立体相机开发|几何感知的实例分割
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达


论文下载:
http://www-scf.usc.edu/~choyingw/works/GAIS-Net/WSAD/CVPRW_CameraReady.pdf
代码下载:
https://drive.google.com/file/d/1ClWVotE94DfrjedJhZfDVHvp6WQ4aeMD/view?usp=drive_open
简介:
实例分割是计算机视觉的一项基本任务,它将感兴趣的每个对象分割出来。这对于自动驾驶至关重要,因为知道道路上每个对象实例的位置是至关重要的。在图像的实例分割上下文中,以前的方法只对RGB图像操作,如Mask-RCNN。
本文探索一个新方向——利用传感器融来合开发立体像机。具有差异性的地理信息有助于分离相同或不同类的重叠对象。此外,地理信息惩罚不太可能的三维形状区域建议,从而抑制假阳性检测。利用伪激光雷达和基于图像的表征,掩模回归基于2D、2.5D和3D ROI。这些掩模的预测被一个掩模评分过程融合。然而,公共数据集仅采用较短基线和焦距的立体摄像机,这限制了立体摄像机的测量范围。本文收集和利用高质量立体图片(HQDS)数据集,使用更长的基线和更高分辨率的焦距。
GAIS-Net 在HQDS 数据集上的结果:

本文主要贡献如下:
本文提出了一种结合视差图的地理信息和图像域语义信息的几何感知实例定位网络(GAIS-Net)。我们的贡献总结如下:
1)通过融合图像和视差信息来回归对象掩模对图像进行实例分割。
2)收集HQDS数据集,共8.8K立体对,f×b比当前最佳数据集Cityscapes大4倍。
3)提出了基于图像、基于图像和基于点云网络的实例分割的集合表示设计GAIS-Net。用不同的损失训练GAIS-Net,并使用掩模评分融合这些预测。GAIS-Net达到了最先进的状态。
方法:
目标是构建一个端到端可训练的网络来执行自动驾驶的实例分割。系统对每个实例进行分段,并为每个实例输出边界框和掩模的置信值。为了利用几何信息,采用了最先进的立体匹配网络PSMNet,并在ROI头部引入视差信息。整个网络设计如下图所示。建立了一个两级检测器的骨干网络,如ResNet50-FPN,和一个区域建议网络(RPN)的非最大抑制。通过将立体图像输入主干网和RPN来收集目标。与mask-rcnn相同,进行边界盒回归、建议的类预测、基于图像域特征的mask预测。对应的损失用Lbox、Lcls、L2Dmask表示。
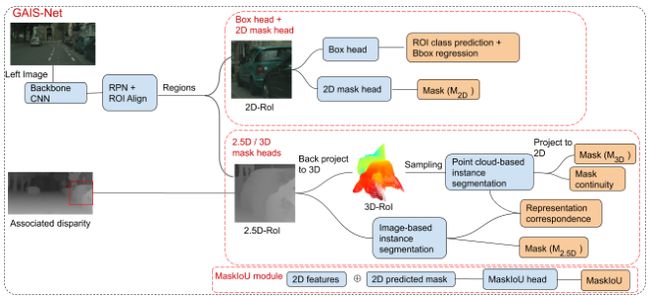
2.5D ROI和3D ROI:
使用PSMNet和立体视觉对来预测密集的视差图,投射到左侧立体视觉帧上,RPN输出区域建议,并从视差图中裁剪出这些区域,然后把这些裁剪出来的视差区域称为2.5D ROI。利用back-projecting 2d网格结构化数据到三维点云处理点云网络,back-project差异映射到R3空间,第一和第二组件描述其2d网格坐标,第三个组件存储其差异值,将这种表现称为3D ROI。
实例分割网络
每个3D ROI包含不同数量的点。为了便于训练,将三维感兴趣区域统一采样到1024个点,并将所有的三维感兴趣区域收集为张量。开发一个点网结构的实例分割网络来提取点特征并进行匹配掩码概率预测。将3D特征重新投影到2D网格中,以计算预测及其损失。由于在基于点云的实例分割中没有打破点的顺序,因此该投影是有效的。L 3Dmask与L 2Dmask相同,是预测概率mask与匹配ground truth之间的交叉熵损失。
掩模连续性:
对1024个点进行三维ROI均匀采样。然而,预测的掩模为M3D,其轮廓是敏感的伪激光雷达采样策略。下图说明了一个不理想的采样。为了补偿不理想的效果,引入了掩模连续性损失。

不理想的抽样例子。蓝色区域代表前景。假设均匀采样左图中的每个网格中心点,结果在右图的占用网格中显示点云。红色的叉是不需要的采样点,它们仅仅在前景对象的外面,使得采样后的形状与原来的形状不同。
表示一致性:
利用基于点云的网络和基于图像的网络进行特征提取和三维回归。这两个掩模应该是相似的,因为它们来自相同的视差图。为了评估相似度,计算了M3d和M2.5 d之间的交叉熵,并作为自监督对应损失相关性。通过最小化损失,不同表达语句的网络之间可以相互监督,从而提取更多的描述性特征用于掩模回归,从而在M 2.5D和M 3D之间形成相似的概率分布。在掩模头部使用和Mask-RCNN在ROI池后使用同样的一个14×14特征网格对mask进行回归这个尺寸。
掩模评分和掩模融合:
采用掩模评分法,进一步利用MaskIoU评分法来融合不同表达的掩模预测。掩模融合过程如下图所示。在推理过程中,将不同代表的特征和预测掩模分别连接起来,作为MaskIoU头的输入,输出的分数为S,使用相应的掩模分数来融合掩模预测。首先将(M2.5D, S2.5D)和(M 3D, S3D)线性合并,得到视差值(M D, SD)。公式如下:

掩模的评分过程不应该因不同的表现而不同。只使用二维图像特征和M2D来训练单个MakIoU,而不是针对每个表示构造3个MakIoU。这样,MaskIoU模块不会增加更多的内存使用,训练也是有效的。
推断时间从不同的表示掩模融合的预测:

实验结果:
在HQDS测试集上的表现:
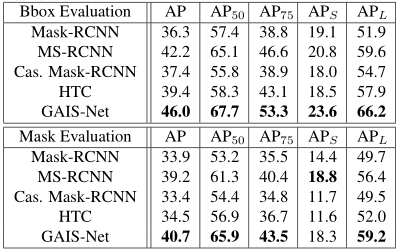
在Cityscapes数据集上的表现:

本文仅做学术分享,如有侵权,请联系删文。
推荐阅读:
专辑|相机标定
专辑|3D点云
专辑|SLAM
专辑|深度学习与自动驾驶
专辑|结构光
专辑|事件相机
专辑|OpenCV学习
专辑|学习资源汇总
专辑|招聘与项目对接
专辑|读书笔记
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近1000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题