强大的NVAE:以后再也不能说VAE生成的图像模糊了

©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
前几天笔者在日常刷 arixv 的时候,然后被一篇新出来的论文震惊了!论文名字叫做 NVAE: A Deep Hierarchical Variational Autoencoder,顾名思义是做 VAE 的改进工作的,提出了一个叫 NVAE 的新模型。
说实话,笔者点进去的时候是不抱什么希望的,因为笔者也算是对 VAE 有一定的了解,觉得 VAE 在生成模型方面的能力终究是有限的。结果,论文打开了,呈现出来的画风是这样的:
 ▲ NVAE的人脸生成效果
▲ NVAE的人脸生成效果
然后笔者的第一感觉是这样的:W!T!F! 这真的是 VAE 生成的效果?这还是我认识的 VAE 么?看来我对 VAE 的认识还是太肤浅了啊,以后再也不能说 VAE 生成的图像模糊了...
不过再看了看作者机构,原来是 NVIDIA,这也大概能接受了。最近几年可能大家都留意到 NVIDIA 通常都在年底发布个生成模型的突破,2017 年底是 PGGAN [1] ,2018 年底是 StyleGAN [2] ,2019 年底是 StyleGAN2 [3] 。
今年貌似早了些,而且动作也多了些,因为上个月才发了个叫 ADA 的方法,将 Cifar-10 的生成效果提到了一个新高度,现在又来了个 NVAE。

论文标题:NVAE: A Deep Hierarchical Variational Autoencoder
论文链接:https://arxiv.org/abs/2007.03898
那这个 NVAE 究竟有什么特别的地方,可以实现 VAE 生成效果的突飞猛进呢?

VAE回顾
可能读者认真观察后会说:好像还是有点假呀,那脸部也太光滑了,好像磨过皮一样,还比不上 StyleGAN 呀~
是的,这样评价并没有错,生成痕迹还是挺明显的。但如果你没感觉到震惊,那估计是因为你没看过之前的 VAE 生成效果,一般的 VAE 生成画风是这样的:

▲ 一般的VAE的随机生成效果
所以,你还觉得这不是一个突破吗?
那么,是什么限制了(以前的)VAE 的表达能力呢?这一次的突破又是因为改进了哪里呢?让我们继续看下去。
1.1 基本介绍
VAE,即变分自编码器(Variational Auto-Encoder),本人已经有不少文章介绍过了,在公众号后台搜索“变分自编码器”就能搜到很多相关文章。这里做个简单的回顾和分析。
在笔者对 VAE 的推导里边,我们是先有一批样本,这批样本代表着一个真实的(但不知道形式的)分布 ,然后我们构建一个带参数的后验分布 ,两者就组成一个联合分布 。
接着,我们再定义一个先验分布 q(z),已经定义一个生成分布 ,这样构成另一个联合分布 。最后,我们的目的就是让 相互接近起来,所以我们去优化两者之间的 KL 散度:
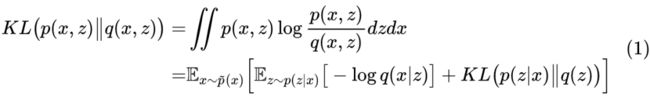
这就是 VAE 的优化目标。
1.2 困难分析
对 的要求是:1. 能写出解析表达式;2. 方便采样。
然而连续型分布的世界里这样的分布并不多,最常用的也就是高斯分布了,而这其中又以“各分量独立的高斯分布”最为简单,所以在一般的 VAE 里边, 都被设为各分量独立的高斯分布:

以及

问题是,“各分量独立的高斯分布”不能拟合任意复杂的分布,当我们选定 的形式后,有可能不管我们怎么调它的参数, 和 都不能成为高斯分布,这就意味着 从理论上来说就不可能为 0,所以让 相互逼近的话,只能得到一个大致、平均的结果,这也就是常规 VAE 生成的图像偏模糊的原因。
1.3 相关改进
改进 VAE 的一个经典方向是将 VAE 与 GAN 结合起来,比如 CVAE-GAN [4] 、AGE [5] 等,目前这个方向最先进结果大概是 IntroVAE [6] 。从理论上来讲,这类工作相当于隐式地放弃了 q(x|z) 是高斯分布的假设,换成了更一般的分布,所以能提升生成效果。
不过笔者觉得,将 GAN 引入到VAE中有点像“与虎谋皮”,借助 GAN 提升了性能,但也引入了 GAN 的缺点(训练不稳定等),而且提升了性能的 VAE 生成效果依然不如纯 GAN 的。另外一个方向是将 VAE 跟 flow 模型结合起来,比如 IAF-VAE [7] 以及笔者之前做的 f-VAE,这类工作则是通过 flow 模型来增强 或 的表达能力。
还有一个方向是引入离散的隐变量,典型代表就是 VQ-VAE,其介绍可以看笔者的《VQ-VAE 的简明介绍:量子化自编码器》[8] 。VQ-VAE 通过特定的编码技巧将图片编码为一个离散型序列,然后 PixelCNN 来建模对应的先验分布 q(z)。
前面说到,当 z 为连续变量时,可选的 p(z|x),q(z) 都不多,从而逼近精度有限;但如果z是离散序列的话,p(z|x),q(z) 对应离散型分布,而利用自回归模型(NLP 中称为语言模型,CV 中称为 PixelRNN/PixelCNN 等)我们可以逼近任意的离散型分布,因此整体可以逼近得更精确,从而改善生成效果。
其后的升级版 VQ-VAE-2 [9] 进一步肯定了这条路的有效性,但整体而言,VQ-VAE 的流程已经与常规 VAE 有很大出入了,有时候不大好将它视为 VAE 的变体。

NVAE梳理
铺垫了这么久,总算能谈到 NVAE 了。NVAE 全称是 Nouveau VAE(难道不是 Nvidia VAE?),它包含了很多当前 CV 领域的新成果,其中包括多尺度架构、可分离卷积、swish 激活函数、flow 模型等,可谓融百家之所长,遂成当前最强 VAE~
提醒,本文的记号与原论文、常见的 VAE 介绍均有所不同,但与本人其他相关文章是一致的,望读者不要死记符号,而是根据符号的实际含义来理解文章。

自回归分布
前面我们已经分析了,VAE 的困难源于 不够强,所以改进的思路都是要增强它们。首先,NVAE 不改变 ,这主要是为了保持生成的并行性,然后是通过自回归模型增强了先验分布 和后验分布 。
具体来说,它将隐变量分组为 ,其中各个 还是一个向量(而非一个数),然后让:

而各个组的 依旧建立为高斯分布,所以总的来说 就被建立为自回归高斯模型。这时候的后验分布的 KL 散度项变为:
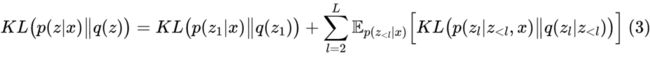
当然,这个做法只是很朴素的推广,并非 NVAE 的首创,它可以追溯到 2015 年的 DRAW [10] 、HVM [11] 等模型。NVAE 的贡献是给式 (2) 提出了一种“相对式”的设计:

也就是说,没有直接去后验分布 的均值方差,而是去建模的是它与先验分布的均值方差的相对值,这时候我们有(简单起见省去了自变量记号,但不难对应理解)。

原论文指出这样做能使得训练更加稳定。
3.1 多尺度设计
现在隐变量分成了 L 组 ,那么问题就来了:1. 编码器如何一一生成 ?2. 解码器如何一一利用 ?也就是说,编码器和解码器如何设计?
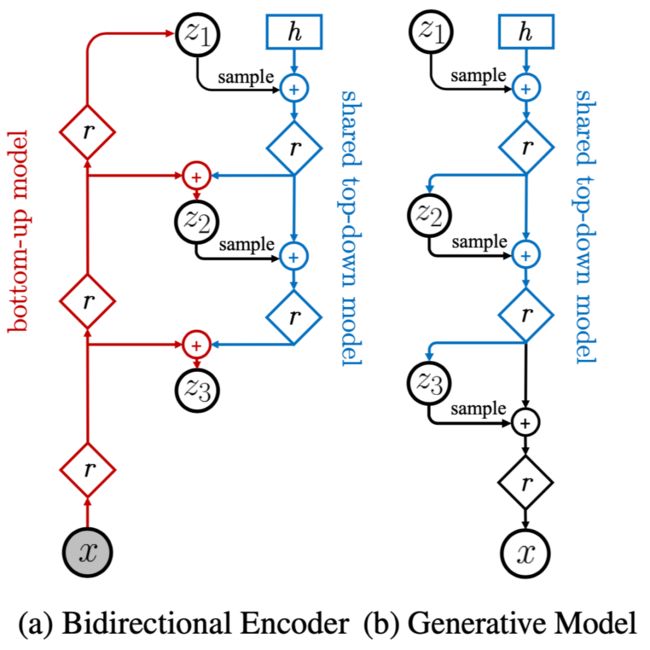
NVAE 巧妙地设计了多尺度的编码器和解码器,如上图所示。首先,编码器经过层层编码,得到最顶层的编码向量 ,然后再慢慢地从顶层往下走,逐步得到底层的特征 。
至于解码器,自然也是一个自上往下地利用 的过程,而这部分刚好也是与编码器生成 的过程有共同之处,所有 NVAE 直接让对应的部分参数共享,这样既省了参数量,也能通过两者间的相互约束提高泛化性能。
这种多尺度设计在当前最先进的生成模型都有体现,比如 StyleGAN [2] 、BigGAN、VQ-VAE-2 [9] 等,这说明多尺度设计的有效性已经得到比较充分的验证。此外,为了保证性能,NVAE 还对残差模块的设计做了仔细的筛选,最后才确定了如下的残差模块,这炼丹不可谓不充分极致了:
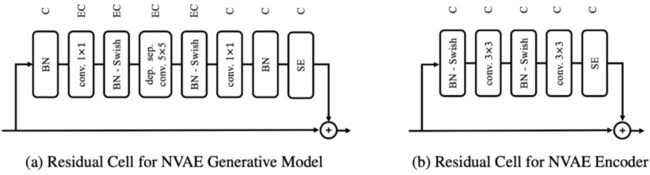
▲ NVAE中的残差模块
3.2 其他提升技巧
除了以上两点比较明显的特征外,其实 NVAE 还包含了很多对性能有一定提升的技巧,这里简单列举一些。
BN 层的改进。当前很多生成模型已经弃用 BN(Batch Normalization)了,多数会改用 IN(Instance Normalization)或 WN(Weight Normalization),因为发现用 BN 会损失性能。
NVAE 通过实验发现,其实 BN 对训练还是有帮助的,但对预测有害,原因是预测阶段所使用的滑动平均得来的均值方差不够好,所以 NVAE 在模型训练完后,通过多次采样同样 batch_size 的样本来重新估算均值方差,从而保证了 BN 的预测性能。此外,为了保证训练的稳定性,NVAE 还给 BN 的 \gamma 的模长加了个正则项。
谱正则化的应用。我们知道,任意两个分布的 KL 散度是无上界的,所以 VAE 里边的 KL 散度项也是无上界的,而优化这种无上界的目标是很“危险”的,说不准啥时候就发散了。
所以同样是为了稳定训练,NVAE 给每一个卷积层都加了谱正则化,其概念可以参考笔者之前的深度学习中的 Lipschitz 约束:泛化与生成模型。加谱归一化可以使得模型的 Lipschitz 常数变小,从而使得整个模型的 Landscape 更为光滑,更利于模型稳定训练。
flow 模型增强分布。通过自回归模型,NVAE 增强了模型对分布的拟合能力。不过这个自回归只是对组间进行的,对于组内的单个分布 和 ,依然假设为各分量独立的高斯分布,这说明拟合能力依然有提升空间。
更彻底的方案是,对于组内的每个分量也假设为自回归分布,但是这样一来在采样的时候就巨慢无比了(所有的分量串联递归采样)。
NVAE 提供了一个备选的方案,通过将组内分布建立为 flow模型来增强模型的表达能力,同时保持组内采样的并行性。实验结果显示这是有提升的,但笔者认为引入 flow 模型会大大增加模型的复杂度,而且提升也不是特别明显,感觉能不用就不用为好。
节省显存的技巧。尽管 NVIDIA 应该不缺显卡,但 NVAE 在实现上还是为省显存下了点功夫。一方面,它采用了混合精度训练,还顺带在论文推了一波自家的 APEX 库 [12] 。
另一方面,它在 BN 那里启用了 gradient check-point [13](也就是重计算)技术,据说能在几乎不影响速度的情况下节省 18% 的显存。总之,比你多卡的团队也比你更会省显存~
3.3 更多效果图
到这里,NVAE 的技术要点基本上已经介绍完毕了。如果大家还觉得意犹未尽的话,那就多放几张效果图吧,让大家更深刻地体会 NVAE 的惊艳之处。

▲ NVAE 在 CelebA HQ 和 FFHQ 上的生成效果。值得注意的是,NVAE 是第一个 FFHQ 数据集上做实验的 VAE 类模型,而且第一次就如此惊艳了
▲ CelebA HQ的更多生成效果

个人收获
从下述训练表格来看,我们可以看到训练成本还是蛮大的,比同样分辨率的 StyleGAN 都要大,并且纵观整篇论文,可以发现有很多大大小小的训练 trick(估计还有不少是没写在论文里边的,当然,其实在 StyleGAN 和 BigGAN 里边也包含了很多类似的 trick,所以这不算是NVAE的缺点)。
因此对于个人来说,估计是不容易复现 NVAE 的。那么,对于仅仅是有点爱好生成模型的平民百姓(比如笔者)来说,从 NVAE 中可以收获到什么呢?
 ▲NVAE的训练参数与成本
▲NVAE的训练参数与成本
对于笔者来说,NVAE 带来的思想冲击主要有两个。
第一,就是自回归的高斯模型可以很有力地拟合复杂的连续型分布。以前笔者以为只有离散分布才能用自回归模型来拟合,所以笔者觉得在编码时,也需要保持编码空间的离散型,也就是 VQ-VAE 那一条路。
而 NVAE 证明了,哪怕隐变量是连续型的,自回归高斯分布也能很好地拟合,所以不一定要走 VQ-VAE 的离散化道路了,毕竟连续的隐变量比离散的隐变量更容易训练。
第二,VAE 的隐变量可以不止一个,可以有多个的、分层次的。我们再次留意上表,比如 FFHQ 那一列,关于隐变量 z 的几个数据,他一共有 4+4+4+8+16=36 组,每组隐变量大小还不一样,分别是 ,如此算来,要生成一个 的 FFHQ 图像,需要一个总大小有:
![]()
维的随机向量,也就是说,采样一个 600 万维的向量,生成一个 (不到 20 万)维的向量。这跟传统的 VAE 很不一样,传统的 VAE 一般只是将图片编码为单个(几百维)的向量,而这里的编码向量则多得多,有点全卷积自编码器的味道了,所以清晰度提升也是情理之中。

Nouveau是啥?
最后,笔者饶有性质地搜索了一下 Nouveau 的含义,以下是来自维基百科的解释 [14] :
nouveau (/nuːˈvoʊ/) 是一个自由及开放源代码显卡驱动程序,是为 Nvidia 的显卡所编写,也可用于属于系统芯片的 NVIDIA Tegra 系列,此驱动程序是由一群独立的软件工程师所编写,Nvidia 的员工也提供了少许帮助。该项目的目标为利用逆向工程 Nvidia 的专有 Linux 驱动程序来创造一个开放源代码的驱动程序。
由让 freedesktop.org 托管的 X.Org 基金会所管理,并以 Mesa 3D 的一部分进行散布,该项目最初是基于只有 2D 绘图能力的 “nv” 自由与开放源代码驱动程序所开发的,但红帽公司的开发者 Matthew Garrett 及其他人表示原先的代码被混淆处理过了。
nouveau 以 MIT 许可证许可。项目的名称是从法文的 “nouveau” 而来,意思是“新的”。这个名字是由原作者的的 IRC 客户端的自动取代功能所建议的,当他键入 “nv” 时就被建议改为 “nouveau”。
这是不是说,其实 Nouveau VAE 跟 Nvidia VAE 算是同义词了呢?原来咱们开始的理解也并没有错。

文章小结
本文介绍了 NVIDIA 新发表的一个称之为 NVAE 的升级版 VAE,它将 VAE 的生成效果推向了一个新的高度。从文章可以看出,NVAE 通过自回归形式的隐变量分布提升了理论上限,设计了巧妙的编码-解码结构,并且几乎融合了当前所有生成模型的最先进技术,打造成了当前最强的 VAE。
参考文献
[1] https://arxiv.org/abs/1710.10196
[2] https://arxiv.org/abs/1812.04948
[3] https://arxiv.org/abs/1912.04958
[4] https://arxiv.org/abs/1703.10155
[5] https://arxiv.org/abs/1704.02304
[6] https://arxiv.org/abs/1807.06358
[7] https://arxiv.org/abs/1606.04934
[8] https://kexue.fm/archives/6760
[9] https://arxiv.org/abs/1906.00446
[10] https://arxiv.org/abs/1502.04623
[11] https://arxiv.org/abs/1511.02386
[12] https://github.com/NVIDIA/apex
[13] https://arxiv.org/abs/1604.06174
[14] https://zh.wikipedia.org/wiki/Nouveau
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
