ELK安装过程记录,监听netflow和sflow的配置文件编写
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大也就是日志量多而复杂的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
Elastic Stack包含:
- Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。详细可参考Elasticsearch权威指南
- Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
- Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比
Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
1、Elasticsearch安装
注意:在公司服务器上安装东西时,注意开通网络权限,不然在安装时会很难受
下载 elasticsearch-6.1.2.tar.gz,保存在/usr/elk/路径下,并用解压,es解压即可用,无需安装
tar -xzf elasticsearch-6.1.2.tar.gz
设置配置文件 config/elasticsearch.yml
network.host: 0.0.0.0 # 监听全部ip,在实际环境中应设置为一个安全的ip
http.port: 9200 # es服务的端口号
因为es不允许root用户启动,此时需要创建一个普通用户。所以建议给Elasticsearch单独创建一个用户来运行Elasticsearch,并授权
# 以root用户来创建新的用户 , groupadd 添加一个用户组
groupadd elasticsearch
# 添加一个用户,-g是在用户组下 -p是密码
useradd elasticsearch -g elasticsearch -p elasticsearch
# 进入es的安装目录
cd /usr/elk/elasticsearch
# 给用户elasticsearch 授权
chown -R elasticsearch:elasticsearch elasticsearch-6.1.2/
# 切换到 elasticsearch 用户
su elasticsearch
启动es
cd /usr/elk/elasticsearch
bin/elasticsearch #或者 ./bin/elasticsearch
还可以用curl命令来验证,curl -X GET http://localhost:9200/ 或者curl “ip:9200”
如果启动时候有其他报错,请看该链接https://my.oschina.net/codingcloud/blog/1615013
2、logstash安装
同样,解压logstash-7.2.0.tar.gz,并打开主目录
tar -xf logstash-7.2.0.tar.gz
cd logstash-7.2.0/bin
运行longstash
./logstash -f sample.conf #可root权限。
测试CSV文件
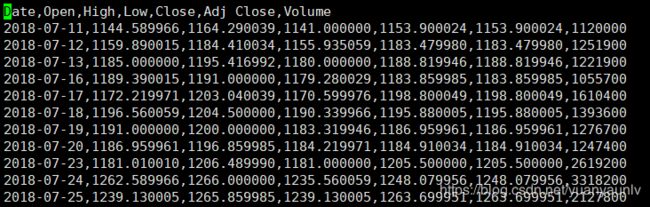
测试logstash读取过滤csv文件,例如 New01.csv 文件如下所示。
在logstash-7.2.0/bin 目录下创建 logstash.conf 文件
input {
file {
path => "/usr/elk-install/test01/New01.csv" #文件的目录
start_position => "beginning" #起始位置
}
}
filter {
csv {
separator => ","
columns => ["date_record","open","high"]
}
mutate {
rename => { "[host][name]" => "host" }
convert => ["open","float"]
convert => ["high","float"]
#convert => ["low","float"]
#convert => ["close","float"]
}
date{ #日期转换
match => ["date_record", "yyyy-MM-dd"]
target => "@timestamp"
}
}
output { #输出到elasticsearch保存
elasticsearch {
hosts => ["10.252.125.31:9200"] #elasticsearchip(服务器ip)
index =>"new-01" #指定elasticsearc的索引,该索引不会重复创建,当文件发生变化时候,索引内容自动更新。
#action => "index"
}
stdout {#输出到屏幕
}
}
测试netflow
利用flowalyzer.exe软件模拟netflow流,并编写了 logstash-nflow.conf 如下

input {
syslog {
port => 9991
type => "netflow"
codec => netflow {
versions => [5, 9]
}
type => "netflow"
}
}
filter {
if "netflow" = type {
mutate {
rename => { "ipv4_src_addr" => "src_ip" }
rename => { "ipv4_dst_addr" => "dst_ip" }
rename => { "l4_src_port" => "src_port" }
rename => { "l4_dst_port" => "dst_port" }
convert => ["ipv4_src_addr","string"]
convert => ["ipv4_dst_addr","string"]
convert => ["l4_src_port","integer"]
convert => ["l4_dst_port","integer"]
}
}
}
output {
elasticsearch {
hosts => ["10.252.125.31:9200"]
index => "nTestflow-test01"
#protocol => "http"
#action => "index"
}
stdout {
}
}
测试sflow流,本次通过交换机丢数据给我的logstash端口
input {
syslog {
host => "10.252.125.31" #修改对应的ip
#host => "logstash.host"
port => 6543 #之前是9996 测试成功但是未做编码转换
codec => sflow{}
type => "sflow"
}
}
filter {
mutate {
rename => { "[frame_length]" => "frame_length_bytes" }
rename => { "[input_interface_value]" => "input_value" }
rename => { "[output_interface_value]" => "output_value" }
convert => ["frame_length_bytes","integer"]
convert => ["input_value","integer"]
convert => ["output_value","integer"]
}
}
output {
elasticsearch {
hosts => ["10.252.125.31:9200"]
index => "sflow-lvyy01"
#action => "index"
}
stdout {
# codec => rubydebug
}
}
3、kibana安装
同样的,下载 kibana.tar.gz 并且解压并安装 x-pack
tar -xf kibana**.tar.gz
cd kibana**/bin
./kibana-plug install x-pack
编辑配置文件 config/kibaba.yml
server.host: "10.252.125.31"
elasticsearch.hosts: "http://10.252.125.31:9200"
启动kibana,以普通用户elasticsearch 身份。
cd kibana**/bin
./kibana
在网址输入 10.252.125.31:5601 即可访问kibana。
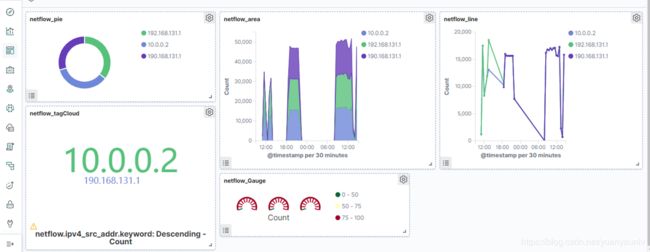
创建dashboard仪表盘,如图所示。