机器学习之一线性回归分析
线性回归就是利用已知的数据样本,产生你和方程,从而对未知数据进行预测的过程,主要用于预测与判别合理性等方向
本章节我们主要讨论一元线性、多元线性、广义线性(也叫Logistic回归)等问题,下章节我们主要讨非线性回归、梯度下降等知识
关系概念
函数关系:确定性关系,y=a+bx
相关关系:非确定性关系
相关系数: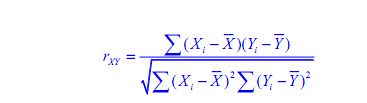
参数:截距a,斜率b误差项e
一元线性回归模型
若x与y之间存在着较强的相关性关系,我们有:Y≈a +bX+e,若a与b的值都已知,可以根据相应的X值预测出Y的预测值。
如何确定这几个参数呢?
我们知道,确定参数一定会有一个衡量标准的,这个衡量标准一般使用误差平方和,简单来说就是使用平方误差和衡量预测值h和真实值的差距,看一下示例图(盗用的别人的):
在上图的方程简单解释一下,中间的线就是拟合的线,就是基于数据点到回归线的距离之和,求其所有距离并求和,计算最小值的过程,在这个过程中我们可以使用误差距离的误差平方和进行衡量,就是求真实值与预测值平方的最小值: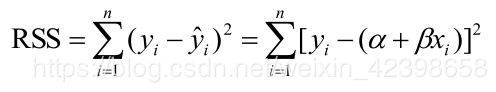
从上式可以看出我们主要是使Rss值最小,然后求出公式里的α与β的值嘛,公式求一下偏导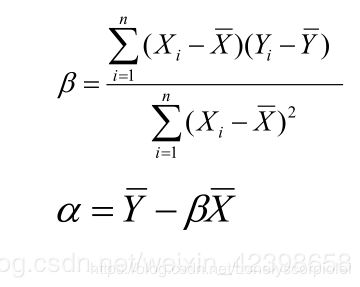
把数据带进去就可以确定系数了,最简单的一元线性回归就求出来了
我们分别利用Python代码与R语言实现一下吧
from __future__ import print_function, division
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#原始数据
x_data=np.array([20,22,19,25,18,27,30,15,33,38,22,40])
y_data=np.array([659,867,630,940,600,1000,1170,590,1280,1390,1080,1500])
# 学习率
learning_rate = 0.5
# 迭代次数
training_epochs = 1000
# 定义运算时的占位符
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# 定义模型参数
W = tf.Variable(np.random.randn(), name="weight", dtype=tf.float32)
b = tf.Variable(np.random.randn(), name="bias", dtype=tf.float32)
# 定义模型
pred = tf.add(tf.multiply(W, X), b)
# 定义损失函数
cost = tf.reduce_min(tf.pow(pred-Y, 2)/(2*100))
# 使用Adam算法
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
# 初始化所有变量
init = tf.global_variables_initializer()
# 训练开始
with tf.Session() as sess:
sess.run(init)
for epoch in range(training_epochs):
for (x, y) in zip(x_data, y_data):
sess.run(optimizer, feed_dict={X: x, Y: y})
if (epoch + 1) % 50 == 0:#每50步输出一次结果
c = sess.run(cost, feed_dict={X: x_data, Y: y_data})
print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.3f}".format(c), "W=", sess.run(W), "b=", sess.run(b))
print("Optimization Finished!")
training_cost = sess.run(cost, feed_dict={X: x_data, Y: y_data})
print("Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b), '\n')
# 使用matplot绘图
plt.plot(x_data, y_data, 'ro', label="Original data")
plt.plot(x_data, sess.run(W) * x_data + sess.run(b), label="Fitted line")
plt.legend()
plt.show()
R语言命令:创建数据:
h=c(184,172,158,165,168)
w=c(57,65,72,65,58)
#plot看看咋样
plot(w~h+1)
lines(h,a+b*h)
z=lm(w~h+1)
a
#线性模型的汇总数据,
summary(z)
# 方差分析函数anova()
anova(z)
多元线性回归
多元回归我们会使用矩阵来表示: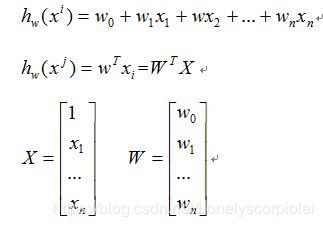
假设训练数据为: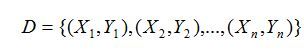
求和可以写成矩阵的形式: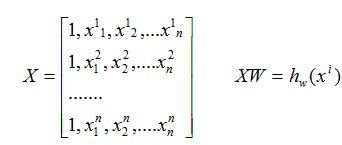
多元和一元差不多,不同的是一元回归是线,而多元回归就是超平面了,例如二元回归就是平面,表达式就是形如:![]()
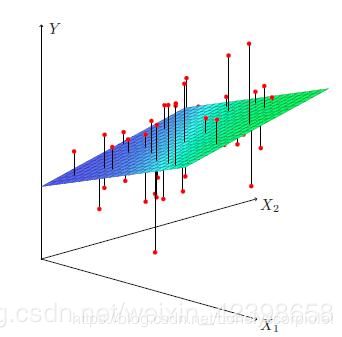
如果是三元以上的回归就是超平面了。
他的误差损失函数和一元的定义很类似: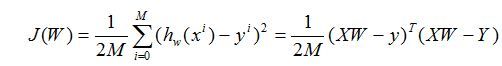
公式的推导这里就不详细介绍了,可以参考:https://blog.csdn.net/weixin_42398658/article/details/83501330这个大佬讲的特别细腻
#导入模块函数将数据集转化格式
from numpy import genfromtxt
import numpy as np #导入模块numpy,中间需要用到矩阵的运算
from sklearn import datasets,linear_model #导入数据集,并且导入线性回归模型函数
dataPath = r"E:\demo_py\python\machine_learning\MLR_1.csv" #初始化数据集的文件路径
delivaryData = np.genfromtxt(dataPath,delimiter=',') #将数据集文件中的数据转换为矩阵形式
print("data")
print(delivaryData)
X = delivaryData[:,:-1] #提取数据集中所有行,并且除了倒数第一列以外的数据项
Y = delivaryData[:,-1] #提取数据集中所有行,并且只有倒数第一列的数据项
print("特征矩阵")
print(X)
print("标记矩阵")
print(Y)
regr = linear_model.LinearRegression() #创建线性回归模型对象
regr.fit(X,Y) #将特征矩阵和标记矩阵传入模型器中训练模型
print("x的系数:",regr.coef_) #输出模型的有关x的参数,b1,b2...
print("截距:",regr.intercept_) #输出线性模型中的截距,b0
predict_x = [[102,6],] #给出测试矩阵
predict_y = regr.predict(predict_x) #预测
print("预测结果:",predict_y)
广义线性回归
所谓广义线性回归,我所理解的是Logistic回归,在前面的线性回归中,我们主要解决的是一个直线的拟,或者是一个平面、超平面的拟合,但是我们怎么解决这个曲面的拟合问题呢?对于曲面,我们既想使用线性函数进行拟合,又希望拟合过程尽可能好,那么,我们可以对上式进行变形:![]()
直观一点的意思就是:
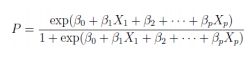
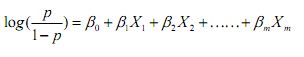
其中p表示Y=1的概率,以上内容参考了薛毅那本书来的,其实个人理解是这样的:
对于任意的x值,对应的y值都在区间(0,1)内:![]()
这个函数的曲线如下所示:
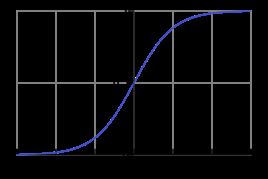
看个Python代码吧,这样好理解一点
from sklearn.linear_model import LogisticRegression
XTrain = [[0,0],[1,1]]
YTrain = [0,1]
reg = LogisticRegression()
reg.fit(XTrain, YTrain)
print(reg.score(XTrain,YTrain)
关于R语言这里就不实现了,大家可以参考薛毅的那本书来,说实话,我在这一章节中并不是很理解薛毅的思路,这一章节建议大家参考吴恩达老师的书,本来还想把非线性也总结一下的,以及所有的R语言实现,还有C++,java实现一遍的,但是时间问题,下次再分享吧!理解不是很深刻,希望大家多多指点,十分感谢!