基于监督学习+自监督学习的智能抠图,精确到发丝 | CVPR 2020


来源 | AI算法与图像处理(ID:AI_study)
华盛顿大学的研究者最近发表的论文在CVPR 2020提供了一个新的和简单的智能抠图方法。你可以在家里做这些日常设置,使用固定或手持相机。我们的方法也是最先进的,给出的输出可比专业的结果。在本文中,我们将介绍该方法的动机、技术细节和使用技巧。

论文:https://arxiv.org/pdf/2004.00626.pdf
项目:https://github.com/senguptaumd/Background-Matting

Matting是什么?
Matting是将图像分离为前景和背景的过程,这样你就可以将前景合成到新的背景上。这是绿屏效应背后的关键技术,广泛应用于视频制作、图形和消费应用。为了建模这个问题,我们将捕获的图像中的每个像素表示为前景和背景的组合:

我们的问题是解决给定的图像(C)每个像素的前景(F),背景(B)和透明度(alpha).显然这是高度不确定的,因为图像有RGB通道,这需要从3个观察值解决7个未知。

分割的问题
一种可能的方法是使用分割分离前景进行合成。尽管分割在近年来取得了巨大的进步,但它并不能解决所有的问题。分割给每个像素分配一个二进制(0,1)标签来代表前景和背景,而不是解决一个连续的alpha值。这种简化的效果如下例所示:

边缘的区域,特别是头发,有一个真正的alpha值在0到1之间。因此,分割的二进位性质创造了一个苛刻的边界周围的前景,留下可见的人工的痕迹。解决了部分透明度和前景颜色允许更好的合成在第二帧。

使用随意捕捉背景
由于matting是一个比segmentation更难的问题,额外的信息经常被用来解决这个无约束的问题,即使是在使用深度学习的时候。
许多现有的方法使用一个 trimap,或已知前景、背景和未知区域的手工标注的映射。虽然这对于一幅图像是可行的,但是标注视频是非常耗时的,并不是这个问题的一个可行的研究方向。
我们选择使用捕获的背景作为真实背景的估计。这使得前景和alpha值更容易解决。我们称之为“随意捕捉”的背景,因为它可以包含轻微的运动,颜色差异,轻微的阴影,或与前景相似的颜色。

上图显示了我们可以轻易地对真实背景作出粗略估计。当人离开场景时,我们捕捉他们身后的背景。下图显示了它的样子:

注意这张图片是如何具有挑战性的,因为它有一个非常相似的背景和前景颜色(特别是周围的头发)。它也是用手持电话录制的,包含了轻微的背景运动。
“我们称之为随意捕捉的背景,因为它可以包含轻微的运动,颜色差异,轻微的阴影,或与前景相似的颜色。”
Tips for Capturing
虽然我们的方法适用于一些背景扰动,但当背景是恒定的,在室内环境中效果最好。例如,它在被摄主体投射的高度明显的阴影、移动的背景(例如水、汽车、树木)或大曝光变化的情况下不起作用。

我们还建议在视频结束时让人离开场景,然后从连续的视频中拉出画面来捕捉背景。当你从视频模式切换到照片模式时,许多手机都有不同的变焦和曝光设置。当你用手机拍摄时,你也应该启用自动曝光锁定。

捕捉技巧的总结:
选择你能找到的最恒定的背景。
不要站得离背景太近,这样你就不会投下阴影。
启用手机的自动曝光和自动对焦锁定功能。
这种方法和背景减法一样吗?
另一个自然的问题是这是否像背景减法。首先,如果在合成中使用任何背景都很容易,那么电影行业就不会花费数千美元在绿色屏幕上。

此外,背景减法不能解决部分alpha值,给予相同的硬边缘分割。当有相似的前景和背景色或背景中的任何运动时,它也不能很好地工作。
 网络细节
网络细节
该网络由一个监督的步骤和一个非监督的细化组成。我们将在这里简要地总结它们,但要了解详细信息,请参阅论文。
监督式学习
为了首先训练网络,我们使用Adobe composiated -1k数据集,其中包含450个仔细标注的ground truth alpha mattes。我们以一种完全监督的方式训练网络,每个像素的损失输出。
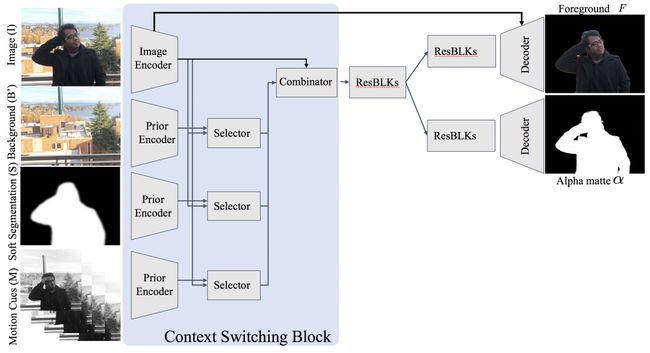
请注意,我们有几个输入,包括图像、背景、软分割和时间运动信息。我们的新上下文切换块( Context Switching Block )也确保了对不良输入的鲁棒性。
Unsupervised Refinement with GANs
监督学习的问题是adobe数据集只包含450个ground truth输出,这远远不足以训练一个好的网络。获得更多的数据是极其困难的,因为它涉及到手工注释图像的alpha哑光。
为了解决这个问题,我们使用GAN细化步骤。我们从被监督的网络中获取输出的alpha哑光,并将其合成到一个新的背景中。然后鉴别器试着辨别这是真实的还是虚假的图像。作为回应,生成器学会更新alpha哑光,从而得到尽可能真实的合成,以欺骗鉴别器。
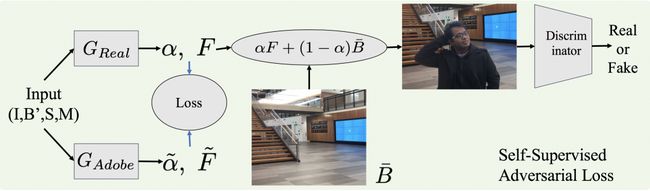
这里重要的部分是,我们不需要任何带标记的训练数据。该鉴别器是用成千上万的真实图像进行训练的,这些图像很容易获得。
在数据上使用GAN训练
GAN的另一个有用之处是,您可以在自己的映像上对生成器进行训练,从而在测试时改进结果。假设您运行网络,但输出不是很好。为了更好地欺骗判别器,你可以更新精确数据上生成器的权重。这将与您的数据过度匹配,但将改善您提供的图像的结果。

未来的工作
虽然我们看到的结果是相当好的,我们将继续使这种方法更准确和容易使用。
特别地,我们想让这个方法对背景运动,摄像机运动,阴影等情况更加健壮。我们也在寻找方法,使这种方法在实时工作和较少的计算资源能力。这可以在视频流或移动应用等领域实现各种各样的用例。
参考
[1] S. Sengupta, V. Jayaram, B. Curless, S. Seitz, and I. Kemelmacher-Shlizerman, Background Matting: The World is Your Green Screen (2020), CVPR 2020
[2] L.C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (2018), ECCV 2018
[3] Y.Y. Chuang, B. Curless, D. H. Salesin, and R. Szeliski, A Bayesian Approach to Digital Matting (2001), CVPR 2001
[4] Q. Hou and F. Liu. Context-Aware Image Matting for Simultaneous Foreground and Alpha Estimation (2019), ICCV 2019
[5] H. Lu, Y. Dai, C. Shen, and S. Xu, Indices Matter: Learning to Index for Deep Image Matting (2019), ICCV 2019


推荐阅读
空间-角度信息交互用于光场图像超分辨重构,性能达到最新SOTA | ECCV 2020
阿里巴巴副总裁司罗:达摩院如何搭建NLP技术体系?
Python 爬取 13966 条运维招聘信息,这些岗位最吃香
Python 编程语言的核心是什么?
Python轻松搞定Excel中的20个常用操作
2020 活久见:欧美主流 app「熔断」了
赠书 | DeFi沉思录:历史、中国与未来
你点的每个“在看”,我都认真当成了AI