python时间序列-----中篇---python进行数据分析 period 、timestamp、 periodindex、 date_range、 resample、 OHLC、
目录
时期及其算数运算
时期的频率转换
按季度计算的时期频率
将Timestamp转换为Period(及其反向过程)
通过数组创建PeriodIndex
重采样及频率转换
降采样
OHLC重采样
通过groupby进行重采样
升采样和插值
通过时期进行重采样
时期及其算数运算
时期-period 表示的是时间区间,比如数日,数月,数季,数年等。
>>> p = pd.Period(2007,freq='A-DEC')
>>> p
Period('2007', 'A-DEC')
>>> p+5,p-2
(Period('2012', 'A-DEC'), Period('2005', 'A-DEC'))
如果两个Period对象拥有相同的频率,则它们差的就是他们之间的单位数量
>>> pd.Period(2014,freq='A-DEC') - p
7L创建时间范围
>>> rng = pd.period_range('1/1/2000','6/30/2000',freq='M')
>>> rng
PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '2000-06'], dtype='period[M]', freq='M')
PeriodIndex类保存了一组Period,他可以在任何Pandas数据结构中被用作轴索引:
>>> Series(np.random.randn(6),index=rng)
2000-01 1.784802
2000-02 -1.429045
2000-03 -0.145070
2000-04 -0.443552
2000-05 0.242232
2000-06 -0.442667
Freq: M, dtype: float64PeriodIndex类的构造函数还允许直接使用一组字符串:
>>> value = ['2001Q3','2002Q2','2003Q3']
>>> index = pd.PeriodIndex(value,freq='Q-DEC')
>>> index
PeriodIndex(['2001Q3', '2002Q2', '2003Q3'], dtype='period[Q-DEC]', freq='Q-DEC')
时期的频率转换
>>> p = pd.Period('2007',freq='A-DEC')
>>> p.asfreq('M',how='start')
Period('2007-01', 'M')
>>> p.asfreq('M',how='end')
Period('2007-12', 'M')
对于月度子时期归属情况就不一样了
>>> p = pd.Period('2007','A-JUN')
>>> p.asfreq('M','start')
Period('2006-07', 'M')
>>> p.asfreq('M','end')
Period('2007-06', 'M')超时期-superperiod 是由子时期-subperiod所属的位置决定的
>>> p = pd.Period('2007-08','M')
>>> p.asfreq('A-JUN')
Period('2008', 'A-JUN')
>>> rng = pd.period_range('2006','2009',freq='A-DEC')
>>> ts = Series(np.random.randn(len(rng)),index=rng)
>>> ts
2006 -1.672370
2007 -1.303141
2008 0.470823
2009 0.318962
Freq: A-DEC, dtype: float64
>>> ts.asfreq('M',how='start')
2006-01 -1.672370
2007-01 -1.303141
2008-01 0.470823
2009-01 0.318962
Freq: M, dtype: float64
>>> ts.asfreq('B',how='end')
2006-12-29 -1.672370
2007-12-31 -1.303141
2008-12-31 0.470823
2009-12-31 0.318962
Freq: B, dtype: float64

按季度计算的时期频率
>>> p = pd.Period('2014Q4',freq='Q-JAN')
>>> p
Period('2014Q4', 'Q-JAN')在一月结束的财年中,2012Q4是从11月到1月开始
>>> p = pd.Period('2012Q4',freq='Q-JAN')
>>> p.asfreq('D','start')
Period('2011-11-01', 'D')
>>> p.asfreq('D','end')
Period('2012-01-31', 'D')
获得该季度倒数第二个工作日下午4点的时间戳
>>> p4pm = (p.asfreq('B','e') -1).asfreq('T','s') + 16*60
>>> p4pm
Period('2012-01-30 16:00', 'T')
>>> p4pm.to_timestamp()
Timestamp('2012-01-30 16:00:00')

>>> rng = pd.period_range('2011Q3','2012Q4',freq='Q-JAN')
>>> ts = Series(np.arange(len(rng)),index=rng)
>>> ts
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int32
>>> new_rng = (rng.asfreq('B','e')-1).asfreq('T','s') + 16*60
>>> ts.index = new_rng.to_timestamp()
>>> ts
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int32
将Timestamp转换为Period(及其反向过程)
>>> rng = pd.date_range('1/1/2000',periods=3,freq='M')
>>> ts = Series(np.random.randn(3),index=rng)
>>> pts = ts.to_period()
>>> ts
2000-01-31 0.008677
2000-02-29 1.061882
2000-03-31 0.529983
Freq: M, dtype: float64
>>> pts
2000-01 0.008677
2000-02 1.061882
2000-03 0.529983
Freq: M, dtype: float64
转换为时间戳
>>> pts.to_timestamp(how='end')
2000-01-31 0.008677
2000-02-29 1.061882
2000-03-31 0.529983
Freq: M, dtype: float64通过数组创建PeriodIndex
>>> data = pd.read_csv('D:\python\DataAnalysis\data\macrodata.csv')
>>> data.year[:5]
0 1959.0
1 1959.0
2 1959.0
3 1959.0
4 1960.0
Name: year, dtype: float64
>>> data.quarter[:5]
0 1.0
1 2.0
2 3.0
3 4.0
4 1.0
Name: quarter, dtype: float64>>> index = pd.PeriodIndex(year = data.year,quarter = data.quarter,freq='Q-DEC')
>>> index[:5]
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1'], dtype='period[Q-DEC]', freq='Q-DEC')
>>> data.index = index
>>> data.infl
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
1960Q2 0.14
1960Q3 2.70
1960Q4 1.21
1961Q1 -0.40
1961Q2 1.47
1961Q3 0.80
1961Q4 0.80
1962Q1 2.26
1962Q2 0.13
1962Q3 2.11
1962Q4 0.79
1963Q1 0.53
1963Q2 2.75
1963Q3 0.78
1963Q4 2.46
1964Q1 0.13
1964Q2 0.90
1964Q3 1.29
1964Q4 2.05
1965Q1 1.28
1965Q2 2.54
1965Q3 0.89
1965Q4 2.90
1966Q1 4.99
1966Q2 2.10
...
2002Q2 1.56
2002Q3 2.66
2002Q4 3.08
2003Q1 1.31
2003Q2 1.09
2003Q3 2.60
2003Q4 3.02
2004Q1 2.35
2004Q2 3.61
2004Q3 3.58
2004Q4 2.09
2005Q1 4.15
2005Q2 1.85
2005Q3 9.14
2005Q4 0.40
2006Q1 2.60
2006Q2 3.97
2006Q3 -1.58
2006Q4 3.30
2007Q1 4.58
2007Q2 2.75
2007Q3 3.45
2007Q4 6.38
2008Q1 2.82
2008Q2 8.53
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64>>> data[:5]
year quarter realgdp ... pop infl realint
1959Q1 1959.0 1.0 2710.349 ... 177.146 0.00 0.00
1959Q2 1959.0 2.0 2778.801 ... 177.830 2.34 0.74
1959Q3 1959.0 3.0 2775.488 ... 178.657 2.74 1.09
1959Q4 1959.0 4.0 2785.204 ... 179.386 0.27 4.06
1960Q1 1960.0 1.0 2847.699 ... 180.007 2.31 1.19
[5 rows x 14 columns]重采样及频率转换
重采样-rsampling 指的是将时间序列从一个频率转换为另一个频率的处理过程。将高频率数据聚合到低频率成为降采样-upsampling。并不是所有采样都可以被划分为这两个大类中。
>>> rng = pd.date_range('1/1/2000',periods=100,freq='D')
>>> ts = Series(np.random.randn(len(rng)),index=rng)
>>> ts.resample('M',how='mean')
:1: FutureWarning: how in .resample() is deprecated
the new syntax is .resample(...).mean()
2000-01-31 -0.073764
2000-02-29 0.018607
2000-03-31 -0.292522
2000-04-30 0.363046
Freq: M, dtype: float64
>>> ts.resample('M').mean()
2000-01-31 -0.073764
2000-02-29 0.018607
2000-03-31 -0.292522
2000-04-30 0.363046
Freq: M, dtype: float64
resample是一个灵活高效的方法,可用于处理非常大的时间序列。


降采样
下面是12个1分钟数据
>>> rng = pd.date_range('1/1/2000',periods=12,freq='T')
>>> ts = Series(np.arange(12),index=rng)
>>> ts
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int32
聚合到5分钟中,默认情况下,面元的左边界是包含的,即是00:00到00:05的区间是包含00:05的
>>> ts.resample('5min').sum()
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int32
左包含和右包含
>>> ts.resample('5min').sum()
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int32
>>> ts.resample('5min',closed='left').sum()
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int32
>>> ts.resample('5min',closed='right').sum()
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int32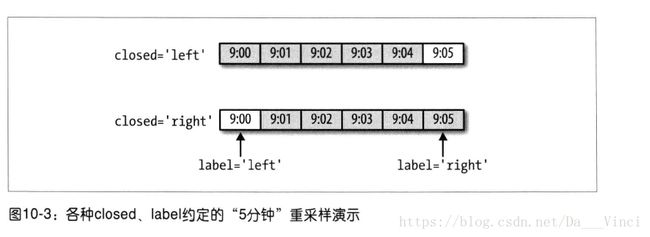
我们可以对索引做一些位移,比如从右边界减去一秒一便更容易明白该时间戳到底是哪个时区。
>>> ts.resample('5min',how='sum',loffset='-1s')
1999-12-31 23:59:59 10
2000-01-01 00:04:59 35
2000-01-01 00:09:59 21
Freq: 5T, dtype: int32OHLC重采样
金融领域有一种无所不在的时间序列聚合方式,即是计算各面元的四个值:开盘-open,收盘-close,最高-high,最低-low
>>> ts.resample('5min').ohlc()
open high low close
2000-01-01 00:00:00 0 4 0 4
2000-01-01 00:05:00 5 9 5 9
2000-01-01 00:10:00 10 11 10 11通过groupby进行重采样
>>> rng = pd.date_range('1/1/2000',periods=100,freq='D')
>>> ts = Series(np.arange(100),index=rng)
>>> ts.groupby(lambda x:x.month).mean()
1 15
2 45
3 75
4 95
dtype: int32
>>> ts.groupby(lambda x: x.weekday).mean()
0 47.5
1 48.5
2 49.5
3 50.5
4 51.5
5 49.0
6 50.0
dtype: float64
升采样和插值
将数据从低频率转换到高频率时,就不需要聚合了。
>>> frame = DataFrame(np.random.randn(2,4),index = pd.date_range('1/1/2000',periods=2,freq='W-WED'),columns=['Colorado','Texas','New York','Ohio'])
>>> frame[:5]
Colorado Texas New York Ohio
2000-01-05 -0.581785 -0.270777 0.885574 -1.072725
2000-01-12 -1.487840 1.603010 0.860155 0.157164
将其重采样到日频率,默认会引入缺失值;
>>> df_daily = frame.resample('D')
>>> df_daily
DatetimeIndexResampler [freq=, axis=0, closed=left, label=left, convention=start, base=0]
>>> df_daily.count()
Colorado Texas New York Ohio
2000-01-05 1 1 1 1
2000-01-06 0 0 0 0
2000-01-07 0 0 0 0
2000-01-08 0 0 0 0
2000-01-09 0 0 0 0
2000-01-10 0 0 0 0
2000-01-11 0 0 0 0
2000-01-12 1 1 1 1 >>> frame.resample('D').ffill()
Colorado Texas New York Ohio
2000-01-05 -0.581785 -0.270777 0.885574 -1.072725
2000-01-06 -0.581785 -0.270777 0.885574 -1.072725
2000-01-07 -0.581785 -0.270777 0.885574 -1.072725
2000-01-08 -0.581785 -0.270777 0.885574 -1.072725
2000-01-09 -0.581785 -0.270777 0.885574 -1.072725
2000-01-10 -0.581785 -0.270777 0.885574 -1.072725
2000-01-11 -0.581785 -0.270777 0.885574 -1.072725通过时期进行重采样
>>> frame = DataFrame(np.random.randn(24,4),index=pd.period_range('1-2000','12-2001',freq='M'),columns=['Colorado','Texas','New York','Ohio'])
>>> frame[:5]
Colorado Texas New York Ohio
2000-01 -0.871782 1.125858 -0.545824 -1.135282
2000-02 0.197301 -0.636073 -0.937487 -0.661491
2000-03 0.026330 -2.000660 -1.352893 1.083992
2000-04 1.183148 1.761140 0.272041 0.300900
2000-05 0.275420 -0.064059 1.472698 0.471408
>>> annual_frame = frame.resample('A-DEC',how='mean')
>>> annual_frame
Colorado Texas New York Ohio
2000 0.742654 0.088633 -0.097009 0.139006
2001 0.068373 -0.373837 0.050390 0.254034
升采样要稍微麻烦一些,
>>> annual_frame.resample('Q-DEC').ffill()
Colorado Texas New York Ohio
2000Q1 0.742654 0.088633 -0.097009 0.139006
2000Q2 0.742654 0.088633 -0.097009 0.139006
2000Q3 0.742654 0.088633 -0.097009 0.139006
2000Q4 0.742654 0.088633 -0.097009 0.139006
2001Q1 0.068373 -0.373837 0.050390 0.254034
2001Q2 0.068373 -0.373837 0.050390 0.254034
2001Q3 0.068373 -0.373837 0.050390 0.254034
2001Q4 0.068373 -0.373837 0.050390 0.254034
>>> annual_frame.resample('Q-DEC',convention='start',fill_method='ffill')
Colorado Texas New York Ohio
2000Q1 0.742654 0.088633 -0.097009 0.139006
2000Q2 0.742654 0.088633 -0.097009 0.139006
2000Q3 0.742654 0.088633 -0.097009 0.139006
2000Q4 0.742654 0.088633 -0.097009 0.139006
2001Q1 0.068373 -0.373837 0.050390 0.254034
2001Q2 0.068373 -0.373837 0.050390 0.254034
2001Q3 0.068373 -0.373837 0.050390 0.254034
2001Q4 0.068373 -0.373837 0.050390 0.254034
由于时期指的是时间区间,所以升采样和将采样的规格就比较严格
在降采样中,目标频率必须是源频率的子时期-subperiod
在升采样中,目标频率必须是源频率的超时期-superperiod
如果不满足这些条件,就会引发异常。