AWS学习笔记——Chapter2 Storage
前注:
学习书籍
由于是全英文书籍,所以笔记记录大部分为英文。
Index
- Storage
- 1. Three major categories
- 2. Amazon S3 (Simple Storage Service)
- (1) Advantages
- (2) Usage of S3 in real life
- (3) Basic concepts
- (4) Data consistency model
- (5) Performance considerations
- (6) Encryption
- Encryption of data in transit
- Encryption of data at rest
- (7) Access Control
- Access Policies
- Bucket Policies
- ACL (Access Control List)
- (8) S3 Storage Class
- Amazon S3 Standard
- Amazon S3 Reduced Redundancy Storage (RRS)
- Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA)
- Amazon Glacier
- (9) Versioning of Objects in Amazon S3
- (10)Amazon S3 Lifecycle Management
- (11)Amazon S3 Cross-region Replication
- (12)Static Website Hosting in Amazon S3
- 3. Amazon Glacier
- (1) Common Use Cases
- (2) Key Terminology
- (3) Accessing Amazon Glacier
- (4) Uploading Files to Amazon Glacier
- (5) Retrieving Files from Amazon Glacier
- 4. Amazon EBS (Elastic Block Store)
- (1) Usage
- (2) Features
- (3) 3 Types of Block Storage Offerings
- Amazon EC2 instance store
- Amazon EBS SSD-backed volume
- Amazon EBS HDD-backed volume
- 5. Amazon EFS (Elastic File System)
- (1) Attributes
- (2) Using Amazon EFS
- (3) Performance Mode of EFS
- General-purpose Mode
- Max I/O Mode
- 6. On-premise Storage Integration with AWS
- (1) AWS Storage Gateway
- (2) AWS Snowball and AWS Snowball Edge
- (3) AWS Snowmobile
Storage
1. Three major categories
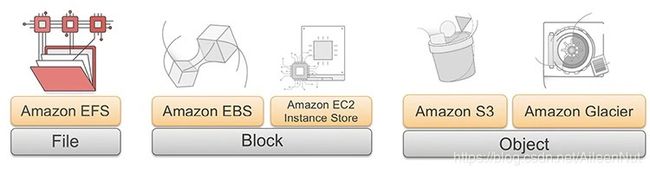
File: Amazon EFS
Block: Amazon EBS, Amazon EC2 Instance Store
Object: Amazon S3, Amazon Glacier
2. Amazon S3 (Simple Storage Service)
(1) Advantages
Simple, Scalable, Durable, Secured, High performance, Available, Low cost, Easy to manage, Easy integration
Notes:
· Easy integration with third parties, provides REST APIs and SDKs
· Scale up easily though PB data, unlimited data storage
· 99.999999999, data store across multiple data centers and in multiple devices in a redundant manner, sustain concurrent data loss in two facilities
· Data upload -> automatically encrypted; Data transfer -> support SSL;
· Integrate with Amazon CloudFront, delivery web service with low latency
(2) Usage of S3 in real life
Backup
popular for storing backup files among enterprises, data is distributed in three copies for each file between multiple AZs within an AWS region.
Tape replacement
Static web site hosting
Application hosting
can use it for hosting mobile and Internet-based apps.
Disaster recovery
Content distribution
distribute content over internet (directly from S3 or via CloudFront). The content can be anything, such as files, media (photos, videos, …). It can also be a software delivery platform where customers can download software.
Data lake
popular in the world of big data as a big data store to keep all kinds of data. S3 is often used with EMR, Redshift, Redshift Spectrum, Athena, Glue, and QuickSight for running big data analytics.
(A data lake is a central place for storing massive amounts of data that can be processed, analyzed, and consumed by different business units in an organization.)
Private repository
like Git, Yum, or Maven.
(3) Basic concepts
Bucket: a container for storing objects in Amazon S3
Notes: Name must be unique (even across multiple regions)
eg.
object name: ringtone.mp3,
bucket name: newringtones,
file accessible URL: http://newringtones.s3.amazonaws.com/ringtone.mp3
Object: anything store in an S3 bucket is called an object
Notes:
· An object is uniquely identified within a bucket by a name or key and by a version ID.
· Every object in a bucket has only one key.
Region: the object stored in the region never leaves the region unless you explicitly transfer it to a different region.
APIs: allow developers to write applications on top of S3.
Notes:
· REST HTTPS > REST HTTP > SOAP HTTPS
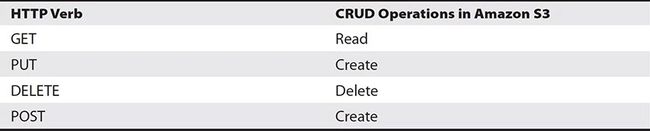
· HTTP verbs correspond to S3 CRUD Operations
GET -> Read, PUT -> Create, DELETE -> Delete, POST -> Create
SDKs: In addition to APIs, lots of SDKs are available in various platforms including in browsers, on mobile devices (Android and iOS), and in multiple programming languages (Java, .NET, Node.js, PHP, Python, Ruby, Go, C++).
Amazon CLI (command-line interface): unified tool to manage all your AWS services.
Notes:
· CLI is often used by Amazon S3 in conjunction with REST APIs and SDKs.
· Through CLI can perform to all the S3 operations from a command line.
(4) Data consistency model
“write once, read many”
Amazon S3 Standard: data store in a minimum of three AZs
Amazon S3-One Zone Infrequent Access: data store in a single AZ
“read-after-write consistency”
Eventually consistent system: the data is automatically replicated and propagated across multiple systems and across multiple AZs within a region, so sometimes you will have a situation where you won’t be able to see the updates or changes instantly.
Update case: if you PUT to an existing key, a subsequent read might return the old data or the updated data, but it will never write corrupted or partial data.
No object locking: the request with the latest time stamp wins. (User can achieve object locking by building it into the application)
(5) Performance considerations
Partition: If the workload you are planning to run on an Amazon S3 bucket is going to exceed 100 PUT/LIST/DELETE requests per second or 300 GET requests per second.
S3 automatically partitions based on the key prefix (chapter2/image/… → ‘c’).
Change the chapter name to start with a number, such as 2chapter, 3chapter, 4chapter.
| Bucket | Object Key |
|---|---|
| awsbook | chapter2/image/image2.1.jpg→2chapter/image/image2.1.jpg |
| awsbook | chapter2/image/image2.2.jpg→2chapter/image/image2.2jpg |
The partition: awsbook/2, awsbook/3, awsbook/4, …
Reverse the key name string
| Bucket | Object Key |
|---|---|
| applicationid | 5213332112/log.text→2112333125/log.text |
| applicationid | 5213332112/error.text→2112333125/error.text |
| applicationid | 5213332113/log.text→3112333125/log.text |
| applicationid | 5213332113/error.text→3112333125/error.text |
The partition: applicationid/2, applicationid /3, applicationid /4, …
Add a hex hash prefix to a key name (can introduce some randomness)
| Bucket | Object Key |
|---|---|
| applicationid | 5213332112/log.text→112a5213332112/log.text |
| applicationid | 5213332112/error.text→c9125213332112/error.text |
| applicationid | 5213332113/log.text→2a825213332113/log.text |
| applicationid | 5213332113/error.text→7a2d5213332113/error.text |
(6) Encryption
Encryption of data in transit
Secure the data when it is moving from one point to other.
Upload data using HTTPS and SSL-encrypted endpoints -> data automatically secured for all the uploads and downloads.
Data is encrypted before being upload to an S3 bucket using an S3-encrypted client -> data is already encrypted in transit.
Encryption of data at rest
Secure the data or the objects in S3 buckets when the objects remain idle in the S3 bucket and there is no activity going on with them.
With Amazon S3 Server Side Encryption (SSE), Amazon S3 will automatically encrypt the data on write and decrypt the data on retrieval. This uses Advanced Encryption Standard (AES) 256-bit symmetric keys, and there are three different ways to manage those keys.
· SSE with Amazon S3 Key Management (SSE-SE)
S3 will encrypt your data at rest and manage the encryption keys for you.
· SSE with customer-provided keys (SSE-C)
S3 will encrypt your data at rest using the custom encryption keys that you provide.
· SSE with AWS Key Management Service KMS (SSE-KMS)
S3 will encrypt your data at rest using keys that you manage in AWS KMS.
(7) Access Control
Access Policies
Create IAM policy and provide fine-grained control
over objects in S3.
ARN (Amazon resource name):
arn : partition : service : region : account-id : resource
arn : partition : service : region : account-id : resourcetype/resource

Bucket Policies
Create policies at the bucket level, allow fine-grained control.
Can incorporate user restrictions without using IAM, can even grant other AWS accounts or IAM user permissions for buckets or any folders or objects inside it.

ACL (Access Control List)
Apply access control rules at the bucket or object level in S3.
Each bucket and object inside the bucket has an ACL associated with it.
Don’t allow fine-grained control.
(8) S3 Storage Class
Amazon S3 Standard
Default storage type, use for frequently accessed data.
Purposes: websites, content storage, big data analysis, mobile applications…
Amazon S3 Standard Infrequent Access (IA)
Use for less frequently accessed data.
Purposes: long-term storage, backups, disaster recovery
Amazon S3 Reduced Redundancy Storage (RRS)
Store noncritical, nonproduction data. (the cost now is similar to S3 Standard)
eg.video encoding: master copy in S3 Standard, different resolution modes 1080, 720… in RRS
Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA)
Store less frequently accessed but requires rapid access data
Amazon Glacier
Use for data archiving
Notes:
Move files from one storage class to another:
· Create a lifecycle policy
· Run S3 copy command (aws s3 cp) from the AWS CLI
· From the Amazon S3 console
· From an SDK
(9) Versioning of Objects in Amazon S3
Amazon S3 starts preserving the existing files in a bucket anytime you perform a PUT, POST, COPY, or DELETE operation on them with versioning enabled.
Once you enable versioning, you can’t disable it. However, you can suspend versioning to stop the versioning of objects.
(10)Amazon S3 Lifecycle Management
Transition action, Expiration action
(11)Amazon S3 Cross-region Replication
Cross-region replication (CRR):
Automatically copy the files from one region to another.
Only the new objects. If you have preexisting files in the bucket, you must copy them manually from the source to the destination using an S3 copy or via the CLI or SDK.
(12)Static Website Hosting in Amazon S3
A static web site may contain some client-side scripts, but the content of the web site is almost stagnant all the time.
a dynamic web site is one where the content changes frequently, and a lot of server-side processing happens by running scripts built on PHP, JSP, and so on.
Notes: Amazon S3 does not support server-side scripting.
3. Amazon Glacier
(1) Common Use Cases
Magnetic tape replacement
Healthcare / life sciences / scientific data storage
Media assets archiving / digital preservation
Compliance archiving / long-term backup
(2) Key Terminology
Archive: If store a file, there will be an archive with a single file.
Notes:
· “write-once”: once create → can’t modify the files in it.
· Immutable: create → can’t update
update/ edit: download →modify → re-upload
Vault: Group multiple archives and put them in a vault, it is like a safe deposit box or a locker.
Notes:
· A vault gives the ability to organize data residing in Amazon Glacier.
· When delete a vault, it should not contain any archive.
Inventory / Vault Inventory: Glacier maintains a cold index of archives refreshed every 24 hours.
Glacier Job: Whenever you want to retrieve an archive and vault inventory, you need to submit a Glacier job, which is going to run behind the scenes to deliver you the files requested.
Amazon Glacier supports notifications.
(3) Accessing Amazon Glacier
3 ways to access:
Directly via Amazon Glacier API or SDK
Via Amazon S3 lifecycle integration
Via various third-party tools and gateways
(4) Uploading Files to Amazon Glacier
3 ways to upload:
Use internet directly to upload files
Use Direct Connect to upload files from the corporate data center
Use AWS Snowball to ship the large number of files or huge dataset and upload them
Steps:
Create a vault → Create an access policy → Create the archives and upload them
(5) Retrieving Files from Amazon Glacier
3 ways to retrieve:
Standard: retrieve data in a few hours, typically takes 3 to 5 hours
Expedited: occasional urgent access to a small number of archives, almost instantly within 1 to 5 minutes
Bulk: lowest-cost option optimized for large retrievals, up to PB data, takes 5 to 12 hours
Steps:
Submit a retrieval job → Depend on the job type, take time to complete it → Get a notification when complete → Download the output
4. Amazon EBS (Elastic Block Store)
Offer persistent storage for Amazon EC2 instances. (Persistent storage: independent, outside the life span of an EC2 instance)
(1) Usage
Leverage as an EC2 instance’s boot partition
Attach to a running EC2 instance as a standard block device
Notes:
· Multiple EBS volumes to an EC2 instance, but an EBS volume only to an EC2 instance.
· Detach/reattach an EBS volume between instances within the same AZ, can’t do this across different AZs.
· Once attach the EBS volume to the EC2 instance, you can create a file system on top of that, and then can run any kind of workload on EBS volumes, such as databases, applications, big data workloads, NoSQL databases, websites and so on.
· When used as a boot partition, the EC2 instances can be stopped and subsequently restarted and due to its persistence, all the data storing in the EBS can always stays as is after restart.
Create point-in-time consistent snapshots which can then stored in S3 and automatically across multiple AZs.
Notes:
· Snapshots can be used as the starting point for new EBS volumes and protect the data for long-term durability.
· Share snapshots with co-workers / other AWS developers / another account.
· Snapshots can be copied across multiple regions, can get data quickly and provision the infrastructure in disaster recovery, data center migration or geographical expansion.
(2) Features
Persistent Storage
General Purpose
High Availability and Reliability
Encryption
Variable Size
Easy to Use
Designed for Resiliency (弹性设计)
(3) 3 Types of Block Storage Offerings
Amazon EC2 instance store
The local storage of an EC2 instance, can’t be mounted into different servers.
Ephemeral, all the data stored in it is gone the moment the EC2 instance is shut down.
No snapshot support.
The instance store is available in a SSD or HDD.
Amazon EBS SSD-backed volume
Mainly used for transactional workloads such as databases and boot volumes.
· General-Purpose SSD (gp2)
Balance price and performance for a wide variety of transactional data.
Single-digit millisecond latencies.
gp2 under 1TB can burst the IO.
Not use IOPS → IO credit → Used as IO during peak loads.
Good use cases: system boot volumes; applications requiring low latency; virtual desktops; development and test environments and so on.
· Provisioned IOPS SSD (io1)
The highest performance for latency-sensitive transactional workloads.
Predictable and consistence IO performance.
Can create an io1 volume between 4GB to 16TB and specify anything between 100 to 20,000 IOPS (limit) per volume. The ratio for volume versus Provisioned IOPS is 1:50.
Good use cases: database workloads such as Oracle, PostgreSQL, MySQL, Microsoft SQL Server, Mongo DB and Cassandra; running mission-critical applications; running production databases which needs sustained IO performance and so on.
Amazon EBS HDD-backed volume
Used for throughput-intensive workloads such as log processing and mapreduce.
· Throughput-Optimized HDD (st1)
Used for frequently accessed, throughput-intensive workloads
Magnetic drives, define the performance metrics in terms of throughput instead of IOPS.
Workloads can leverage st1: data warehouses, ETL, log processing, mapreduce jobs and so on.
Ideal for the workload that involves sequential IO.
Any workload that has a requirement for random IO should be run either on gp2 or on io1 depending on the price/performance need.
Like gp2, st1 also uses a burst-bucket model for performance.
· Cold HDD (sc1)
Used for less frequently accessed data that has the lowest cost.
Like st1, define the performance metrics in terms of throughput instead of IOPS.
Use a burst-bucket model, but the burst capacity is less.
Used for noncritical, cold data workloads and is designed to support infrequently accessed data.
5. Amazon EFS (Elastic File System)
EFS provides a file system interface and file system semantics to EC2 instances. (提供文件系统接口和文件系统语义)
Local file system: when attached to an EC2 instance.
Shared file system: can mount the same file system across multiple EC2 instances; can share access to the data with low latencies between multiple EC2 instances.
Use cases:
· Transfer a large number of data from the servers running on your premise to the AWS cloud.
· For the workload on your premise that needs additional compute, you can leverage EFS and EC2 servers to offload some of the application workload processing to the cloud.
· Use EFS to backup files to the cloud.
(1) Attributes
Fully managed
File system access semantics
File system interface
Shared storage
Elastic and scalable
Performance
Highly available and durable
(2) Using Amazon EFS
Four steps:
· Create a file system
· Create a mount target in each AZ from which you want to access the file system.
· Run the mount command from the EC2 instance on the DNS name of the mount of EFS
· Start using the EFS
Notes:
· A mount target is an NFS v4 endpoint in your VPC.
· A mount target has an IP address and a DNS name you use in your mount command.
· Some of the most common use cases: genomics, big data analytics, web serving, home directories, content management, media-intensive jobs…
(3) Performance Mode of EFS
General-purpose Mode
default mode
Optimize for latency-sensitive applications and general-purpose file-based workloads.
Max I/O Mode
Optimize for large-scale and data-heavy applications where tens, hundreds, or thousands of EC2 instances are accessing the file system.
Notes: Can use CloudWatch metrics to get visibility into EFS’s performance.
6. On-premise Storage Integration with AWS
When you are planning to transfer more than 10TB of data, you can integrate your on-premise storage with AWS.
(1) AWS Storage Gateway
It is deployed as a virtual machine in your existing environment, you can connect your existing applications, storage systems or devices to this storage gateway.
Three storage interfaces:
File gateway
Volume gateway
Tape gateway
(2) AWS Snowball and AWS Snowball Edge
Snowball is an AWS import/export tool that provides a petabyte-scale data transfer service that uses Amazon-provided storage devices for transport.
Once the Snowballs are received and set up, customers are able to copy up to 80TB data from their on-premises file system to the Snowball via the Snowball client software and a 10Gbps network interface.
Snowball Edge, like the original Snowball, but it transports more data, up to 100TB of data.
(3) AWS Snowmobile
Snowmobile is a secure, exabyte-scale data transfer service used to transfer large amounts of data into and out of AWS, its each instance can transfer up to 100PB.