Spark的集群搭建
Spark的集群搭建
1.前提条件
1.1创建3台虚拟机,且配置好网络,建立好互信。
1.2 Java1.8环境已经配置好
1.3 Hadoop2.8.5几圈已经完成搭建
1.4 Scala软件包和Spark软件包的下载
https://www.scala-lang.org/download/
http://spark.apache.org/downloads.html
2.安装Scala
2.1解压安装包:tar -zxvf scala-2.13.0.tgz
2.2 配置环境变量
vi /etc/profile
export SCALA_HOME=/usr/hadoop/scala/scala-2.13.0
export PATH= P A T H : PATH: PATH:SCALA_HOME/bin
退出使立即生效:[root@master]source /etc/profile
3.验证安装
[root@master data]# scala
Welcome to Scala 2.13.1 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161).
Type in expressions for evaluation. Or try :help.
scala>
4.安装spark
1)创建 /usr/hadoop/spark目录
2)下载后解压,到/usr/hadoop/spark目录下。
- /etc/profile配置
spark install export SPARK_HOME=/usr/hadoop/spark/spark-2.4.3-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin
2) spark-env.sh配置
[root@master]# cd /usr/hadoop/spark/spark-2.4.3-bin-hadoop2.7/conf
[root@master]# vi spark-env.sh
#添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_161
export SCALA_HOME=/usr/local/scala/scala-2.13.1
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_HOST=master
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/usr/local/spark/spark-2.4.4-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
- slaves配置
slave1 slave2
- 复制到其他节点
在master节点上安装配置完成Spark后,将整个spark目录拷贝到其他节点,并在各个节点上更新/etc/profile文件中的环境变量
- 测试Spark
-
在master节点启动Hadoop集群
-
在master节点启动spark
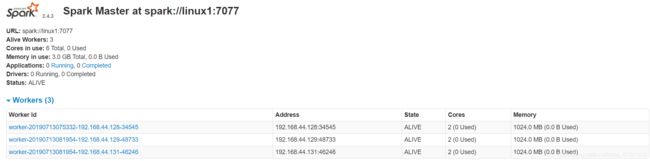
[root@master spark-2.4.3-bin-hadoop2.7]# sbin/start-all.sh打开浏览器输入192.168.xx.xx:8080,看到如下活动的Workers,证明安装配置并启动成功:
5.进入spark shell
进入spark的bin目录,启动spark-shell控制台
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
6.测试spark-shell
看下之前在hdfs上穿的文件,随便找一个,或者再传一个
val readmeFile = sc.textFile("hdfs://master:9000/dict/test01")
readmeFile.count
得到结果Long = 内容长度
var theCount = readmeFile.filter(line=>line.contains("the"))
theCount.count
得到单词the的个数
7.Hadoop下wordcount功能
scala> var wordCount = readmyfile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
wordCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[6] at reduceByKey at :25
//flatMap:对集合中每个元素进行操作然后再扁平化。
//map:对集合中每个元素进行操作。
wordCount.collect
8.Spark的高可用部署
8.1 配置
# 1.安装Zookeeper
# 2.修改spark-env.sh文件添加如下配置
注释掉如下内容:
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
添加上如下内容:
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop1,hadoop2,hadoop3
-Dspark.deploy.zookeeper.dir=/spark"
# 在hadoop102上启动全部节点
$ sbin/start-all.sh
# 在hadoop103上单独启动master节点
$ sbin/start-master.sh
8.2测试
bin]$./spark-shell –master spark://master:7077,slave1:7077,slave2:7077
在master->spark中
[root@master sbin]# pwd
/usr/local/spark/spark-2.4.4-bin-hadoop2.7/sbin
[root@master sbin]# ./stop-master.sh
stopping org.apache.spark.deploy.master.Master