这个事情的背景是公司的Hadoop生态集群都是原生的,不是基于CDH的,所以基本所有的东西都需要自己手动管理,比如集群修改一些属性,然后批量分发重启或者动态生效之类的。这次也算不上事故,因为没对生产环境造成什么影响,但是差一点就变成事故,写出来分享一下。
事情简单概括就是,60+台hadoop的集群,每一个DataNode的硬盘数量都不相同,正常情况下集群的配置是在NameNode上面改完,然后rsync或者scp等工具直接分发到其他datanode上面。不过这次就是因为有人修改了datanode相关的配置,然后批量分发了这个被他修改过的hdfs-site.xml文件,导致所有的datanode上面的磁盘配置全都被覆盖了,此时此刻集群还没停,急需把原来的磁盘配置给还原回来,配置没做备份,所以只能从其他角度入手。在我一边点击hdfs的50070页面一边想的时候,我觉得web页面上能看到的东西,一定可以通过命令行拿到,尤其是类似节点属性这种比较常用的选项,节点属性相关就一定跑不掉数据盘的配置,我就按照之前的动态生效配置命令的查找思路(思路点击这里),又去查了一下获取节点属性相关的命令,简直so easy,我找到了下面这个
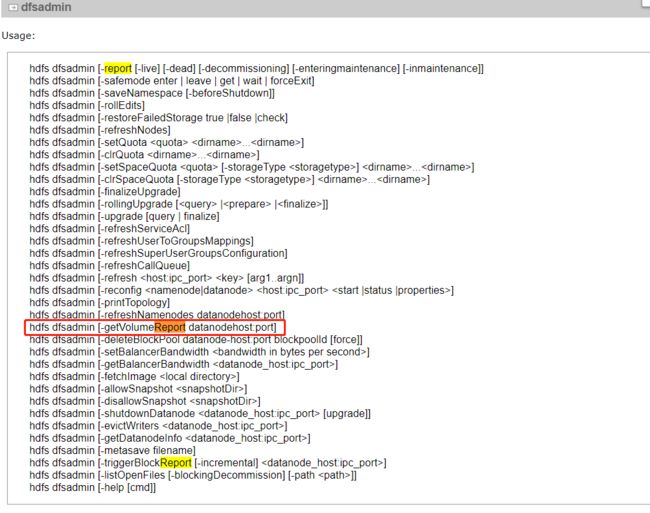
赶紧命令行走一波看看,下图所示:
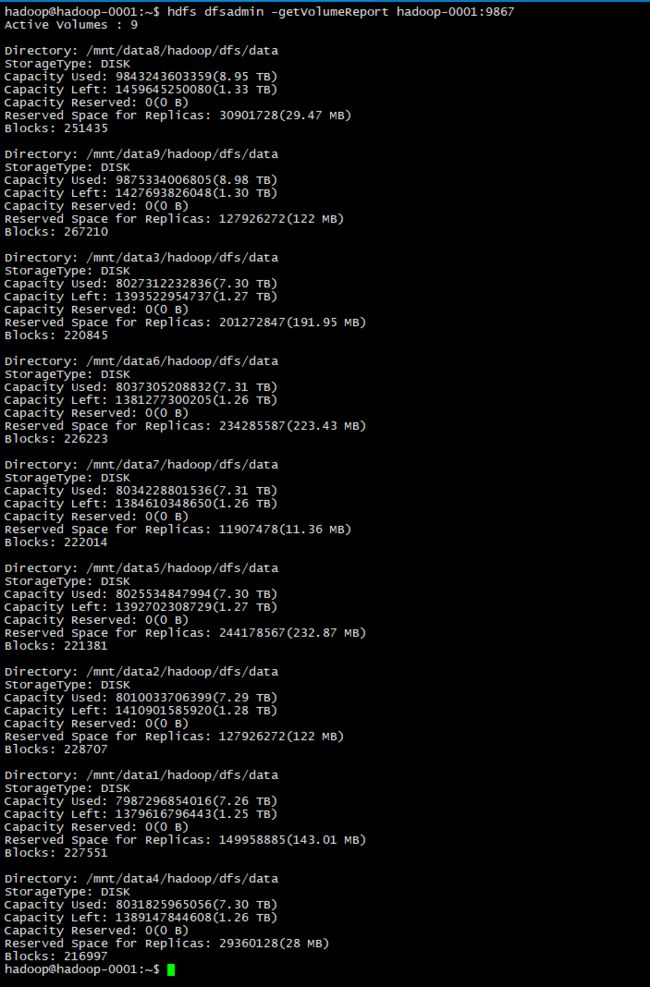
这里的/mnt/dataXXXXX,就是我hdfs-site.xml里面dfs.datanode.data.dir的配置。
所以对这个结果通过Linux脚本来做一些处理(为了方便读,我加了"\"换行):
op@op-01:~$sudo -u hadoop /opt/hadoop-3.1.2/bin/hadoop dfsadmin -getVolumeReport hadoop-0001:9867 \
|grep Directory|awk -F " " '{print $NF}'\
|sed ":a;N;s/\n/,/g;ta"
处理完了就得到了下面的结果:
op@op-01:~$sudo -u hadoop /opt/hadoop-3.1.2/bin/hadoop dfsadmin -getVolumeReport hadoop-0001:9867 |grep Directory|awk -F " " '{print $NF}'|sed ":a;N;s/\n/,/g;ta" WARNING: Use of this script to execute dfsadmin is deprecated. WARNING: Attempting to execute replacement "hdfs dfsadmin" instead. /mnt/data8/hadoop/dfs/data,/mnt/data9/hadoop/dfs/data,/mnt/data3/hadoop/dfs/data,/mnt/data6/hadoop/dfs/data,/mnt/data7/hadoop/dfs/data,/mnt/data5/hadoop/dfs/data,/mnt/data2/hadoop/dfs/data,/mnt/data1/hadoop/dfs/data,/mnt/data4/hadoop/dfs/data op@op-01:~$
上面加下划线的那一行就是我最后要拿到的,每台datanode的磁盘配置,现在要把它写到hdfs-site.xml里面的话,需要在上面的结果添加"
1 HADOOP_HOME=/opt/hadoop-3.1.2 2 HADOOP_CONF=${HADOOP_HOME}/etc/hadoop 3 HOSTNAME="hadoop-0012" 4 PORT=9867 5 6 ${HADOOP_HOME}/bin/hadoop dfsadmin -getVolumeReport ${HOSTNAME}:${PORT}|grep Directory|awk -F" " '{print $2}'>>${HADOOP_CONF}/disk_info 7 8 sed -i ":a;N;s/\n/,/g;ta" ${HADOOP_CONF}/disk_info #将命令行获取的volume结果存储到这里 9 sed -i -e 's@^@&@g ' -e 's@$@&@g' ${HADOOP_CONF}/disk_info #将处理结果前后添加xml的标签和 10 sed -i '/dfs.datanode.data.dir/{n;d}' ${HADOOP_CONF}/hdfs-site.xml #先将已有的行删掉 11 sed -i "/dfs.datanode.data.dir/r ${HADOOP_CONF}/disk_info" ${HADOOP_CONF}/hdfs-site.xml #将新的配置追加到这一行的后面
到这里,单台机器的配置文件修复就算完成了,不过格式化我没研究,就是替换完的结果有点丑,没有做xml的格式化,如下(图片看不清的话右键图片新标签页打开就好了):
不过不影响使用就是了,下面就是集群批量修复,使用一个自动化运维工具叫Ansible
没有的话可以安装一下:
hadoop@op-01:~$ sudo apt-get install ansible -y
详细使用我就不讲了,自行百度哈
上面的脚本第三行HOSTNAME那里,每台机器需要自行获取自己的HOSTNAME,所以脚本第三行修改成下面这样
HOSTNAME=$(hostname)
将脚本分发到每台机器上:
op@op-01:~$ansible hadoop-cluster -m copy -a \ "src=/tmp/repair_hadoop_disk.sh \ #从哪里 dest=/opt/hadoop-3.1.2/bin/ \ #分发到哪里 owner=hadoop \ #脚本所有者是谁 group=hadoop \ #脚本所有者所在的组是哪个组 backup=no" \ #如果遇到重名的文件,是否备份 -b \ #是否用root权限 -f 20 #fork,多少线程同时执行
这里我把这个repaid_hadoop_disk.sh放在了hadoop的bin下面,作为hadoop的修复工具使用,然后就是执行:
ansible hadoop-cluster -m shell -a "bash /opt/hadoop-3.1.2/bin/repair_hadoop_disk.sh" -b -f 20
到此,修复完成,不过强迫症看着修复完的配置文件没缩进确实难受,以后再修复吧
至于ansible的用法,我本人是精通的,碍于主题和篇幅,我就暂时不写了