| (1)hadoop2.7.1源码编译 | http://aperise.iteye.com/blog/2246856 |
| (2)hadoop2.7.1安装准备 | http://aperise.iteye.com/blog/2253544 |
| (3)1.x和2.x都支持的集群安装 | http://aperise.iteye.com/blog/2245547 |
| (4)hbase安装准备 | http://aperise.iteye.com/blog/2254451 |
| (5)hbase安装 | http://aperise.iteye.com/blog/2254460 |
| (6)snappy安装 | http://aperise.iteye.com/blog/2254487 |
| (7)hbase性能优化 | http://aperise.iteye.com/blog/2282670 |
| (8)雅虎YCSBC测试hbase性能测试 | http://aperise.iteye.com/blog/2248863 |
| (9)spring-hadoop实战 | http://aperise.iteye.com/blog/2254491 |
| (10)基于ZK的Hadoop HA集群安装 | http://aperise.iteye.com/blog/2305809 |
1.Hadoop集群方式介绍
1.1 hadoop1.x和hadoop2.x都支持的namenode+secondarynamenode方式

优点:搭建环境简单,适合开发者模式下调试程序
缺点:namenode作为很重要的服务,存在单点故障,如果namenode出问题,会导致整个集群不可用
1.2.仅hadoop2.x支持的active namenode+standby namenode方式
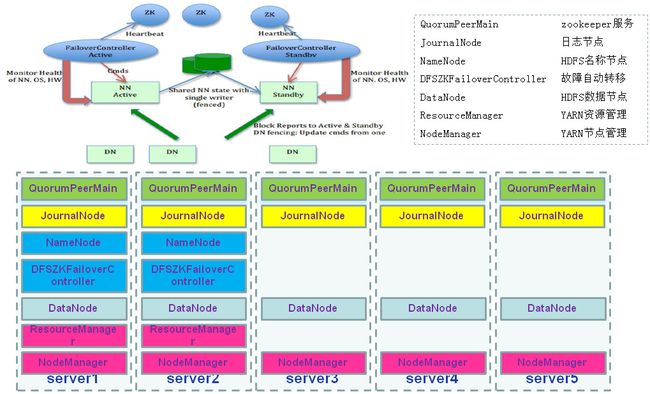
优点:为解决1.x中namenode单节点故障而生,充分保障Hadoop集群的高可用
缺点:需要zookeeper最少3台,需要journalnode最少三台,目前最多支持2台namenode,不过节点可以复用,但是不建议
1.3 Hadoop官网关于集群方式介绍
1)单机Hadoop环境搭建
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
2)集群方式
集群方式一(hadoop1.x和hadoop2.x都支持的namenode+secondarynamenode方式)
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/ClusterSetup.html
集群方式二(仅hadoop2.x支持的active namenode+standby namenode方式,也叫HADOOP HA方式),这种方式又分为HDFS的HA和YARN的HA单独分开讲解。
HDFS HA(zookeeper+journalnode)http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
HDFS HA(zookeeper+NFS)http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailability
YARN HA(zookeeper)http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
生产环境多采用HDFS(zookeeper+journalnode)(active NameNode+standby NameNode+JournalNode+DFSZKFailoverController+DataNode)+YARN(zookeeper)(active ResourceManager+standby ResourceManager+NodeManager)方式,这里我讲解的是仅hadoop2.x支持基于zookeeper的Hadoop HA集群方式,这种方式主要适用于生产环境。
2.基于zookeeper的Hadoop HA集群安装
2.1 安装环境介绍

2.2 安装前准备工作
1)关闭防火墙
systemctl start firewalld.service
#centos7重启firewall
systemctl restart firewalld.service
#centos7停止firewall
systemctl stop firewalld.service
#centos7禁止firewall开机启动
systemctl disable firewalld.service
#centos7查看防火墙状态
firewall-cmd --state
#开放防火墙端口
vi /etc/sysconfig/iptables-config
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 6379 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 6380 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 6381 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 16379 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 16380 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 16381 -j ACCEPT
这里我关闭防火墙,root下执行如下命令:
systemctl disable firewalld.service
2)优化selinux
作用:Hadoop主节点管理子节点是通过SSH实现的, SELinux不关闭的情况下无法实现,会限制ssh免密码登录。
编辑/etc/selinux/config,修改前:
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=enforcing
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
修改后:
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
#SELINUX=enforcing
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
#SELINUXTYPE=targeted
执行以下命令使selinux 修改立即生效:
3)机器名配置
作用:Hadoop集群中机器IP可能变化导致集群间服务中断,所以在Hadoop中最好以机器名进行配置。
修改各机器上文件/etc/hostname,配置主机名称如下:
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.185.31 hadoop31
192.168.185.32 hadoop32
192.168.185.33 hadoop33
192.168.185.34 hadoop34
192.168.185.35 hadoop35
而centos7下各个机器的主机名设置文件为/etc/hostname,以hadoop31节点主机配置为例,配置如下:
hadoop31
4)创建hadoop用户和组
作用:后续单独以用户hadoop来管理Hadoop集群,防止其他用户误操作关闭Hadoop 集群
groupadd hadoop
useradd -g hadoop hadoop
#修改用户密码
passwd hadoop
5)用户hadoop免秘钥登录
作用:Hadoop中主节点管理从节点是通过SSH协议登录到从节点实现的,而一般的SSH登录,都是需要输入密码验证的,为了Hadoop主节点方便管理成千上百的从节点,这里将主节点公钥拷贝到从节点,实现SSH协议免秘钥登录,我这里做的是所有主从节点之间机器免秘钥登录
ssh hadoop31
su hadoop
#生成非对称公钥和私钥,这个在集群中所有节点机器都必须执行,一直回车就行
ssh-keygen -t rsa
#通过ssh登录远程机器时,本机会默认将当前用户目录下的.ssh/authorized_keys带到远程机器进行验证,这里是/home/hadoop/.ssh/authorized_keys中公钥(来自其他机器上的/home/hadoop/.ssh/id_rsa.pub.pub),以下代码只在主节点执行就可以做到主从节点之间SSH免密码登录
cd /home/hadoop/.ssh/
#首先将Master节点的公钥添加到authorized_keys
cat id_rsa.pub>>authorized_keys
#其次将Slaves节点的公钥添加到authorized_keys,这里我是在Hadoop31机器上操作的
ssh [email protected] cat /home/hadoop/.ssh/id_rsa.pub>> authorized_keys
ssh [email protected] cat /home/hadoop/.ssh/id_rsa.pub>> authorized_keys
ssh [email protected] cat /home/hadoop/.ssh/id_rsa.pub>> authorized_keys
ssh [email protected] cat /home/hadoop/.ssh/id_rsa.pub>> authorized_keys
#必须设置修改/home/hadoop/.ssh/authorized_keys权限
chmod 600 /home/hadoop/.ssh/authorized_keys
#这里将Master节点的authorized_keys分发到其他slaves节点
scp -r /home/hadoop/.ssh/authorized_keys [email protected]:/home/hadoop/.ssh/
scp -r /home/hadoop/.ssh/authorized_keys [email protected]:/home/hadoop/.ssh/
scp -r /home/hadoop/.ssh/authorized_keys [email protected]:/home/hadoop/.ssh/
scp -r /home/hadoop/.ssh/authorized_keys [email protected]:/home/hadoop/.ssh/
6)JDK安装
作用:Hadoop需要java环境支撑,而Hadoop2.7.1最少需要java版本1.7,安装如下:
su hadoop
#下载jdk-7u65-linux-x64.gz放置于/home/hadoop/java并解压
cd /home/hadoop/java
tar -zxvf jdk-7u65-linux-x64.gz
#编辑vi /home/hadoop/.bashrc,在文件末尾追加如下内容
export JAVA_HOME=/home/hadoop/java/jdk1.7.0_65
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#使得/home/hadoop/.bashrc配置生效
source /home/hadoop/.bashrc
很多人是配置linux全局/etc/profile,这里不建议这么做,一旦有人在里面降级了java环境或者删除了java环境,就会出问题,建议的是在管理Hadoop集群的用户下面修改其.bashrc单独配置该用户环境变量
7)zookeeper安装
su hadoop
cd /home/hadoop
tar -zxvf zookeeper-3.4.6.tar.gz
#2在集群中各个节点中配置/etc/hosts,内容如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.185.31 hadoop31
192.168.185.32 hadoop32
192.168.185.33 hadoop33
192.168.185.34 hadoop34
192.168.185.35 hadoop35
#3在集群中各个节点中创建zookeeper数据文件
ssh hadoop31
cd /home/hadoop
#zookeeper数据存放位置
mkdir -p /opt/hadoop/zookeeper
ssh hadoop32
cd /home/hadoop
#zookeeper数据存放位置
mkdir -p /opt/hadoop/zookeeper
ssh hadoop33
cd /home/hadoop
#zookeeper数据存放位置
mkdir -p /opt/hadoop/zookeeper
ssh hadoop34
cd /home/hadoop
#zookeeper数据存放位置
mkdir -p /opt/hadoop/zookeeper
ssh hadoop35
cd /home/hadoop
#zookeeper数据存放位置
mkdir -p /opt/hadoop/zookeeper
#4配置zoo.cfg
ssh hadoop31
cd /home/hadoop/zookeeper-3.4.6/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
#内容如下
initLimit=10
syncLimit=5
dataDir=/opt/hadoop/zookeeper
clientPort=2181
autopurge.snapRetainCount=3
#单位为小时,每小时清理一次快照数据
autopurge.purgeInterval=1
server.1=hadoop31:2888:3888
server.2=hadoop32:2888:3888
server.3=hadoop33:2888:3888
server.4=hadoop34:2888:3888
server.5=hadoop35:2888:3888
#5在hadoop31上远程复制分发安装文件
scp -r /home/hadoop/zookeeper-3.4.6 hadoop@hadoop32:/home/hadoop/
scp -r /home/hadoop/zookeeper-3.4.6 hadoop@hadoop33:/home/hadoop/
scp -r /home/hadoop/zookeeper-3.4.6 hadoop@hadoop34:/home/hadoop/
scp -r /home/hadoop/zookeeper-3.4.6 hadoop@hadoop35:/home/hadoop/
#6在集群中各个节点设置myid必须为数字
ssh hadoop31
echo "1" > /opt/hadoop/zookeeper/myid
ssh hadoop32
echo "2" > /opt/hadoop/zookeeper/myid
ssh hadoop33
echo "3" > /opt/hadoop/zookeeper/myid
#7.各个节点如何启动zookeeper
ssh hadoop31
/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start
#8.各个节点如何关闭zookeeper
ssh hadoop31
/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh stop
#9.各个节点如何查看zookeeper状态
ssh hadoop31
/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh status
#10.各个节点如何通过客户端访问zookeeper上目录数据
ssh hadoop31
/home/hadoop/zookeeper-3.4.6/bin/zkCli.sh -server hadoop31:2181,hadoop32:2181,hadoop33:2181,hadoop34:2181,hadoop35:2181
2.3 Hadoop HA安装
1)hadoop-2.7.1.tar.gz
ssh hadoop31
su hadoop
cd /home/hadoop
tar –zxvf hadoop-2.7.1.tar.gz
2)core-site.xml
修改配置文件/home/hadoop/hadoop-2.7.1/etc/hadoop/core-site.xml
fs.trash.interval 1440 fs.defaultFS hdfs:// bigdatacluster-ha io.file.buffer.size 131072 hadoop.tmp.dir /opt/hadoop/tmp ha.zookeeper.quorum hadoop31:2181,hadoop32:2181,hadoop33:2181,hadoop34:2181,hadoop35:2181 ha.zookeeper.session-timeout.ms 300000 io.compression.codecs org.apache.hadoop.io.compress.SnappyCodec
3)hdfs-site.xml
修改配置文件/home/hadoop/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
dfs.nameservices bigdatacluster-ha dfs.datanode.du.reserved 107374182400 dfs.ha.namenodes.bigdatacluster-ha namenode1,namenode2 dfs.namenode.rpc-address.bigdatacluster-ha.namenode1 hadoop31:9000 dfs.namenode.http-address.bigdatacluster-ha.namenode1 hadoop31:50070 dfs.namenode.rpc-address.bigdatacluster-ha.namenode2 hadoop32:9000 dfs.namenode.http-address.bigdatacluster-ha.namenode2 hadoop32:50070 dfs.namenode.shared.edits.dir qjournal://hadoop31:8485;hadoop32:8485;hadoop33:8485;hadoop34:8485;hadoop35:8485/bigdatacluster-ha dfs.client.failover.proxy.provider.bigdatacluster-ha org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /home/hadoop/.ssh/id_rsa dfs.journalnode.edits.dir /opt/hadoop/journal dfs.ha.automatic-failover.enabled true dfs.namenode.name.dir file:/opt/hadoop/hdfs/name dfs.datanode.data.dir file:/opt/hadoop/hdfs/data dfs.replication 3 dfs.webhdfs.enabled true ha.zookeeper.quorum hadoop31:2181,hadoop32:2181,hadoop33:2181,hadoop34:2181,hadoop35:2181 dfs.namenode.handler.count 600 The number of server threads for the namenode. dfs.datanode.handler.count 600 The number of server threads for the datanode. dfs.client.socket-timeout 600000 dfs.datanode.max.transfer.threads 409600
4)mapred-site.xml
修改配置文件/home/hadoop/hadoop-2.7.1/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.job.maps
12
mapreduce.job.reduces
12
mapreduce.output.fileoutputformat.compress
true
Should the job outputs be compressed?
mapreduce.output.fileoutputformat.compress.type
RECORD
If the job outputs are to compressed as SequenceFiles, how should
they be compressed? Should be one of NONE, RECORD or BLOCK.
mapreduce.output.fileoutputformat.compress.codec
org.apache.hadoop.io.compress.SnappyCodec
If the job outputs are compressed, how should they be compressed?
mapreduce.map.output.compress
true
Should the outputs of the maps be compressed before being
sent across the network. Uses SequenceFile compression.
mapreduce.map.output.compress.codec
org.apache.hadoop.io.compress.SnappyCodec
If the map outputs are compressed, how should they be
compressed?
5)yarn-site.xml
修改配置文件/home/hadoop/hadoop-2.7.1/etc/hadoop/yarn-site.xml
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
259200
yarn.resourcemanager.connect.retry-interval.ms
2000
yarn.resourcemanager.zk-address
hadoop31:2181,hadoop32:2181,hadoop33:2181,hadoop34:2181,hadoop35:2181
yarn.resourcemanager.cluster-id
besttonecluster-yarn
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop31
yarn.resourcemanager.hostname.rm2
hadoop32
yarn.resourcemanager.webapp.address.rm1
hadoop31:8088
yarn.resourcemanager.webapp.address.rm2
hadoop32:8088
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.ha.automatic-failover.embedded
true
yarn.resourcemanager.ha.automatic-failover.zk-base-path
/yarn-leader-election
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
6)slaves
修改配置文件/home/hadoop/hadoop-2.7.1/etc/hadoop/slaves
Hadoop32
Hadoop33
Hadoop34
Hadoop35
7)hadoop-env.sh和yarn-env.sh
在/home/hadoop/hadoop-2.7.1/etc/hadoop/hadoop-env.sh和/home/hadoop/hadoop-2.7.1/etc/hadoop/yarn-env.sh中配置JAVA_HOME
8)bashrc
当前用户hadoop生效,在用户目录下/home/hadoop/.bashrc增加如下配置
export PATH=${HADOOP_HOME}/bin:${PATH}
9)分发安装文件到其他机器
scp -r /home/hadoop/hadoop-2.7.1 hadoop@hadoop32:/home/hadoop/
scp -r /home/hadoop/hadoop-2.7.1 hadoop@ hadoop33:/home/hadoop/
scp -r /home/hadoop/hadoop-2.7.1 hadoop@ hadoop34:/home/hadoop/
scp -r /home/hadoop/hadoop-2.7.1 hadoop@ hadoop35:/home/hadoop/
2.4 Hadoop HA初次启动
1)启动zookeeper
/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start
ssh hadoop32
/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start
ssh hadoop33
/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start
ssh hadoop34
/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start
ssh hadoop35
/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start
#jps查看是否有QuorumPeerMain 进程
#/home/hadoop/zookeeper-3.4.6/ bin/zkServer.sh status查看zookeeper状态
#/home/hadoop/zookeeper-3.4.6/ bin/zkServer.sh stop关闭zookeeper
2)格式化zookeeper上hadoop-ha目录
#可以通过如下方法检查zookeeper上是否已经有Hadoop HA目录
# /home/hadoop/zookeeper-3.4.6/bin/zkCli.sh -server hadoop31:2181,hadoop32:2181,hadoop33:2181,hadoop34:2181,hadoop35:2181
#ls /
3)启动namenode日志同步服务journalnode
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start journalnode
ssh hadoop32
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start journalnode
ssh hadoop33
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start journalnode
ssh hadoop34
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start journalnode
ssh hadoop35
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start journalnode
4)格式化namenode
ssh hadoop31
/home/hadoop/hadoop-2.7.1/bin/hdfs namenode -format
5)启动namenode、同步备用namenode、启动备用namenode
ssh hadoop31
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start namenode
#同步备用namenode、启动备用namenode
ssh hadoop32
/home/hadoop/hadoop-2.7.1/bin/hdfs namenode -bootstrapStandby
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start namenode
6)启动DFSZKFailoverController
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start zkfc
ssh hadoop32
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemon.sh start zkfc
7)启动datanode
ssh hadoop31
/home/hadoop/hadoop-2.7.1/sbin/hadoop-daemons.sh start datanode
8)启动yarn
ssh hadoop31
/home/hadoop/hadoop-2.7.1/sbin/start-yarn.sh
#在hadoop31上启动备用resouremanager
ssh hadoop32
/home/hadoop/hadoop-2.7.1/sbin/yarn-daemon.sh start resourcemanager
至此,Hadoop 基于zookeeper的高可用集群就安装成功,并且启动了。