【汇总】最新的目标检测方法发展到哪了
选自arXiv | 机器之心编辑
从经典的 R-CNN 到今年非常受关注的 CenterNet,目标检测近几年到底有哪些发展?现在都到 2019 年了,基于关键点检测这一新范式效果到底怎么样?对于目标检测,这篇 40 页的综述论文有你想要的所有答案。
目标检测是计算机视觉领域中的一个基础视觉识别问题,在近几十年得到了广泛研究。视觉目标检测即在给定图像中找出属于特定目标类别的对象及其准确位置,并为每个对象实例分配对应的类别标签。
近日,来自新加坡管理大学和 Salesforce 亚洲研究院的研究人员撰写了一篇论文,对基于深度学习的视觉目标检测的近期发展进行了全面综述,系统性地分析了现有的目标检测框架。
论文链接:https://arxiv.org/abs/1908.03673v1
该综述文章包括三个主要部分:1)检测组件;2)学习策略;3)应用与基准,并详细介绍了影响目标检测性能的多种因素,如检测器架构、特征学习、候选框生成、采样策略等。
下图 2 展示了,2012 年以来基于深度学习的目标检测技术的主要发展和里程碑。这篇论文介绍了这些关键技术的基本思想,并进行了系统性分析。
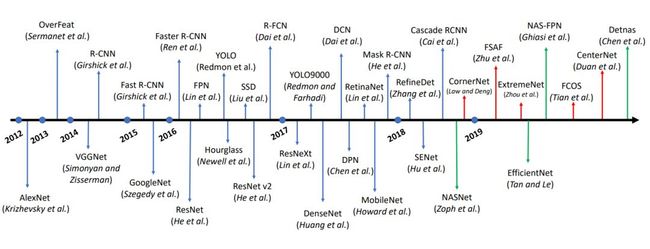
图 2:2012 年以来,基于深度卷积神经网络的目标检测技术的主要里程碑。过去一年的技术发展趋势是基于 anchor-free 的目标检测器(红色线)和 AutoML 技术(绿色线),这两项技术可能成为未来重要的研究方向。
因为该综述论文花了近 40 页篇幅综述各种解决方案与组成结构,内容覆盖了这些年主要的研究进展与突破,所以机器之心只介绍部分内容,更详细的介绍请查阅原论文。
当然,以前机器之心也曾介绍过很多目标检测方面的研究或综述文章,因此本文会侧重介绍 18 年到 19 年非常流行的基于关键点的目标检测。这一种单步检测范式不仅拥有极高的准确率,同时速度还非常快,也许目标检测未来的发展主流会聚集在这一范式下。
从经典走向前沿的目标检测
在深度学习时代之前,早期的目标检测流程分为三步:候选框生成、特征向量提取和区域分类。
候选框生成阶段的目标是搜索图像中可能包含对象的位置,这些位置又叫「感兴趣区域」(ROI)。直观的思路是用滑动窗口扫描整幅图像。为了捕捉不同尺寸和不同宽高比对象的信息,输入图像被重新分割为不同的尺寸,然后用不同尺寸的窗口滑动经过输入图像。
第二阶段,在图像的每一个位置上,利用滑动窗口获取固定长度的特征向量,从而捕捉该区域的判别语义信息。该特征向量通常由低级视觉描述子编码而成,这些描述子包括 SIFT (Scale Invariant Feature Transform) 、Haar 、HOG(Histogram of Gradients) 、SURF(Speeded Up Robust Features) 等,它们对缩放、光线变化和旋转具备一定的鲁棒性。
第三阶段,学习区域分类器,为特定区域分配类别标签。
通常,这里会使用支持向量机(SVM),因为它在小规模训练数据上性能优异。此外,Bagging、级联学习(cascade learning)和 Adaboost 等分类技术也会用在区域分类阶段,帮助提高目标检测的准确率。
DL 时代的目标检测
在将深度卷积神经网络成功应用于图像分类后,基于深度学习技术的目标检测也取得了巨大进步。基于深度学习的新算法显著优于传统的目标检测算法。
目前,基于深度学习的目标检测框架可以分为两大类:1)二阶检测器(Two-stage),如基于区域的 CNN (R-CNN) 及其变体;2)一阶检测器(One-stage),如 YOLO 及其变体。
二阶检测器首先使用候选框生成器生成稀疏的候选框集,并从每个候选框中提取特征;然后使用区域分类器预测候选框区域的类别。一阶检测器直接对特征图上每个位置的对象进行类别预测,不经过二阶中的区域分类步骤。
通常而言,二阶检测器通常检测性能更优,在公开基准上取得了当前最优结果,而一阶检测器更省时,在实时目标检测方面具备更强的适用性。
DL 目标检测器该怎样系统学习
本文目标是全面理解基于深度学习的目标检测算法。下图 3 展示了本文涵盖主要方法的分类:根据深度学习目标检测算法的不同贡献将其分为三类:检测组件、学习策略,以及应用与基准。
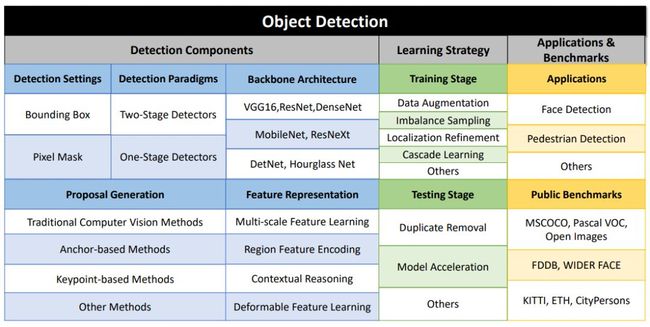
图 3:本文涵盖主要方法的分类。
对于检测组件,这篇论文首先介绍了两种检测设置:边界框级(bbox-level)定位和像素掩码级(mask-level)定位。bbox-level 算法需要按照矩形边界框进行目标定位,而 mask-level 算法则按照更准确的像素级掩码进行目标分割。
接下来,论文总结了二阶检测和一阶检测的代表性框架。然后对每个检测组件进行了详细论述,包括主干架构、候选框生成和特征学习。
对于学习策略,论文首先强调了学习策略的重要性(因为训练检测器是很艰难的过程),然后详细介绍了训练和测试阶段中的优化技术。最后,论文概览了一些基于目标检测的现实应用,并展示了近年来通用目标检测技术在公开基准上的当前最优结果。
这些虽然是这篇综述论文的写作思路,但是对于希望系统了解该领域的读者而言,也是非常好的学习路径:先了解整体类别与研究现状,再了解具体的组件与策略。
检测范式
当前最优的深度学习目标检测器可以分为两大类:二阶检测器和一阶检测器。二阶检测器首先生成稀疏的候选框集合,然后使用深度卷积神经网络编码生成候选框的特征向量,并执行类别预测。一阶检测器没有候选框生成这一单独步骤,它们通常将图像的所有位置都看作潜在对象,然后尝试将每个感兴趣区域分类为背景或目标对象。
二阶检测器
二阶检测器将检测任务分成两个阶段:候选框生成和对候选框执行预测。在第一阶段,检测器尝试识别图像中可能存在对象的区域。其基本思想是以高召回率提出候选区域,使得图像中的所有对象属于至少一个候选区域。第二阶段中,使用基于深度学习的模型为这些候选区域分配正确的类别标签。每个区域可能是背景,也可能是属于某个预定义类别标签的对象。

图 4:不同二阶目标检测框架概览。红色虚线矩形表示输出(该输出定义损失函数)。
一阶检测器
与把检测流程分成两部分的二阶检测器不同,一阶检测器没有单独的候选框生成步骤。它们通常将图像上的所有位置都看作潜在对象,然后再把每个感兴趣区域分类为背景或目标对象。
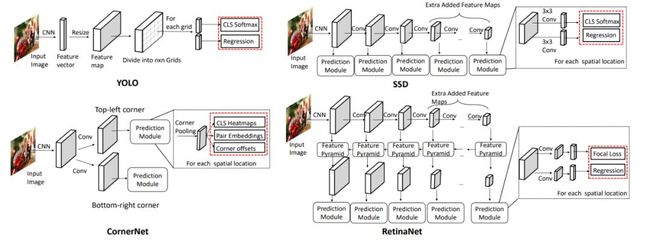
图 5:不同一阶目标检测框架概览。红色虚线矩形表示输出(输出定义目标函数)。
Redmon 等人提出了一种叫做 YOLO(You Only Look Once)的实时检测器。YOLO 将目标检测看作回归问题,将整个图像分割为固定数量的网格单元(如使用 7 × 7 网格)。每个单元被看作一个候选框,然后网络检测候选框中是否存在一或多个对象。
基于精细设计的轻量级架构,YOLO 可以 45 FPS 的速度执行预测,使用更简化的骨干网络后速度可达 155 FPS。但是,YOLO 面临以下挑战:
对于给定位置,它至多只能检测出两个对象,这使得它很难检测出较小的对象和拥挤的对象。
只有最后一个特征图可用于预测,这不适合预测多种尺寸和宽高比的对象。
2016 年,Liu 等人提出另一个一阶检测器 Single-Shot Mulibox Detector (SSD),解决了 YOLO 的缺陷。SSD 也将图像分割为网格单元,但是在每一个网格单元中,可以生成一组不同尺寸和宽高比的锚点框,从而离散化边界框的输出空间。
SSD 在多个特征图上预测对象,且每一个特征图基于其感受野来检测特定尺寸的对象。整个网络通过端到端训练机制,使用位置损失和分类损失的加权和作为损失函数进行优化。最后网络合并来自不同特征图的全部检测结果,得到最终的预测。
没有候选框生成步骤来帮助筛选容易正确分类的负样本,导致前景背景类别不均衡成为一阶检测器中的严重问题。Lin 等人提出一阶检测器 RetinaNet,用更灵活的方式解决了类别不均衡的问题。
RetinaNet 使用 focal loss 抑制易分负样本的梯度,而不是简单地摒弃它们。然后使用特征金字塔网络,在不同级别的特征图上检测多尺寸对象。
Redmon 等人提出 YOLO 改进版本——YOLOv2,它显著提升了检测性能,且仍然维持实时推断速度。YOLOv2 通过对训练数据执行 k 折聚类(而不是手动设置)来定义更好的锚点先验,这有助于降低定位中的优化难度。
以前的方法在训练检测器时需要手动设计锚点框,后来一批 anchor-free 目标检测器出现,其目标是预测边界框的关键点,而不是将对象与锚点框做匹配。
其中比较受关注的是基于关键点的检测架构,它会预测左上角和右下角的热图,并用特征嵌入将其合在一起,CornerNet 就是基于关键点检测中非常经典的架构。当然还有后续结合中心点和角点的 CenterNet,它具有更好的性能。
候选框生成
候选框生成在目标检测框架中起着非常重要的作用。候选框生成器生成一组矩形边界框,它们有可能包含对象。然后使用这些候选框进行分类和定位精炼(localization refinement)。
基于锚点的方法
监督式候选框生成器的一个大类是基于锚点的方法。它们基于预定义锚点生成候选框。Ren 等人提出区域候选网络 (Region Proposal Network,RPN),基于深度卷积特征图以监督方式生成候选框。
该网络使用 3 × 3 卷积核在整个特征图上滑动。对于每个位置,网络都考虑 k 个 不同大小和宽高比的锚点(或边界框的初始估计)。这些不同的尺寸和宽高比允许网络匹配图像中不同尺寸的对象。
基于真值边界框,将对象的位置与最合适的锚点进行匹配,从而为锚点估计获得监督信号。
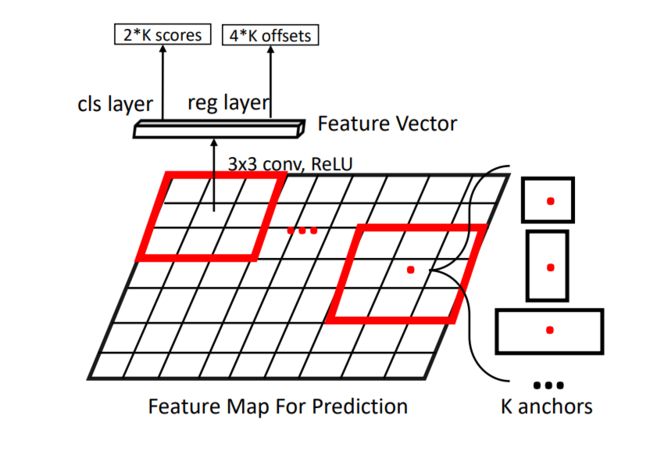
图 6:RPN 图示。
基于关键点的方法
另一种候选框生成方法基于关键点检测,它分为两类:基于角点(corner)的方法和基于中心(center)的方法。
基于角点的方法通过合并从特征图中学得的角点对,来预测边界框。这种算法无需设计锚点,从而成为生成高质量候选框的更高效方法。
Law 和 Deng 提出 CornerNet,直接基于角点建模类别信息。CornerNet 使用新型特征嵌入方法和角点池化层(corner pooling layer)建模左上角点和右下角点的信息,从而准确匹配属于同一对象的关键点。该方法在公开基准上获得了当前最优结果。
基于中心的方法在特征图的每个位置上预测它成为对象中心的概率,且在没有锚点先验的情况下直接恢复宽度和高度。
Duan 等人 提出了 CenterNet,它结合了基于中心的方法和基于角点的方法。CenterNet 首先通过角点对预测边界框,然后预测初始预测的中心概率,来筛除易分负样本。相比基线,CenterNet 的性能获得了显著提升。
anchor-free 方法是未来很有前途的研究方向。
目标检测公开基准
当然除了整体范式与候选框的生成,目标检测还有更多的组件与细节,例如主体架构怎么选、数据增强/采样怎么做、模型压缩/加速怎么处理等等,本文就不一一介绍了。最后,让我们看看当前目标检测公开基准上的模型效果都怎么样。
目标检测的基准其实有挺多的,它们主要可以分为通用型、人脸检测型、公共区域型,它们加起来差不多有 16 个基准。

几个通用型目标检测基准,及其数据集的样本。
在下面表 2 和表 3 中,论文展示了近几年各种目标检测方法在 VOC2007、VOC2012 和 MSCOCO 基准上的效果。
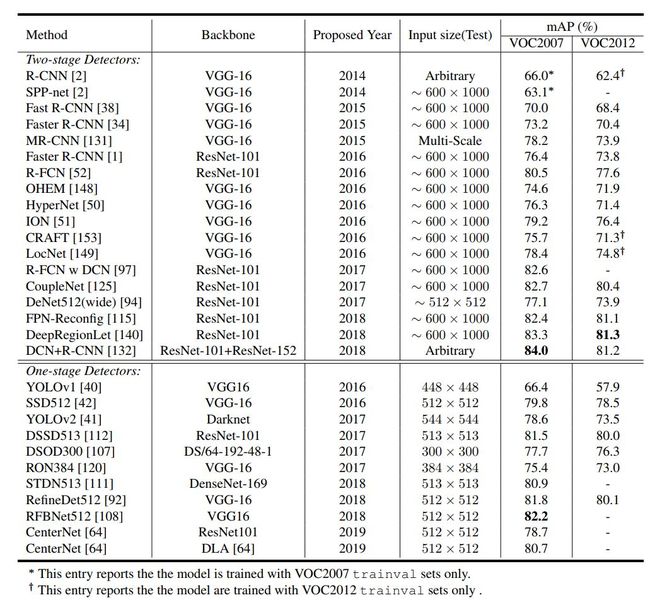
表 2:各种方法在 PASCAL VOC 数据集上的检测效果。
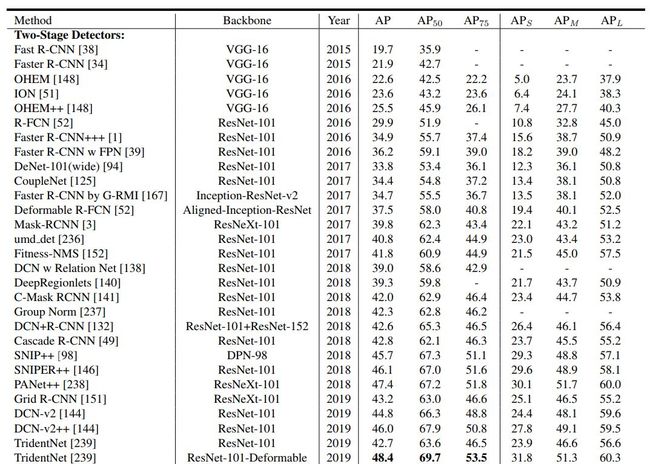
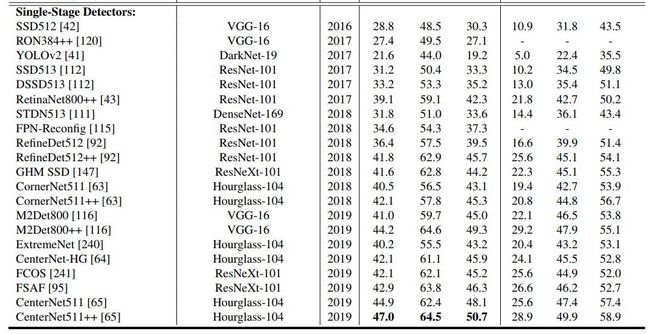
表 3: MS COCO 数据集上的检测效果。
推荐阅读
11个Python Pandas小技巧让你的工作更高效
清华姚班90后学霸、MIT博士吴佳俊即将加入斯坦福任助理教授
Python计算机二级模拟题,现在开始!
从小白到大师,这里有一份Pandas入门指南

喜欢就点击“在看”吧!