Jar运行问题
运行jar包报错
./bin/hadoop jar ./myapp/HDFSExample.jar
Exception in thread "main" java.lang.SecurityException: Invalid signature file digest for Manifest main attributes
at sun.security.util.SignatureFileVerifier.processImpl(SignatureFileVerifier.java:314)
at sun.security.util.SignatureFileVerifier.process(SignatureFileVerifier.java:268)
at java.util.jar.JarVerifier.processEntry(JarVerifier.java:316)
at java.util.jar.JarVerifier.update(JarVerifier.java:228)
at java.util.jar.JarFile.initializeVerifier(JarFile.java:383)
at java.util.jar.JarFile.getInputStream(JarFile.java:450)
at org.apache.hadoop.util.RunJar.unJar(RunJar.java:101)
at org.apache.hadoop.util.RunJar.unJar(RunJar.java:81)
at org.apache.hadoop.util.RunJar.run(RunJar.java:209)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)

解决方法:
zip -d newspark-1.0-SNAPSHOT.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF
运行jar包找不到主类
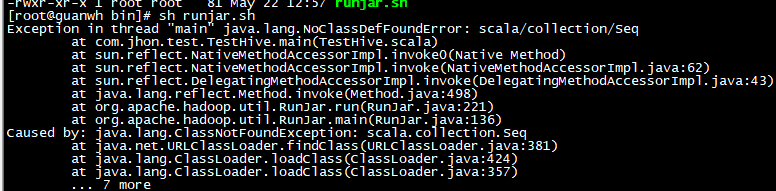
[root@guanwh bin]# hadoop jar newspark-1.0-SNAPSHOT.jar
Exception in thread "main" java.lang.ClassNotFoundException: com.jhon.test.TestHive
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.util.RunJar.run(RunJar.java:214)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
打包时候没有class文件
#运行时报错
Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/Seq
at com.jhon.test.TestHive.main(TestHive.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.ClassNotFoundException: scala.collection.Seq
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
解决办法:
HADOOP_CLASSPATH=/usr/scala/scala-2.11.8/lib/scala-library.jar hadoop jar original-newspark-1.0-SNAPSHOT.jar com.jhon.test.TestHive
无法加载lib
19/05/22 15:09:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hadoop jar 运行jar包
hadoop jar ***.jar -libjars /usr/lib **.MainClass
问题: java.lang.Exception: java.io.IOException: Unable to initialize any output collector
解决办法:
FileOutputFormat.setOutputPath(job, outPath)
[root@guanwh bin]# hadoop jar mytq.jar com.jhon.weather.MyWeather
19/05/28 12:40:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/05/28 12:40:26 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
19/05/28 12:40:26 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
19/05/28 12:40:26 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
19/05/28 12:40:26 INFO input.FileInputFormat: Total input paths to process : 1
19/05/28 12:40:27 INFO mapreduce.JobSubmitter: number of splits:1
19/05/28 12:40:27 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local822029151_0001
19/05/28 12:40:27 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
19/05/28 12:40:27 INFO mapreduce.Job: Running job: job_local822029151_0001
19/05/28 12:40:27 INFO mapred.LocalJobRunner: OutputCommitter set in config null
19/05/28 12:40:27 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
19/05/28 12:40:27 INFO mapred.LocalJobRunner: Waiting for map tasks
19/05/28 12:40:27 INFO mapred.LocalJobRunner: Starting task: attempt_local822029151_0001_m_000000_0
19/05/28 12:40:27 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/05/28 12:40:27 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/var/data/tq:0+273
19/05/28 12:40:27 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/05/28 12:40:27 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/05/28 12:40:27 INFO mapred.MapTask: soft limit at 83886080
19/05/28 12:40:27 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/05/28 12:40:27 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/05/28 12:40:27 WARN mapred.MapTask: Unable to initialize MapOutputCollector org.apache.hadoop.mapred.MapTask$MapOutputBuffer
java.lang.RuntimeException: java.lang.InstantiationException
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:131)
at org.apache.hadoop.mapred.JobConf.getOutputKeyComparator(JobConf.java:886)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1001)
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:401)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:695)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:767)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.InstantiationException
at sun.reflect.InstantiationExceptionConstructorAccessorImpl.newInstance(InstantiationExceptionConstructorAccessorImpl.java:48)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:129)
... 13 more
19/05/28 12:40:27 INFO mapred.LocalJobRunner: map task executor complete.
19/05/28 12:40:27 WARN mapred.LocalJobRunner: job_local822029151_0001
java.lang.Exception: java.io.IOException: Unable to initialize any output collector
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522)
Caused by: java.io.IOException: Unable to initialize any output collector
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:412)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:695)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:767)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
19/05/28 12:40:28 INFO mapreduce.Job: Job job_local822029151_0001 running in uber mode : false
19/05/28 12:40:28 INFO mapreduce.Job: map 0% reduce 0%
19/05/28 12:40:28 INFO mapreduce.Job: Job job_local822029151_0001 failed with state FAILED due to: NA
19/05/28 12:40:28 INFO mapreduce.Job: Counters: 0