ClusterIP 10.107.14.26 <none> 9300/TCP 24h
elasticsearch-service NodePort 10.98.25.204 <none> 9200:30432/TCP 19h
[root@node-1 elasticsearch]# curl -XGET "http://10.98.25.204:9200/_cluster/health?pretty"
[root@node-1 elasticsearch]# curl -XGET "http://10.98.25.204:9200/_cluster/health?pretty"
{
"cluster_name" : "es_cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 5,
"number_of_data_nodes" : 2,
"active_primary_shards" : 3,
"active_shards" : 6,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
#可以看到有三个数据节点
六. 部署kibana
6.1 部署kibana
[root@node-1 elasticsearch]# cat kibana-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
labels:
elastic-app: kibana
namespace: ns-elasticsearch
spec:
replicas: 1
selector:
matchLabels:
elastic-app: kibana
template:
metadata:
name: kibana
labels:
elastic-app: kibana
spec:
serviceAccountName: elasticsearch-admin
restartPolicy: Always
containers:
- name: kibana
image: 10.46.235.225:5000/kibana:7.4.2
imagePullPolicy: IfNotPresent
env:
- name: SERVER_NAME
value: "kibana"
- name: SERVER_HOST
value: "0.0.0.0"
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch-service.ns-elasticsearch:9200"
6.2 查看状态
[root@node-1 elasticsearch]# kubectl get pods -n ns-elasticsearch
NAME READY STATUS RESTARTS AGE
elasticsearch-master-0 1/1 Running 0 50m
elasticsearch-master-1 1/1 Running 0 50m
elasticsearch-master-2 1/1 Running 0 50m
elasticsearch-node-0 1/1 Running 0 19m
elasticsearch-node-1 1/1 Running 0 19m
kibana-577c9b79d5-4tc7p 1/1 Running 0 6s
[root@node-1 elasticsearch]# kubectl get svc -n ns-elasticsearch kibana-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kibana-service NodePort 10.107.234.57 <none> 5601:30313/TCP 19h
使用NodePort登录kibana

需要注意的一点是,如果集群中没有ingest节点,kibana收集监控信息会失败.解决方法就是将数据节点的ingest改为:true,或者修改一下配置
xpack.monitoring.exporters.my_local:
type: local
use_ingest: false
七. 附录
7.1 参考文档
关于elasticsearch的镜像和配置参数文档,如下网站可以获取.
https://www.docker.elastic.co/
7.2 问题点

八.后续–部署FileBeat,收集k8s日志
8.1 介绍
FileBeat是Elsatic Stack架构中轻量级采集工具,资源利用非常低.
8.2 拉取镜像
docker pull docker.elastic.co/beats/filebeat:7.4.2
有时候拉取会失败,这个想办法从其他地方获取,比如阿里云镜像源.
8.3 部署
需求:
1.需要在每一台K8S节点上部署FileBeat,所以使用DaemonSet.
2.需要拉取节点的/var/log ,/var/lib/docker/containers 两个日志文件
3.由于各个节点的FileBeat的配置都是一样的,所以我们将配置卸载ConfigMap,然后挂载给FileBeat容器.
4.主节点也要跑filebeat,所以要配置tolerations
1.下载配置模板
curl -L -O https://raw.githubusercontent.com/elastic/beats/7.4/deploy/kubernetes/filebeat-kubernetes.yaml
2.进行适当的修改
[root@node-1 filebeats]# cat filebeat-kubernetes.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: ns-elasticsearch
labels:
elastic-app: filebeat
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
# To enable hints based autodiscover, remove `filebeat.inputs` configuration and uncomment this:
#filebeat.autodiscover:
# providers:
# - type: kubernetes
# host: ${NODE_NAME}
# hints.enabled: true
# hints.default_config:
# type: container
# paths:
# - /var/log/containers/*${data.kubernetes.container.id}.log
processors:
- add_cloud_metadata:
- add_host_metadata:
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
username: ${ELASTICSEARCH_USERNAME}
password: ${ELASTICSEARCH_PASSWORD}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: ns-elasticsearch
labels:
elastic-app: filebeat
spec:
selector:
matchLabels:
elastic-app: filebeat
template:
metadata:
name: filebeat
labels:
elastic-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: 10.46.235.225:5000/filebeat:7.4.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch-service.ns-elasticsearch
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value:
- name: ELASTICSEARCH_PASSWORD
value:
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: varlog
mountPath: /var/log
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: ns-elasticsearch
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: ns-elasticsearch
labels:
elstic-app: filebeat
---
3.执行部署,查看状态
[root@node-1 log]# kubectl get pods -n ns-elasticsearch
NAME READY STATUS RESTARTS AGE
elasticsearch-master-0 1/1 Running 0 3d
elasticsearch-master-1 1/1 Running 0 3d
elasticsearch-master-2 1/1 Running 0 3d
elasticsearch-node-0 1/1 Running 0 2d22h
elasticsearch-node-1 1/1 Running 0 2d22h
filebeat-6gz65 1/1 Running 0 9m21s
filebeat-8q54z 1/1 Running 0 9m21s
filebeat-srl5k 1/1 Running 0 9m21s
filebeat-t666k 1/1 Running 0 9m21s
filebeat-z52tg 1/1 Running 0 9m21s
kibana-7ccb95584d-th94n 1/1 Running 0 2d22h
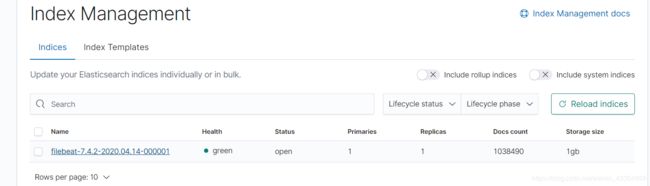
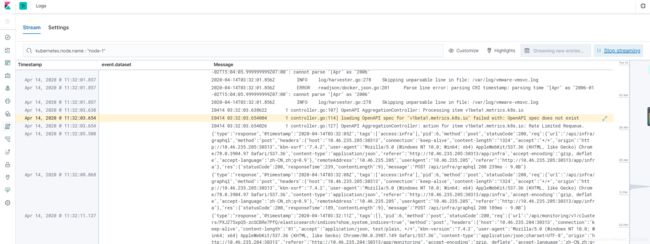
4.登录kibana查看日志
生成了一个filebeat的索引