利用Excel分析链家二手房数据
Excel分析链家二手房数据
本次数据分析旨在使用Excel工具分析网上爬取的链家北京而二手房数据,我们都知道爬虫爬取到的数据不出意外有很多都是混乱、错误、或者乱码的数据,所以这里使用Excel工具对数据进行清洗、整理、转换、构造等操作,同时还对数据进行可视化分析,最后采用python构建预测模型对二手房房价进行学习训练,并且预测房价。
首先导入数据:
可以从工具点击“数据”选项卡–>获取外部数据–>选择“自文本”选项
然后根据文本的特征选择相应的格式就行了
观察一下数据集,数据大体详情如下:

由于特征名看起来有点乱,可以将数据调成自己习惯观察的顺序,这里就不贴出具体操作了:
数据集一共有23677条数据,其中Elevator(电梯)特征有明显的缺失值
在Excel里有个快速填充缺失值的方法:快捷键Ctrl+G导出定位操作栏,选择定位位置和空值定位条件则会选完所有的缺失值,然后写入相应的填充值如(平均值,众数、中位数等),按Ctrl + Enter键即可全部填充完成。
不过本数据集的缺失值为类型数据,且考虑到生活中常见的房子特点,这里电梯缺失值填充方法为:将Floor(楼层)大于6层的填充为有电梯,小于或等于6层的为无电梯,可以利用函数实现:
将空值筛选出来,写入公式:IF(E2>6,“有电梯”,“无电梯”),将公式下拉填充所有缺失值,缺失值填充完成
现在暂时也看不出什么数据的异常值,可以先进行数据可视化分析,等发现异常值再处理:
首先可以看一下Price(房价)与Size(面积)的关系,这里用散点图进行分析:

通过图表可以观察得到:
- 发现 Size 特征基本与Price呈现线性关系,符合基本常识,面积越大,价格越高。但是有两组明显的异常点:1.面积不到10平米,但是价格超出1000万;2. 一个点面积超过了1000平米,价格很低,需要查看是什么情况。
筛选Size,选择Size小于10平米的数据来观察:
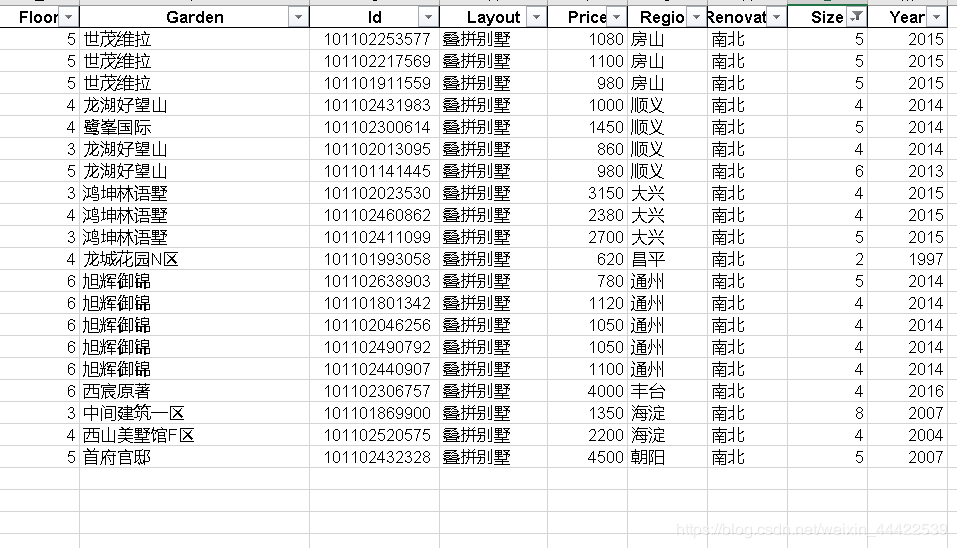
经过查看发现这组数据是别墅,出现异常的原因是由于别墅结构比较特殊(无朝向无电梯),字段定义与二手商品房不太一样导致爬虫爬取数据错位。也因别墅类型二手房不在我们的考虑范围之内,故将其移除再次观察Size分布和Price关系。
筛选Size,选择大于1000万的来观察:

经观察这个异常点不是普通的民用二手房,很可能是商用房,所以才有1房间0厅确有如此大超过1000平米的面积,这里选择移除。
再次观察图表:
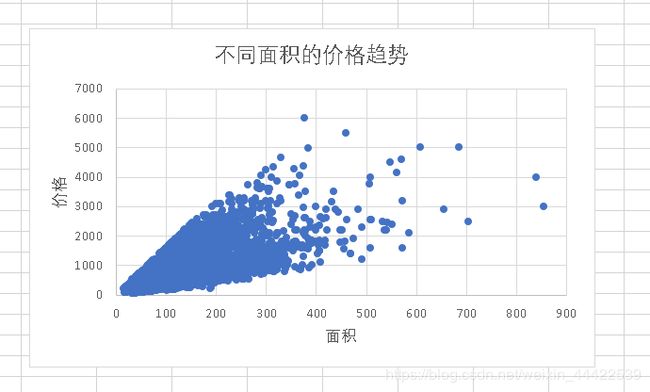
重新进行可视化发现就没有明显的异常点了。
接下来可以观察一下不同地区的价格是如何分布的:
这里可以添加一个特征,Perprice(每平米价格),直接用公式求即可,此外还需保留两位小数:Perprice=ROUND(Size/Price,2)
创建数据透视表–>选择地区作为行标签,每平米价格作为计算值,计算出各个地区的平均价格,绘制出相应的图表:
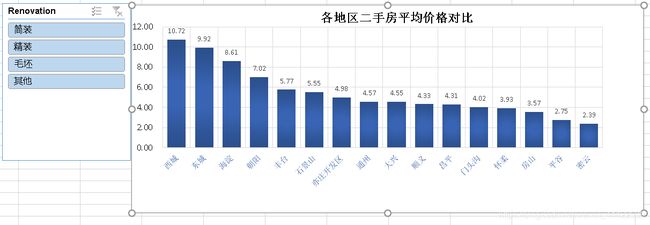
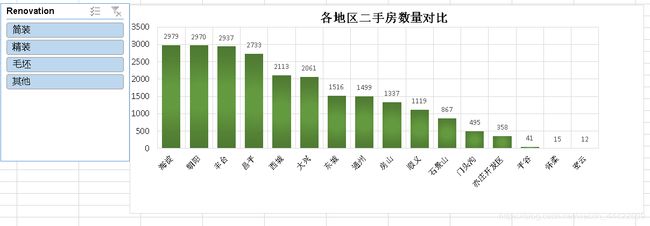
- 二手房均价:西城区的房价最贵均价大约11万/平,因为西城在二环以里,且是热门学区房的聚集地。其次是东城大约10万/平,然后是海淀大约8.5万/平,其它均低于8万/平。
- 二手房房数量:从数量统计上来看,目前二手房市场上比较火热的区域。海淀区和朝阳区二手房数量最多,差不多都接近3000套,毕竟大区,需求量也大。然后是丰台区,近几年正在改造建设,有赶超之势。
Layout(户型)分析:
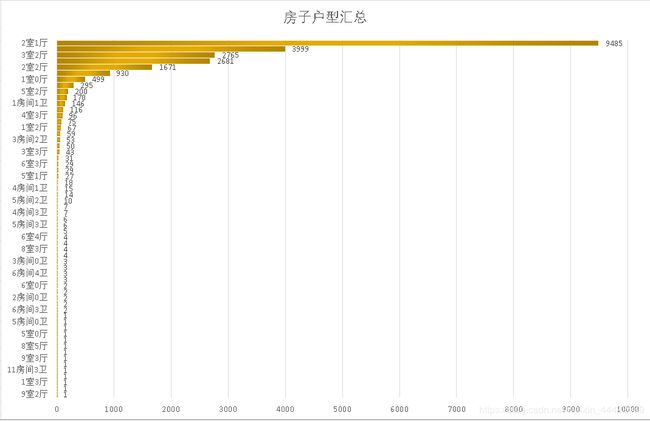
不看不知道,原来房子的户型这么多,不过平常我们都是说房子几房几厅或者几室几厅,很少会听到几房几卫,而且这里也大多数是几室几厅的类型的数据,所以为了统一数据格式和方便观察,需要需要使用特征工程进行相应的处理,现在先暂时不处理。
Renovation(装修程度) 特征分析
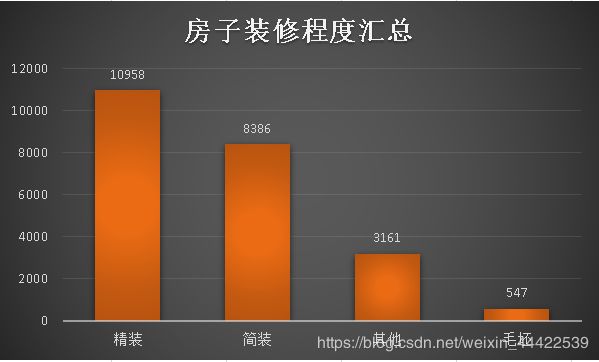
可以看到二手当中总体还是精装修比较多,简装修次之;
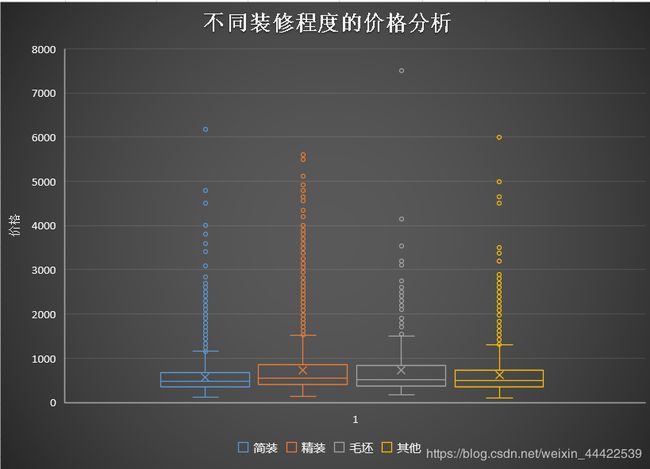
从装修程度与价格的箱式图来看:
- 对于价格来说:精装修价格比较高,其次反而是毛坯房。
Elevator(电梯) 特征分析
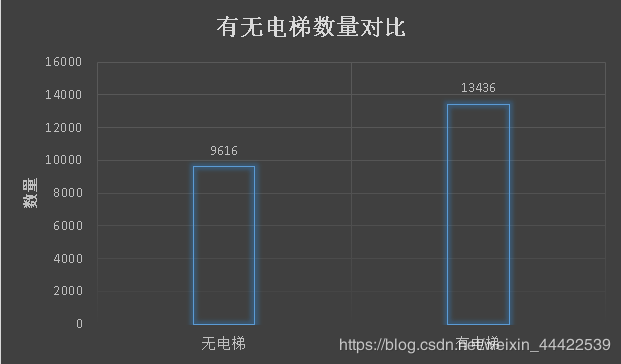
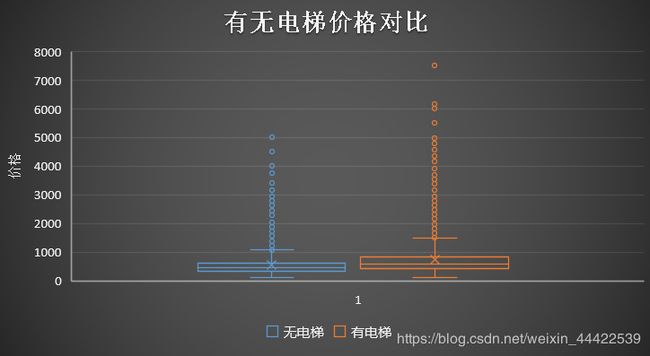
- 结果观察到,有电梯的二手房数量居多一些,毕竟高层土地利用率比较高,适合北京庞大的人群需要,而高层就需要电梯。相应的,有电梯二手房房价较高,因为电梯前期装修费和后期维护费包含内了(但这个价格比较只是一个平均的概念,比如无电梯的6层豪华小区当然价格更高了)。
Year(年份)特征分析:

图表采用年份做维度,分别绘制出不同装修程度价格随减分推移的价格趋势
从图中可以看出:
-
总体房价是随着年份的增长而上升的;
-
2000年以后建造的二手房房价相较于2000年以前有很明显的价格上涨;
-
从装修程度细分来看,精装修和简装修上升趋势最为明显,其他装修一般,而毛坯房必将趋于平稳,从侧面可以看出,房子装修成本也越来越高;
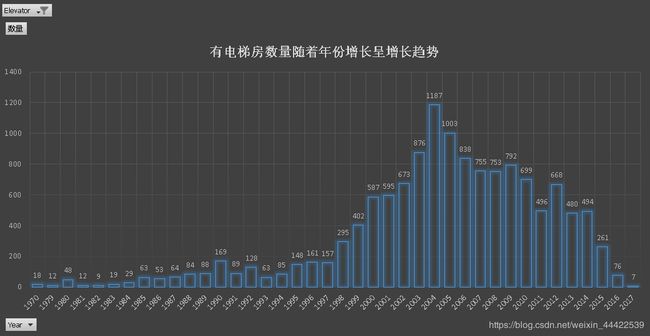

从以上两张图可以看出:
- 1980年之前几乎不存在有电梯二手房数据,说明1980年之前还没有大面积安装电梯;
- 2005年后有无电梯二手房的数量都出现了明显的降低,猜测应该是买二手房的人数增加,导致空置的二手房数量减少;
Floor(楼层)特征分析:

- 可以看到,6层二手房数量最多,但是单独的楼层特征没有什么意义,因为每个小区住房的总楼层数都不一样,我们需要知道楼层的相对意义。另外,楼层与文化也有很重要联系,比如中国文化七上八下,七层可能受欢迎,房价也贵,而一般也不会有4层或18层。当然,正常情况下中间楼层是比较受欢迎的,价格也高,底层和顶层受欢迎度较低,价格也相对较低。所以楼层是一个非常复杂的特征,对房价影响也比较大。
以上就是本次二手房数据的可视化分析,接下来需要做更多的特征工程处理,方便建立房价预测模型。
特征工程
- 特征工程包括的内容很多,有特征清洗,预处理,监控等,而预处理根据单一特征或多特征又分很多种方法,如归一化,降维,特征选择,特征筛选等等。这么多的方法,为的是什么呢?其目的是让这些特征更友好的作为模型的输入,处理数据的好坏会严重的影响模型性能,而好的特征工程有的时候甚至比建模调参更重要。
前面主要是做了两个特征工程:
缺失值填充:
- 根据楼层 Floor 来判断有无电梯,一般的楼层大于6的都有电梯,而小于等于6层的一般都没有电梯。
数据清洗:
- 移除结构类型异常值和房屋大小异常值:将房屋类型为别墅(Size<10)、Size>1000的数据筛选掉了;
接下来继续,在前面的户型数量汇总图中可以现,二手房户型种类比较多,各种厅室组合搭配,竟然还有9室3厅,4室0厅等奇怪的结构。其中,2室一厅占绝大部分,其次是3室一厅,2室2厅,3室两厅。但是仔细观察特征分类下有很多不规则的命名,比如2室一厅与2房间1卫,还有别墅,没有统一的叫法。这样的特征肯定是不能作为机器学习模型的数据输入的,需要使用特征工程进行相应的处理。这里可以把数据统一成几室几厅的类型,由于数据量还是比较大的,可以将不符合类型的去掉。
具体操作如下:
新建一列:M列,在M2输入公式:=IF(RIGHT(H2,1)=“厅”,True,False),然后下拉填充即可
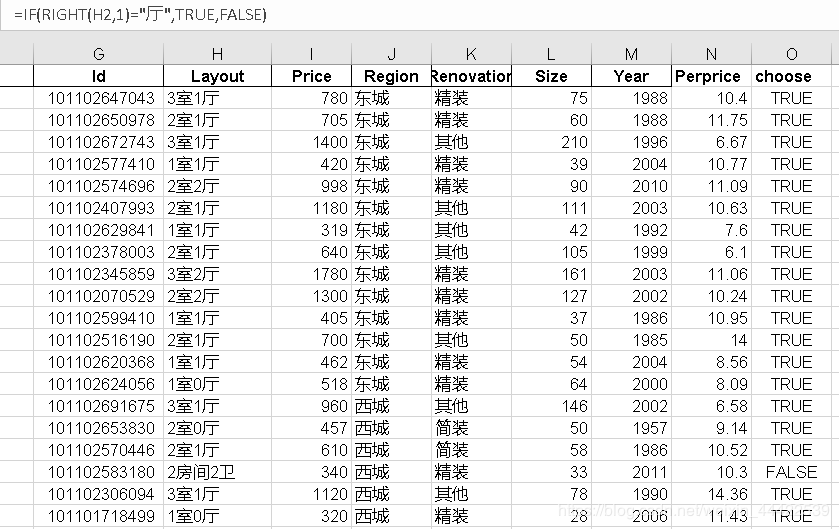
接着筛选O列,将为False的数据删除掉

提取“室”和“厅”创建新特征
操作如下:
新建两列Layout_room_num(房间数)、Layout_hall_num(客厅数),分别输入公式:=LEFT(H2,1) 、=MID(H2,3,1)
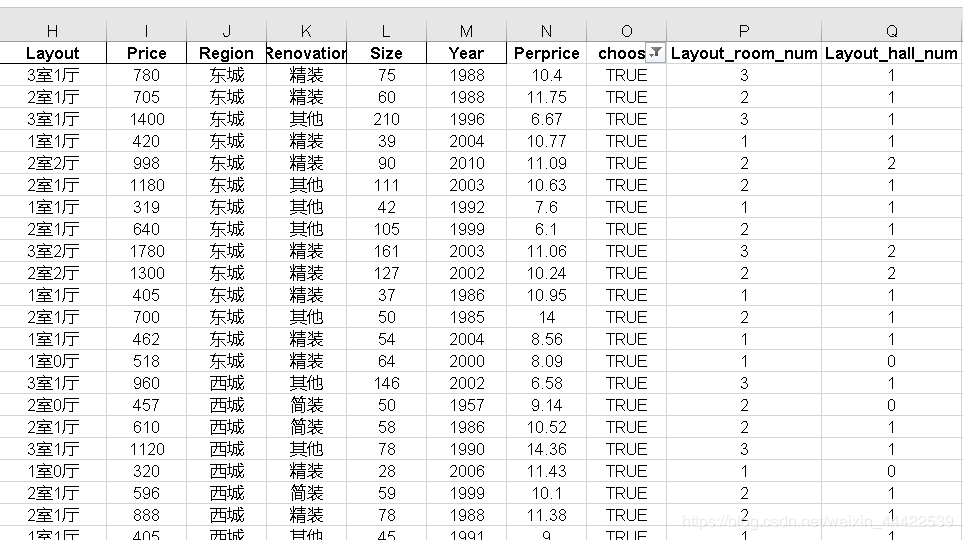
根据已有特征构建新特征
Layout_total_num(总房间数)= Layout_room + Layout_hall_num、
Size_room_ratio(房间平均面积)= Size / Layout_total_num
删除无用特征
Layout、PerPrice、Garden
Year特征处理:
- 我们还有一个 Year 特征,为建房的年限时间。年限种类很多,分布在1950和2018之间,如果每个不同的 Year
值都作为特征值,我们并不能找出 Year 对 Price 有什么影响,因为年限划分的太细了。因此,我们只有将连续数值型特征 Year
离散化,做分箱处理。
根据各个时间段的二手房数量来分析,个人认为可以将年份分为8个区间:如下图所示:
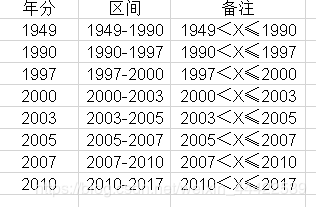
具体操作如下:
将上图的数据创建出来,然后新建一列Year_label,利用VLOOKUP函数匹配出新特征
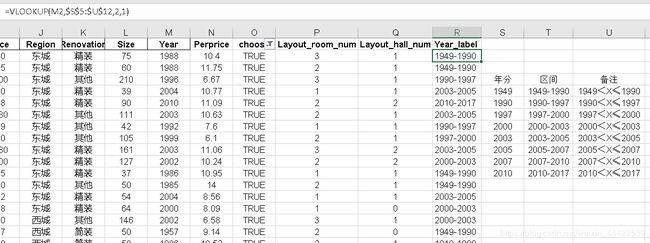
最后删除掉Year特征
还剩下一些特征工程因为使用Excel来操作很复杂,难于实现,所以以下将采用python的pandas模块来进行操作,同时也要在python上建立随机森林预测模型来预测房价的价格。
将数据整理保存为csv格式,然后在Jupyter notebook环境下导入数据进行操作。
Direction特征处理:
1.导入数据
import pandas as pd
data= pd.read_csv('C:\\Users\\Master\\Desktop\\lianjia.csv')
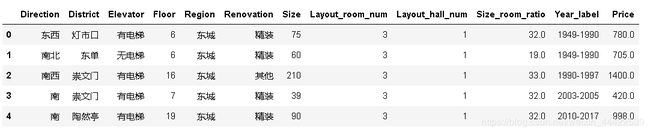
#观察数据
data.head()
输出:
2.查看Direction特征:
data.Direction.value_counts()
输出:
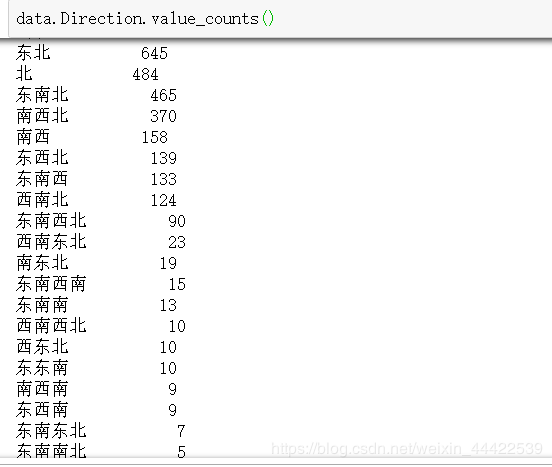
由于各种朝向都有,非常之多,所以这里只能贴出一小部分,但是这些在链家的信息上就是这样,没办法,为了是预测准确,这里需要将他们进行处理;
代码如下:
#两个字的以此为准
d_list_two = ['东西','东南','东北','西南','西北','南北']
#三个字的以此为准
d_list_three = ['东西南','东西北','东南北','西南北']
#四个字的朝向毫无疑问只能是东南西北了
for i in range(data.shape[0]):
list_data = []
for d in data.iloc[i,0]:
list_data.append(d)
list_data = set(list_data)
if len(list_data) >= 4:
data.iloc[i,0] = '东西南北'
if len(list_data) == 2:
for str1 in d_list_two:
n_list = [a for a in list_data if a in str1]
if len(n_list) == 2:
data.iloc[i,0] = str1
break
if len(list_data) == 3:
for str1 in d_list_three:
n_list = [a for a in list_data if a in str1]
if len(n_list) == 2:
data.iloc[i,0] = str1
break
#再看一下数据:
data.Direction.value_counts()
输出:
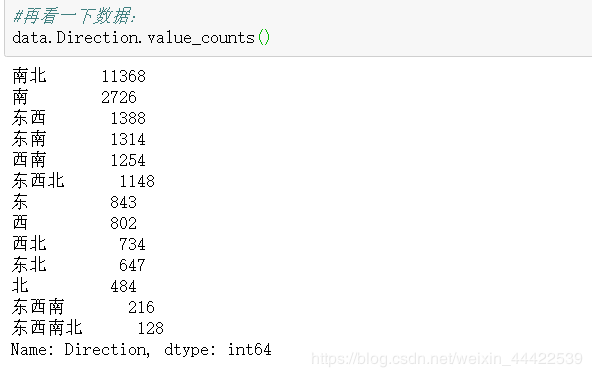
是不是感觉清爽了很多。。。
One-hot coding
最后的特征工程就剩下 One-hot 独热编码了,因为像 Region,Year(离散分箱后),Direction,Renovation,Elevator等特征都是定类的非数值型类型,而作为模型的输入我们需要将这些非数值量化。
由于这里的操作用Excel来实现很是复杂,所以这里依然是用python来完成这一部分的操作
# 对于object特征进行onehot编码
data1 = pd.get_dummies(data)
data1.head()
输出:
一步到位,是不是很简单,好了,特征工程暂时到这里就告一段落了,接下来就是模型的构建了。
构建模型
1.导入相关的模块
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
2.构建训练数据和测试数据:
X = data1.loc[:,data1.columns != 'Price']
y = data1.loc[:, data1.columns == 'Price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
3.训练数据并预测
rf_Model = RandomForestRegressor(n_estimators=1000,random_state=42)
rf_Model.fit(X_train, y_train.values.ravel())
y_pred = rf_Model.predict(X = X_test)
4.使用R2评分来给模型打分
from sklearn.metrics import r2_score
score = r2_score(y_test, y_pred)
print(score)
输出:
0.8885695774040159
R2决定系数(拟合优度):
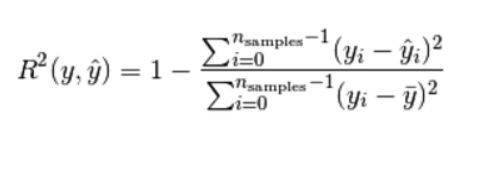
模型越好:r2→1
模型越差:r2→0
呼,到这里就大功告成了。
总结
这就是本次的数据分析与挖掘项目全部流程,说是使用Excel,后面又偷偷用了python,还是不够专业,且因为没有明确的需求目标,所以相关分析不仔细、深入,并且没能合成分析报告;可提升改进的地方非常多,可以有更好更健壮的方案代替,一些改进思考如下:
- 获取更多有价值的特征信息,比如学区,附近地铁,购物中心等
- 完善特征工程,如进行有效的特征选择
- 使用更优秀的模型算法建模或者使用模型融合