pandas,seaborn与matplotlib学习
文章目录
- 一、pandas
- pandas数据结构
- 二、seaborn
- 箱型图boxplot
- 计数图 countplot
- 直方图distplot
- catplot
- 代码实现
- 三、matplotlib
在机器学习中,一般使用pandas进行数据的处理,使用matplotlib或者seaborn
进行数据可视化,两者结合起来处理和分析数据,能让之后的步骤事半功倍。
一、pandas
代码保存在ipynb文件,点击查看
pandas数据结构
- Series
一种类似于一维数组的对象,由**一组数据(各种numpy数据类型)以及一组与之相关的数据标签(即索引)**组成。在创建时可以显式说明各个数据点的索引,如果没有说明,则默认自动创建0到N-1(N为数据的长度)的整数型索引,并且可以通过索引的方式选取Series中的单个或一组值。也可以通过字典赋值创建。Series在算术运算中会自动对齐不同索引的数据
创建方式
(1)Series:通过一维数组创建
(2)Series:通过字典的方式创建
Series类型包括index和values两部分,相当于DataFrame的任意一列加索引构成,下面是一些基本操作
import pandas as pd
from pandas import Series,DataFrame
data1=Series(['A','B','C','D'])
print (data1)
print (data1.index)#获得索引
print (data1.values)#获得值
print(data1[1])#查找某一个索引值
# print(data1[A])#查找某一个索引值
print (data1[:3]) #自动切片
- DataFrame
可以从任何数据格式创建dataframe,这是一个表格型的数据结构。构建DataFrame最常用的一种是直接传入一个由等长列表或numpy数组组成的字典。可通过columns指定列顺序,如果指定的列名称不存在,则默认为NaN值。
pandas.DataFrame( data, index, columns, dtype, copy)
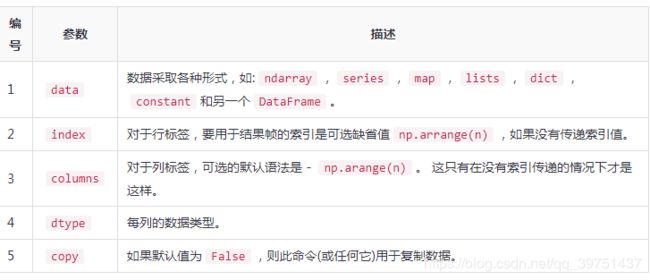
总结主要用法
# -*- coding: utf-8 -*-
"""pandas.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1L7F8tse-VTKAbP8eY4Ui9rR0U_myV53y
"""
import urllib.request
import urllib
url = "https://raw.githubusercontent.com/GokuMohandas/practicalAI/master/data/titanic.csv"
response = urllib.request.urlopen(url)
html = response.read()
with open('titanic.csv', 'wb') as f:
f.write(html)
import pandas as pd
df=pd.read_csv('C:\\Users\\Administrator\\Desktop\\titanic.csv')
print (df.head(5)#前五项
,df.describe()
,df.info()
,df['age'].hist()#直方图
,df['sibsp'].hist()
,df['parch'].hist()
,df['embarked'].unique()#统计特征不同取值
,df['sex'].unique()
# 根据特征选择数据
,df["name"].head()
,len(df[df['sex']=='female']['survived'])#按固定特征取值筛选数据
,df[df['sex']=='female'].head(5)#按固定特征取值筛选数据
,len(df[df['sex']=='male']['survived'])
# 排序
,df.sort_values("age", ascending=False).head(5))
# Grouping(数据聚合与分组运算)
sex_group = df.groupby("survived")
print (sex_group.mean()
,df.groupby("survived")
# iloc根据位置的索引来访问
# iloc在索引中的特定位置获取行(或列)(因此它只需要整数)
,df.iloc[[1,3,5,877], :]
,df.iloc[0:3, :]#前闭后开区间0-2,[行,列]
,df.iloc[:,4]#第四列
,df.iloc[0, 1]#取特定位置元素
# loc根据标签的索引来访问
# loc从索引中获取具有特定标签的行(或列)
,df.loc[1]
# 删除具有Nan值的行
,df.dropna())
# 删除多列
df = df.drop(["parch"], axis=1)
print (df.columns)
#创建新的特征
df["famliy_size"]=df["pclass"]+df["sibsp"]
print (df["famliy_size"])
#保存数据csv文件
df.to_csv("C:\\Users\\Administrator\\Desktop\\processed_titanic.csv", index=False)
二、seaborn
点击进入seaborn官网教程
seaborn还可以自己导入数据集
import seaborn as sns
iris = sns.load_dataset("iris")
下面重点介绍三种图
- 计数图 countplot
- 箱型图boxplot(hue: 指定要区分的类别)
- 直方图distplot
箱型图boxplot
seaborn.boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, notch=False, ax=None, **kwargs)
ax = sns.boxplot(x=“day”, y=“total_bill”, hue=“smoker”, data=tips, palette=“Set3”)
要点:
hue指定要区分的类别
palette调色板
ax:matplotlib轴
data:数据
计数图 countplot
属性和boxplot类似
seaborn.countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, dodge=True, ax=None, **kwargs)
#代码
import seaborn as sns
sns.set(style="darkgrid")
titanic = sns.load_dataset("titanic")
ax = sns.countplot(x="class", data=titanic,hue="Survived")
直方图distplot
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None, color=None, vertical=False, norm_hist=False, axlabel=None, label=None, ax=None)
catplot
通过kind生成不同类别的图, kind的取值有: strip, swarm, box,
violin,boxen,point, bar, count. strip为默认值.
seaborn.catplot(x=None, y=None, hue=None, data=None, row=None, col=None, col_wrap=None, estimator=, ci=95, n_boot=1000, units=None, order=None, hue_order=None, row_order=None, col_order=None, kind='strip', height=5, aspect=1, orient=None, color=None, palette=None, legend=True, legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, **kwargs)、
代码实现
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn import datasets
iris=datasets.load_iris()
data=pd.DataFrame(iris.data,columns=['Sepal.Length','Sepal.Width','Petal.Length','Petal.Width'])
a=pd.Series(iris.target)
data['type']=a
sns.lmplot(x='Sepal.Length',y='type',data=data,fit_reg=False)#fit_reg=False移去回归线
sns.countplot('Sepal.Length',hue='type',data=data)
train = pd.read_csv('D:\\Sublime Text 3\\python\\Titanic Machine Learning from Disaster\\train.csv')
f,ax = plt.subplots(3,4,figsize=(20,16))
##计数图 countplot
##箱型图boxplot,hue: 指定要区分的类别
##直方图distplot
sns.countplot('Pclass',data=train,ax=ax[0,0])
sns.countplot('Sex',data=train,ax=ax[0,1])
sns.boxplot(x='Pclass',y='Age',data=train,ax=ax[0,2])
sns.countplot('SibSp',hue='Survived',data=train,ax=ax[0,3],palette='husl')
sns.set_style('whitegrid')
sns.countplot('Pclass',hue='Survived',data=train,ax=ax[1,0],palette='husl')
sns.countplot('Sex',hue='Survived',data=train,ax=ax[1,1],palette='husl')
sns.distplot(train['Age'].dropna(),ax=ax[1,2],kde=False,color='r')
# sns.distplot(train[train['Survived']==0]['Age'].dropna(),ax=ax[1,2],kde=False,color='r',bins=5)
# sns.distplot(train[train['Survived']==1]['Age'].dropna(),ax=ax[1,2],kde=False,color='g',bins=5)
sns.countplot('Parch',hue='Survived',data=train,ax=ax[1,3],palette='husl')
sns.distplot(train['Fare'].dropna(),ax=ax[2,0],kde=False,color='b')##dropna()过滤缺失值
sns.swarmplot(x='Pclass',y='Fare',hue='Survived',data=train,ax=ax[2,1],palette='husl')
sns.countplot('Embarked',data=train,ax=ax[2,2])
sns.countplot('Embarked',hue='Survived',data=train,ax=ax[2,3],palette='husl')
##ax[0,0]表示第一行,第一列
ax[0,0].set_title('Total Passengers by Class')
ax[0,1].set_title('Total Passengers by Sex')
ax[0,2].set_title('Age boxplot by Class')
ax[0,3].set_title('Survival Rate by SibSp')
ax[1,0].set_title('Survival Rate by Pclass')
ax[1,1].set_title('Survival Rate by gender')
ax[1,2].set_title('Survival Rate by Age')
ax[1,3].set_title('Survival Rate by Parch')
ax[2,0].set_title('Fare Distribution')
ax[2,1].set_title('Survival Rate by Fare and Pclass')
ax[2,2].set_title('Total Passengers by Embarked')
ax[2,3].set_title('Survival Rate by Embarked')
# Import necessarily libraries
import matplotlib.pyplot as plt
import seaborn as sns
# Load data
titanic = sns.load_dataset("titanic")
# Set up a factorplot
# sns.factorplot("class", "survived", data=titanic, kind="bar",palette="muted", legend=True)
# Show plot
import seaborn as sns
sns.set(style="darkgrid")
titanic = sns.load_dataset("titanic")
sns.countplot(x="class", hue="survived",data=titanic)
sns.catplot(x="class", col="survived",data=titanic, kind="count",height=4, aspect=.7)#col按类别画图
#kind=count的时候,和countplot画出来一样
#kind=box的时候,和boxplot画出来一样
plt.show()
三、matplotlib
简要步骤
1.调用figure创建一个绘图对象,并且使它成为当前的绘图对象。
2.通过调用plot函数在当前的绘图对象中进行绘图。
3.设置绘图对象的各个属性
4.最后调用plt.show()显示出我们创建的所有绘图对象。
import numpy as np
import matplotlib.pyplot as plt
plt.figure # 创建画布1
x = np.linspace(0, 3, 100)
plt.figure() #选择图表1
plt.subplot(121)
plt.plot(x, np.exp(x*x/3))
plt.subplot(122)
plt.plot(x, np.exp(x*x/2))
plt.xlabel('aaa')
plt.ylabel('bbb')
plt.title('xxx')
plt.show()
# xlim:限制x轴的取值范围
# ylim:限制y轴的取值范围
# xlabel:设置x轴的标签
# ylabel:设置y轴的标签
# title:设置标题