吴恩达《Machine Learning》-概念(一)
入坑吴恩达大佬的机器学习课程。纯英文教学和作业还有编程作业还是很挑战的,希望早日结课拿证。
机器学习定义

T是此次机器学习的任务
测试题:
“A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.”
Suppose your email program watches which emails you do or do not mark as spam, and based on that learns how to better filter spam. What is the task T in this setting?
A.Classify emails as spam or not spam.
B.Watching you label emails as spam or not spam.
C.The number (or fraction) of emails correctly classified as spam/not spam.
D.None of the above, this is not a machine learning algorithm.
问题:此次的任务是什么?
正确答案:
选择A,将邮件分为垃圾邮件与非垃圾邮件
为Task
B,看你把邮件贴上垃圾邮件或者不是垃圾邮件的标签
为Experience
C,正确分类为垃圾邮件/非垃圾邮件的电子邮件的数量
为Performance
详细定义
Two definitions of Machine Learning are offered. Arthur Samuel described it as: “the field of study that gives computers the ability to learn without being explicitly programmed.” This is an older, informal definition.
Tom Mitchell provides a more modern definition: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
Example: playing checkers.
**E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
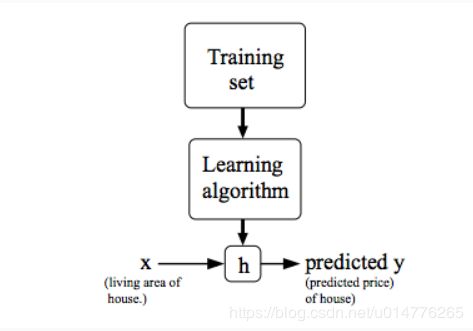
机器学习就是给定一些数据集,通过学习算法。根据输入的训练数据x与已经标定好的结果y,学习产生
机器学习问题分类
监督学习与无监督学习
In general, any machine learning problem can be assigned to one of two broad classifications:
Supervised learning and Unsupervised learning.**

监督学习给出已经存在的正确的数据集,通过算法预测出更多数据。
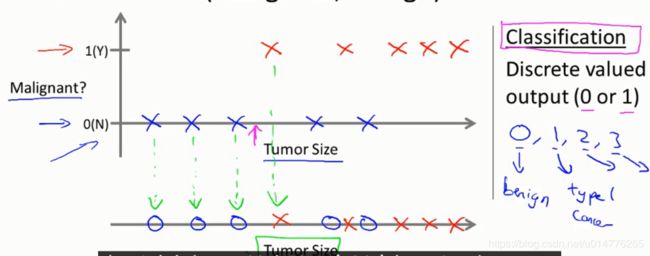
回归问题 连续值预测

分类问题 答案给出0,1,2,3等离散值

特征:
为将二(n)维的映射下来,并用不同符号代替。
测试题:
You’re running a company, and you want to develop learning algorithms to address each of two problems. Problem 1:You have a large inventory of identical items. You want to predict how many of these items will sell over the next 3 months.
Problem 2: You’d like software to examine individual customer accounts, and for each account decide if it has been hacked/compromised. Should you treat these as classification or as regression problems?
A.Treat both as classification problems.
B.Treat problem 1 as a classification problem, problem 2 as a regression problem.
C.Treat problem 1 as a regression problem, problem 2 as a classification problem.
D.Treat both as regression problems.
正确答案:
选择C。连续值为回归问题,离散值为分类问题
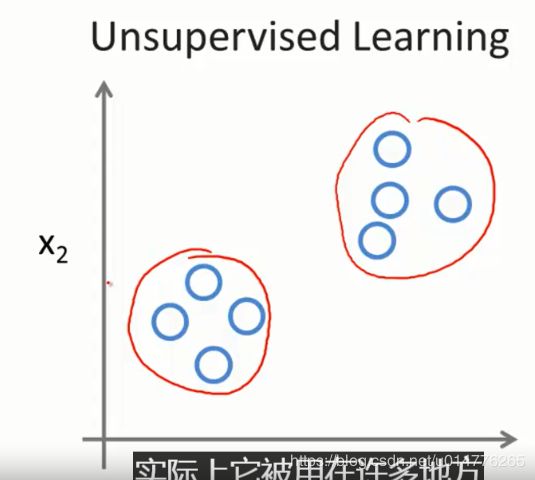
无监督学习,没有数据集的正负表名。相当于聚类。
聚类用处,将混有背景音乐的人声分离。分成背景音乐与人类。
octave解决分类问题。

测试题:
Of the following examples, which would you address using an unsupervised learning algorithm? (Check all that apply.)
A.Given email labeled as spam/not spam, learn a spam filter.
B.Given a set of news articles found on the web, group them into sets of articles about the same stories.
C.Given a database of customer data, automatically discover market segments and group customers into different market segments.
D.Given a dataset of patients diagnosed as either having diabetes or not, learn to classify new patients as having diabetes or not.
正确答案:
选B,D。
无监督学习,没有标定好的数据集,并且自动发现类别。
给定一个数据库的客户数据,自动发现和集团客户市场的段段到不同的市场。
测试题:
Suppose you are working on stock market prediction. You would like to predict whether or not a certain company will declare bankruptcy within the next 7 days (by training on data of similar companies that had previously been at risk of bankruptcy). Would you treat this as a classification or a regression problem? ( A ) \color{red}{(A)} (A)
A.Classification
B.Regression
Which of these is a reasonable definition of machine learning? ( B ) \color{red}{(B)} (B)
A.Machine learning learns from labeled data.
B.Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed.
C.Machine learning is the science of programming computers.
D.Machine learning is the field of allowing robots to act intelligently.