hive 基本指令命令
1.show databases 查看有那些数据库

2.创建park数据库,实际上hadoop的HDFS文件系统里创建一个目录节点,统一存在/usr/hive/wareshouse目录下
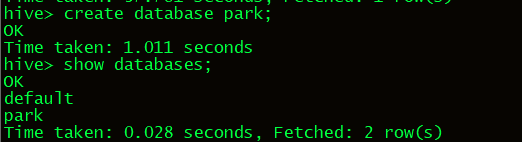
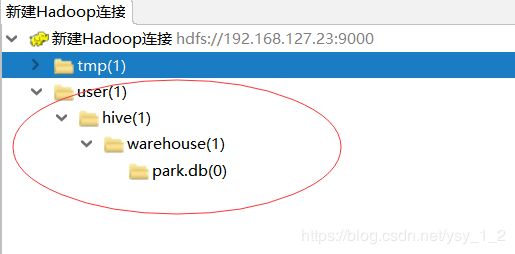
3.进入数据库

4.查看当前数据库下的所有表

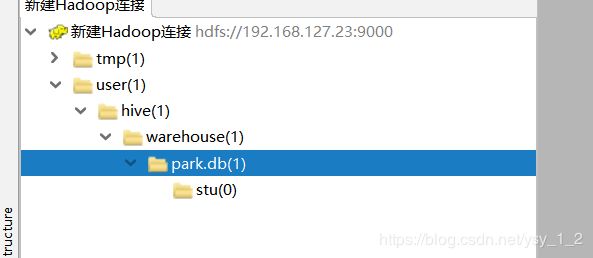
5.创建stu表,以及相关的两个字段

在hive中,用的是string,不用char和varchar,此外,所创建的表,也是HDFS里的一个目录节点。
在hive里面有一个default数据库,这个hdfs目录结构上是看不到的,凡是在default数据库下建立的表,都直接存在warehouse目录下.
6.向stu表插入数据
HDFS不支持数据的修改和删除,在2.0版本后支持了数据最加,使用insert into语句执行的最加操作.
hive支持查询,行级别的插入,不支持行级别的删除和修改.
hive的操作实际是执行job任务,调用的是hadoop的MR.
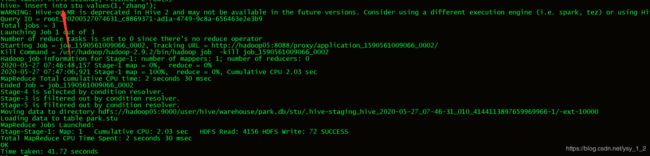
插入完后,我们可以发现DHFS stu目录下,多了一个文件,文件里存了插入的数据,所以得出结论,hive存储的数据,是通过HDFS的文件来存储的.
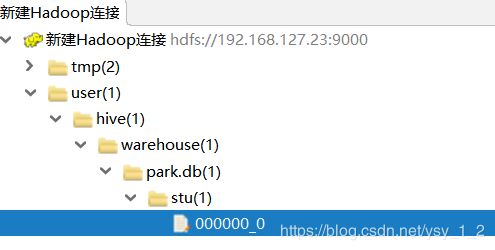
7.查看表的数据,也可以用字段来查询select id from stu

8.删除表stu
drop table stu
9.创建stu1表,并指定分割符空格.
![]()
把外部数据导入hive,这样就可以正确查出数据了.

10.查询stu表结构

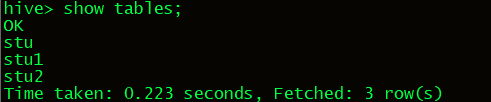
11.创建一张stu2表,表结构和stu表结构相同,like只复制表结构,不复制数据

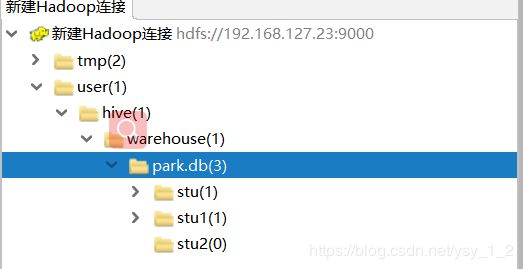
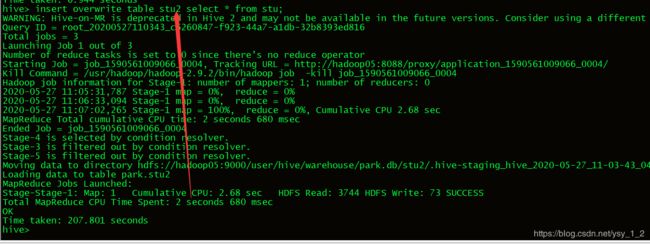
12.把stu表数据插入到stu2表中,insert overwrite可用将select查询出的数据插入到指定的表中或指定的目录下如:
把查询结果存在本地的目录下,
执行:insert overwrite local directory ‘/home/stu’ row format delimited fields terminated by’’ select * from stu;
也可以将查询结果存到HDFS文件系统上
执行:insert overwrite directory ‘/stu’ row format delimited fields terminated by’’ select * from stu;
也可以将查询结果插入到多张表中
执行:from stu insert overwrite table stu1select * insert overwrite table stu2 select *;
结果是把stu表的数据插入stu1和stu2表.(也可以加where条件等,比如select * where id>3)
13.为表重新命令,将stu重新命名为stu3.
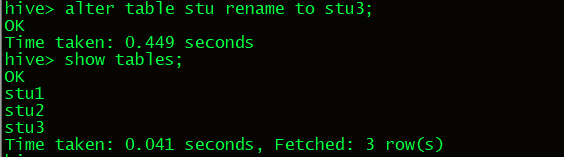
14.为表stu1增加一个列字段age,类型为int

你可以连接数据库查看表的信息.
DBS存放的原数据信息
TBL存放的tables表信息
COLUMNS存放的是列字段信息.
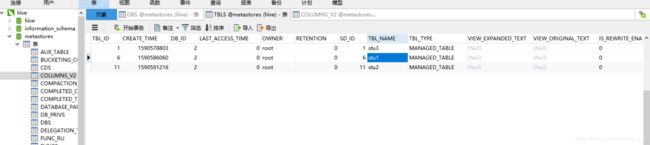
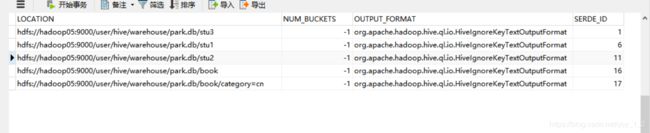
此外,可以通过查看SDS表来查询HDFS里的位置信息.

15.hive的内部表和外部表
在查看原数据信息时,有一张TBLS表,其中有一个字段属性:TBL_TYPE—MANAGED_TABLE,MANAGED_TABLE表示内部表.

15.1内部表的概念
先在hive里创建一张表,然后向这个表插入数据(用insert可以插入数据,也可以通过加载外部文件方式来插入数据),这样称之为hive的内部表.
15.2外部表的概念
HDFS里已经有数据了,比如有一个1.txt文件,里面存储这样的一些数据:
1 jary
2 rose
然后,通过hive创建一张表stu来管理这个文件数据,则stu这样表称为外部表,注意,hive外部表管理的是HDFS里的某个目录下的文件数据.
创建外部表的命令
create external table stu (id int,name string) row format delimited fields terminated by ’ ’ location ‘/data’
hive无论是内部表或外部表,当向HDFS对应的目录节点下追加文件时(只要符合格式),hive都可以把数据管理进来.
16.内部表和外部表的区别.
通过hive执行:drop table stu,这时删除表操作,如果stu是一个内部表,则HDFS对应的目录节点会被删除.
如果stu是一个外部表,HDFS对应的目录节点不会删除.
17.Hive分区表
hive也支持分区表,对数据进行分区可以提高查询时的效率.
普通表和分区表区别:有大量数据增加的需要建分区表.
执行:create table book (id int, name string) partitioned by(categorystring ) row format delimited fields terminated by ‘’;
注:在创建分区表时,partitioned字段可以不在字段列表中,生成的表中自动就会具有该字段.
![]()
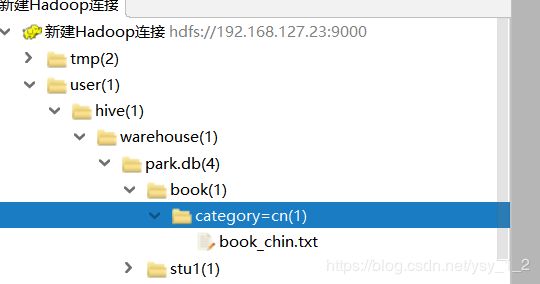
分区表加载数据
load data local inpath ‘/usr/wenjian/book_chin.txt’ overwrite into table book partition(category=‘cn’);
经检查发现分区也是一个目录.
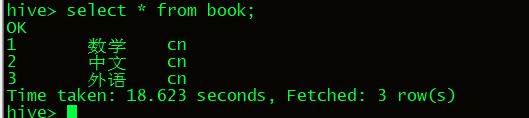
查询book目录下的所有数据
select * from book;
只查询cn分区的数据;
select * from book where category=‘cn’;只查询cn分区的数据
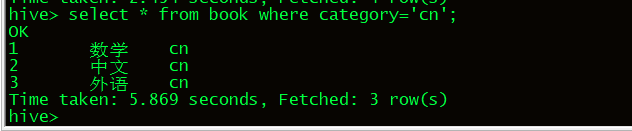
还可以通过mysql的SDS来查询原数据.
18.如果想在HDFS的目录下,自己创建一个分区,然后在此目录下上传文件,比如:
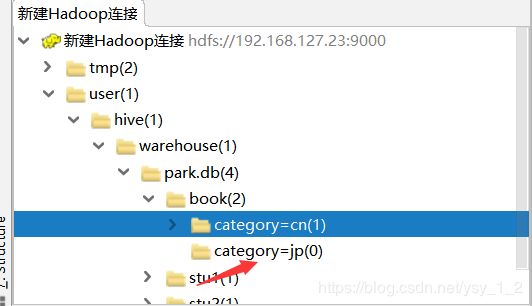
此时的手动目录时无法被hive使用的,因为原数据库中没有记录该分区.
如果需要自己创建的分区被识别,需要执行
ALTER TABLE book add PARTITION (category = ‘jp’) location ‘/user/hive/warehouse/park.db/book/category=jp’;
![]()
这行命令的作用是在原数据Dock表里创建对应的原数据信息.

删除分区

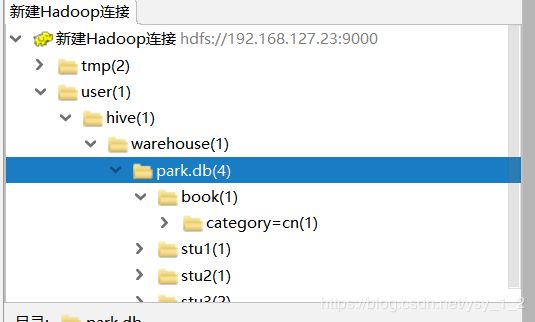
修改分区
alter table book partition(category=‘cn’) rename to partition (category=‘nn’);