在上篇文章中主要是讲述了一些理论性的知识,然后从这篇文章开始 就一步步讲述实战的内容。
起因是因为机器学习我需要收集各个年份全省份的地方政府工作报告的文本,前一阵子还需要收集1950年以来所有的政府工作报告(中央政府),那一次我是一个个手动地复制粘贴过来的,不过这一次我肯定不会像上次那么傻,2003年到2016年(发生时)有14年,有三十多个省份,会有四百多份报告,一份报告至少得花费打开,复制,新建,粘贴,重命名 五次操作,那将会是二千余次手动机械化的操作,我才不干呢,然后我就想到了爬虫。
然后就边学边做,制作起了爬虫。
上篇说道,爬虫的基本结构是
请求,解析,和存储。
那么就按照这个结构一步步制作爬虫。
请求
urllib2是Python 针对网页访问以及本地文件访问的一个自带的的库,是Python的一个获取URLs(Uniform Resource Locators)的组件,以urlopen函数的形式提供了一个非常简单的接口。
我们通常用这个库来提交请求。
一个简单的提交请求的例子
import urllib2
response = urllib2.urlopen('http://www.baidu.com /')
处理http消息,urlib2也可先构造一个Request对象,之后调用urlopen函数,接收返回的response对象并进行相关处理,这个也更像浏览器提交请求的方式
import urllib2
req = urllib2.Request('http://www.baidu.com')
response = urllib2.urlopen(req)
page = response.read()
通过从汇总 2016年地方政府工作报告汇编 http://www.gov.cn/guoqing/2016-02/21/content_5044277.htm
可以随便浏览到北京政府2016年政府工作报告http://www.gov.cn/guoqing/2016-02/06/content_5042961.htm
也就是把上面的地址替换为一下
import urllib2
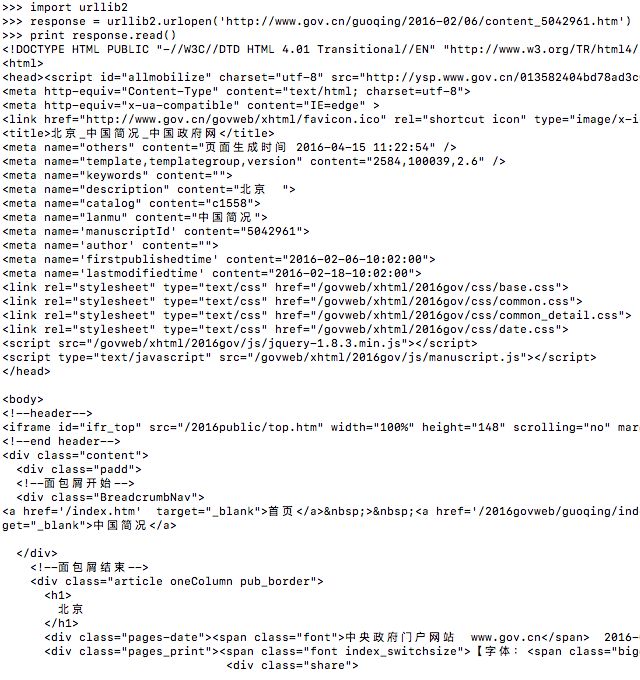
response = urllib2.urlopen('http://www.gov.cn/guoqing/2016-02/06/content_5042961.htm')
print response.read()
然后运行后的源码发现与网页源码相同,那么接下来就是解析的工作了。

解析
对网页内容的源码进行解析
接下来是解析,解析的方法我采用过两种方法,对于正则表达式上篇有提到,我认为的正则表达式的查找更倾向于位置的搜素,而这个位置我们需要通过对网页源码解析后才能得到。
通过谷歌浏览器自带的开发工具,通过审查元素我们可以发现我们想要的数据几乎都在P标签里
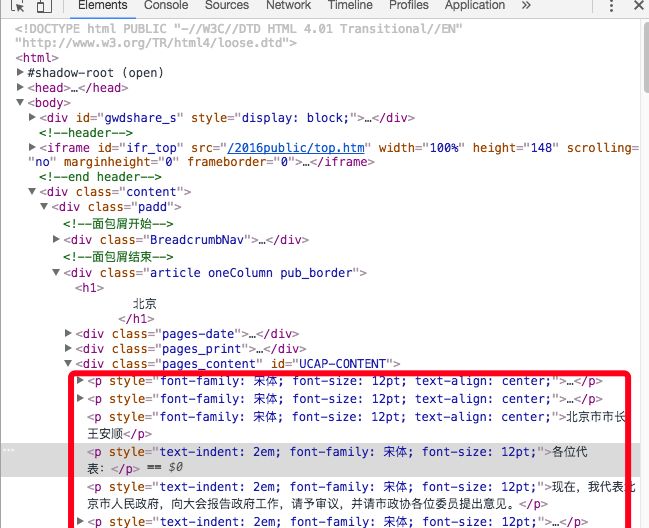
对于提取P标签的正则表达式 我的匹配代码是
re.findall('(.*?[\u4e00-\u9fa5]*?.*?)', page)
这样的话,P标签的所有内容将会被定位爬取到。
稍微解释一下,这个正则表达式的意思是提取对于所有在P标签范围内的所有Unicode的中文字符。
存储
re.findall()的返回值是一个列表,我们可以将查找的信息通过遍历输出到屏幕上
url = "http://www.gov.cn/guoqing/2016-02/06/content_5042961.htm"
page = urllib2.urlopen(url).read().decode("utf8").replace(' ', '').replace('', '').replace('', '').replace('', '')
myitems = re.findall('(.*?[\u4e00-\u9fa5]*?.*?)', page)
for line in myitems:
print line
输出结果

然后,一篇政府工作报告已经爬取完了,但是我要一个个输入网页的话这也太麻烦了,
那我该怎样自动地爬取同一年份的所有省份的工作报告呢,下一篇就会回顾下这个问题。
关于学习urllib2的教程我推荐 http://blog.csdn.net/pleasecallmewhy/article/details/8923067
关于学习正则表达式 我推荐 http://blog.csdn.net/pleasecallmewhy/article/details/8929576