Ceph的FileStore代码阅读问题整理
1.bufferlist中的_memcopy_count作用是什么?
bufferlist提供了一个rebuild函数,用来将整个buffterptr链表的所有bufferraw都copy到一个新建的bufferptr中,然后清空链表并将新建的这个bufferptr插入到链表中。_memcopy_count成员记录了在进行拷贝过程中每个bufferraw的长度之和。这个值用来在进行内存对齐时需要重新计算,然后比较两者的值,如果不相同就判断内存对齐成功,否则失败。
2.bufferlist是不是类似io buffer?
bufferlist是ceph中进行所有内存操作的管理类:
- bufferraw(buffer::raw):对应一段真实内存,派生了十多种不同分配内存的子类,如raw_malloc,raw_static,raw_mmap_pages,raw_posix_aligned,raw_char,raw_pipe等
- bufferptr(buffer::ptr):对应ceph实际使用的一段内存,可能多个bufferptr对应于同一个底层bufferraw,其成员off和len标识具体使用的一段内存
- bufferlist(buffer::list):多个正在使用的bufferptr构成的一个链表,对应成员std::list
_buffers,其成员off表示整个链表构成的内存相对于起始位置的偏移,p_off表示当前使用的bufferptr的偏移
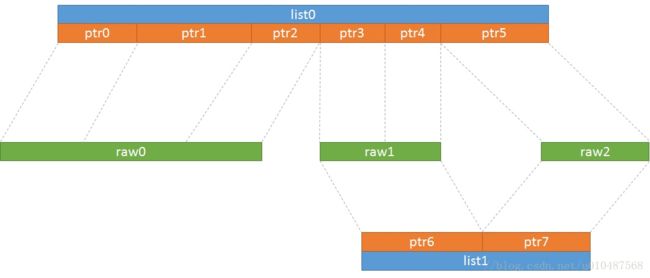
对于bufferlist来说,通过内部实现的bufferlist::iterator来访问多个bufferptr,能够逐个字节的访问整个内存的内容,不需要关心到底有多少个bufferptr存在,也不用关心bufferptr和底层bufferraw到底是怎么关联的,这种设计就是为了上层使用上的方便,与io buffer的缓存作用并没有太大关系。
上层用户可以直接使用write_file,write_fd等方法,将bufferlist的内容写入文件,可以完全忽略内存的来源、释放等问题,这些问题统一由bufferraw的派生子类和引用计数进行解决。ceph中有两个使用bufferlist最广泛的场景:
- 快速encode/decode:messege层收到osd传递的消息(为一个bufferlist),需要加上消息头和消息尾等操作,这些消息头和尾本身都encode为bufferlist,就很容易与消息本身合并(prepend和append操作),而且这些encode、preprend、append操作都是指针操作,不涉及内存拷贝,提示效率。
- 减少内存分配次数和碎片:利用bufferptr这个中间层进行内存的多次使用,多个bufferptr可以引用同一段bufferraw的不同区域,这个bufferraw可以预先一次性申请较大一段连续内存,从而避免了多次申请内存以及内存碎片的产生。
3.io 优先级?best effort和 real time区别?
I/O优先级是linux系统为read和同步write操作提供的一种系统调用,对于异步write不支持,同时glibc没有提供封装,需要使用头文件,使用ioprio_set函数进行设置。共有三个参数
- which:表明第二个参数的解释方式,IOPRIO_WHO_PROCESS代表who参数为一个进行或线程ID;IOPRIO_WHO_PGRP表明who为同一进程组的所有进程;IOPRIO_WHO_USER为同一用户的所有进程
- who:优先级的指定方式,分为IOPRIO_PRIO_VALUE/CLASS/DATA三种方式指定优先级
- ioprio:为优先级的掩码值,用来生成最终的优先级,优先级数值越低优先级越高
I/O优先级是通过I/O调度器实现,对于每个设备有一个特殊文件可以查看:
/sys/block//queue/scheduler
目前绝大部分实现都是CFQ I/O调度器(Completely Fair Queuing I/O Scheduler),支持三种类型的I/O调度类别:
- IOPRIO_CLASS_RT:real time,被CFQ给予最高优先级进行调度,每次都会给予最优先的机会去放问磁盘,这种调度策略可能会将整个磁盘的IO打满,对应的优先级值可以从最高的0到最低的7进行设置
- IOPRIO_CLASS_BE:best effort,每个进程默认的优先级,优先级值从最高的0到最低的7进行设置
- IOPRIO_CLASS_IDLE:idle调度类别最低,只有没有其他进程使用磁盘时才会调度这类优先级类别的I/O操作
4.pre_pad作用是什么?
FileJournal的每一个entry没有offset字段,利用pre_pad找到data部分的起始位置,然后利用len确定数据部分的长度,接着的post_pad用来找到footer部分,具体结构如下图:
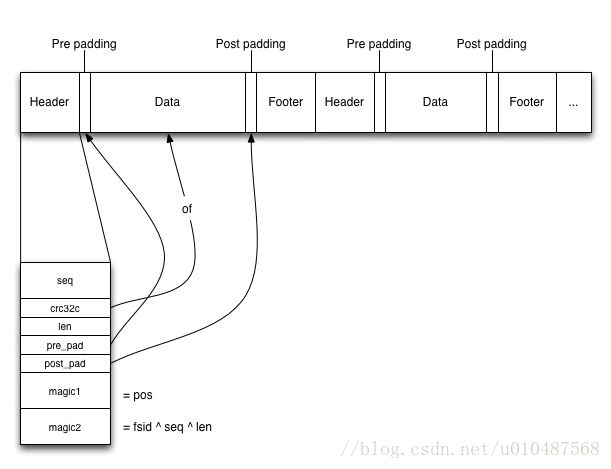
代码中的实现部分如下,可以看出footer和header部分都是写入了一个entry_header:
int
FileJournal
::
prepare_entry
(
vector
<
ObjectStore
::
Transaction
>&
tls
,
bufferlist
*
tbl
)
{
...
entry_header_t
h
;
unsigned
head_size
=
sizeof
(
entry_header_t
)
;
off64_t
base_size
=
2
*
head_size
+
bl
.
length
(
)
;
memset
(
&
h
,
0
,
sizeof
(
h
))
;
if
(
data_align
>=
0
)
h
.
pre_pad
=
((
unsigned
int
)
data_align
-
(
unsigned
int
)
head_size
)
&
~
CEPH_PAGE_MASK
;
off64_t
size
=
ROUND_UP_TO
(
base_size
+
h
.
pre_pad
,
header
.
alignment
)
;
unsigned
post_pad
=
size
-
base_size
-
h
.
pre_pad
;
h
.
len
=
bl
.
length
(
)
;
h
.
post_pad
=
post_pad
;
h
.
crc32c
=
bl
.
crc32c
(
0
)
;
...
bufferlist
ebl
;
// header
ebl
.
append
(
(
const
char
*
)
&
h
,
sizeof
(
h
))
;
if
(
h
.
pre_pad
)
{
ebl
.
push_back
(
buffer
::
create_static
(
h
.
pre_pad
,
zero_buf
))
;
}
// payload
ebl
.
claim_append
(
bl
,
buffer
::
list
::
CLAIM_ALLOW_NONSHAREABLE
)
;
// potential zero-copy
if
(
h
.
post_pad
)
{
ebl
.
push_back
(
buffer
::
create_static
(
h
.
post_pad
,
zero_buf
))
;
}
// footer
ebl
.
append
(
(
const
char
*
)
&
h
,
sizeof
(
h
))
;
...
}
5.magic number作用是什么?
从第4个问题的图示中可以看出magic number是进行数据校验的,magic1是记录的当前entry写入的相对于整个journal文件开头的绝对位置,也就是最终调用文件系统的lseek操作的位置;magic2就是fsid、seq、len三者的异或值,用于进一步校验。
6.aio是否落盘还是cache就返回?
FileJournal打开fd进行写入的时候设置的flag为O_RDWR,如果使用了directio(通过配置项设置journal dio = true),则会为flag增加O_DIRECT | O_DSYNC,因此配置dio为true时就会直接写入磁盘。
7.读数据多个线程?
读取数据的操作都会解析为lfn_open打开文件,调用safe_pread进行读取,最后lfn_close关闭文件,而safe_pread是封装了pread的一个公共函数:
ssize_t
safe_pread
(
int
fd
,
void
*
buf
,
size_t
count
,
off_t
offset
)
{
size_t
cnt
=
0
;
char
*
b
=
(
char
*
)
buf
;
while
(
cnt
<
count
)
{
ssize_t
r
=
pread
(
fd
,
b
+
cnt
,
count
-
cnt
,
offset
+
cnt
)
;
if
(
r
<=
0
)
{
if
(
r
==
0
)
{
// EOF
return
cnt
;
}
if
(
errno
==
EINTR
)
continue
;
return
-
errno
;
}
cnt
+=
r
;
}
return
cnt
;
}
因此使用方并发调用读取操作是支持的。
8.配journal限制的目的是什么?
Journal Throttle一方面为了控制写入速度过快导致所有journal可写空间都占满,造成大量修改操作并没有commit到底层存储中,另一方面是可以控制底层存储的队列中的长度,可以为实时性要求高的业务场景提供可配。
9.split和merge后怎么维持hash关系?
每个object都有一个对其hash值进行nibble reverse之后的字段:nibblewise_key_cache,每次进行split的时候会基于这个对象重新创建一个新的匹配的路径,见下面的get_path_component函数,这个函数最终会获取这个对象的nibblewise_key_cache字段的值,然后每次都会按照半字节翻转一次,得到的新路径会重新创建或者直接移动到相应目录(已存在的话),然后删除现有object,最终设置新目录的xattr,里面包含了这个目录下有多少个object和子目录等信息。当进行merge的时候与这个过程类似。
int
HashIndex
::
complete_split
(
const
vector
<
string
>
&
path
,
subdir_info_s
info
)
{
int
level
=
info
.
hash_level
;
map
<
string
,
ghobject_t
>
objects
;
vector
<
string
>
dst
=
path
;
int
r
;
dst
.
push_back
(
""
)
;
r
=
list_objects
(
path
,
0
,
0
,
&
objects
)
;
...
map
<
string
,
map
<
string
,
ghobject_t
>
>
mapped
;
...
for
(
map
<
string
,
ghobject_t
>
::
iterator
i
=
objects
.
begin
(
)
;
i
!=
objects
.
end
(
)
;
++
i
)
{
vector
<
string
>
new_path
;
get_path_components
(
i
->
second
,
&
new_path
)
;
mapped
[
new_path
[
level
]]
[
i
->
first
]
=
i
->
second
;
}
...
r
=
remove_objects
(
path
,
moved
,
&
objects
)
;
...
set_info
(
path
,
info
)
;
...
}
void
HashIndex
::
get_path_components
(
const
ghobject_t
&
oid
,
vector
<
string
>
*
path
)
{
char
buf
[
MAX_HASH_LEVEL
+
1
]
;
snprintf
(
buf
,
sizeof
(
buf
)
,
"%.*X"
,
MAX_HASH_LEVEL
,
(
uint32_t
)
oid
.
hobj
.
get_nibblewise_key
(
))
;
// Path components are the hex characters of oid.hobj.hash, least
// significant first
for
(
int
i
=
0
;
i
<
MAX_HASH_LEVEL
;
++
i
)
{
path
->
push_back
(
string
(
&
buf
[
i
]
,
1
))
;
}
}
10.多级目录的目的是什么?
多级目录是为了防止同一个目录下保存的文件数目过多导致查询时效率过低,通过多级目录的切分,能够增加读取目录项和文件的效率。