MTCNN+FaceNet实现人脸检测与识别
人脸识别
人脸识别包括两个模块人脸检测(人脸定位)+人脸识别。常用的人脸检测的算法有Dilb,OpenCV,OpenFace,MTCNN等。常用人脸识别的算法包括FaceNet,InsightFace模型等。
本文以MTCNN结合FaceNet实现人脸的检测与识别。
1、MTCNN
MTCNN(Multi-task convolutional neural network,多任务卷积神经网络)是2016年中国科学院深圳研究院提出的用于人脸检测任务的多任务神经网络模型,该模型主要采用了三个级联的网络,采用候选框加分类器的思想,进行快速高效的人脸检测。这三个级联的网络分别是快速生成候选窗口的P-Net、进行高精度候选窗口过滤选择的R-Net和生成最终边界框与人脸关键点的O-Net。和很多处理图像问题的卷积神经网络模型,该模型也用到了图像金字塔、边框回归、非最大值抑制等技术。
MTCNN第一阶段的目标是生成人脸候选框。首先对图片做“金字塔”变换。究其原因,是由于各种原因,使得图片中的人脸的尺度有大有小,识别算法需要适应这种目标尺度的变化;目标检测本质上来说上目标区域内特征与模板权重的点乘操作;那么如果模板尺度与目标尺度匹配,自然会有很高的检测效果。MTCNN使用了图像金字塔来解决目标多尺度问题,即把原图按照一定的比例,多次等比缩放得到多尺度的图片,很像个金字塔。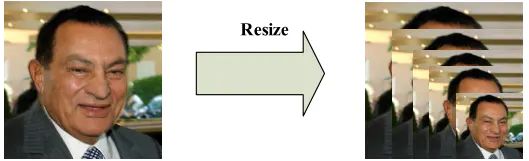
而P-NET的模型是用单尺度(1212)的图片训练出来的,推断的时候,想要识别各种尺度的人脸更准,需要把待识别的人脸的尺度先变化到接近模型尺度(1212)。
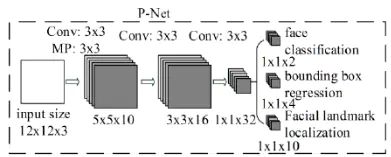
P-NET的输出结果还原到原图上代表了各区域上有人脸的概率,获取到结果后,一方面可以通过切threshold,过滤一些得分低的区域;另一方面可以通过NMS算法,过滤重叠度高的区域。
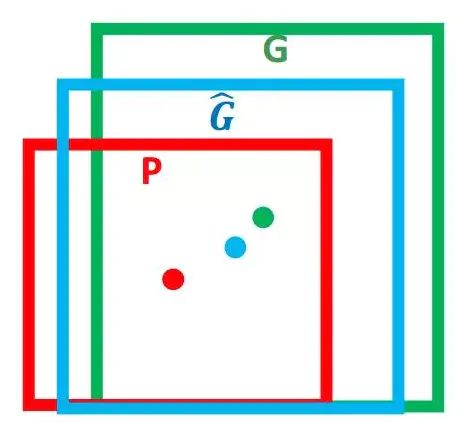
除此之外,还可以使用边框回归(Bounding box regression)修正前面得到的边框区域位置。实际上边框回归是一种映射,使得输入原始的窗口 P(下图红框) 经过映射的结果跟真实窗口G(下图绿框)更接近。
MTCNN的R-NET和O-NET都运用了与P-NET相似的处理过程,每个流程都能同时输出分类的结果,以及修正的值。对所有分类得分高于阈值,且重叠率不高的框进行修正。
P-NET最终将输出很多张可能存在人脸的人脸区域,并将这些区域输入R-Net进行进一步处理。

R-NET相对于第一层P-NET来说,增加了一个全连接层
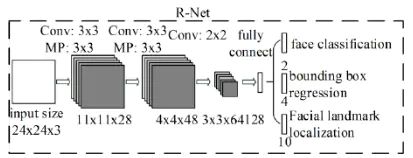
P-Net的输出只是具有一定可信度的可能的人脸区域,在R-NET中,将对输入进行细化选择,并且舍去大部分的错误输入,并再次使用边框回归和面部关键点定位器进行人脸区域的边框回归和关键点定位,最后将输出较为可信的人脸区域,供O-Net使用。对比与P-Net使用全卷积输出的1132的特征,R-Net使用在最后一个卷积层之后使用了一个128的全连接层,保留了更多的图像特征,准确度性能也优于P-Net。

O-NET基本结构是一个较为复杂的卷积神经网络,相对于R-Net来说多了一个卷积层。
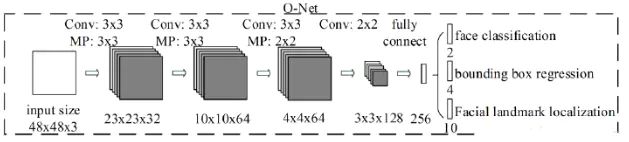
该网络的输入特征更多,在网络结构的最后是一个更大的256的全连接层,保留了更多的图像特征,同时再进行人脸判别、人脸区域边框回归和人脸特征定位,最终输出人脸区域的左上角坐标和右下角坐标与人脸区域的五个特征点。O-Net拥有特征更多的输入和更复杂的网络结构,也具有更好的性能,这一层的输出作为最终的网络模型输出

至此,MTCNN完成了人脸检测的工作,给出一张人脸图像,通过MTCNN可以标记出人脸区域和人脸关键点定位。结合FaceNet模型,就可以识别几张图片是否为同一个人,进而可以推广到更多的领域,包括安检、人脸解锁等。
2、FaceNet
FaceNet模型是由 Google工程师Florian Schroff,Dmitry Kalenichenko,James Philbin提出。FaceNet的主要思想是把人脸图像映射到一个多维空间,通过空间距离表示人脸的相似度。同个人脸图像的空间距离比较小,不同人脸图像的空间距离比较大。这样通过人脸图像的空间映射就可以实现人脸识别,FaceNet中采用基于深度神经网络的图像映射方法和基于triplets(三元组)的loss函数训练神经网络,网络直接输出为128维度的向量空间。
FaceNet的网络结构如下图所示,其中Batch表示人脸的训练数据,接下来是深度卷积神经网络,然后采用L2归一化操作,在接入Embedding(嵌入)层,得到人脸图像的特征表示,最后为三元组(Triplet Loss)的损失函数。
所谓嵌入,可以理解为一种映射关系,即将特征从原来的特征空间中映射到一个新的特征空间,新的特征就可以称为原来特征的一种嵌入。

这里的映射关系是将卷积神经网络末端全连接层输出的特征映射到一个超球面上,然后再以Triplet Loss为监督信号,获得网络的损失与梯度。
而Triplet Loss,就是根据三元组(Triplet)计算而来的损失(Loss)。其中,三元组由Anchor(A),Negative(N),Positive(P)组成,任意一张图片都可以作为一个基点(A),然后与它属于同一人的图片就是它的P,与它不属于同一人的图片就是它的N。其学习目标如下: 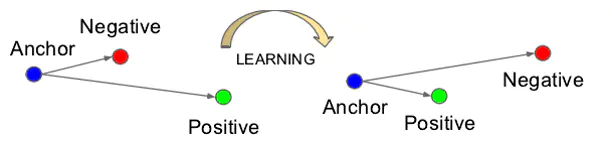 网络没经过学习之前,A和P的欧式距离可能很大,A和N的欧式距离可能很小,如上图左边,在网络的学习过程中,A和P的欧式距离会逐渐减小,而A和N的距离会逐渐拉大。网络会直接学习特征间的可分性:同一类的特征之间的距离要尽可能的小,而不同类之间的特征距离要尽可能的大。
FaceNet的最终结果可以获得人脸数据的特征向量,然后计算两张图片之间特征向量的欧氏距离,可以直接表示两张图片的差异。
3、opencv实现人脸检测
除了以上的深度学习方法,我们还可以用OpenCV中已经包装好的库实现人脸识别。
OpenCV 3有三种人脸识别的方法,它们分别基于不同的三种算法,Eigenfaces,Fisherfaces和Local Binary Pattern Histogram。
这些方法都有一个类似的过程,即都使用分好类的训练数据集来进行训练,对图像或视频中检测到的人脸进行分析,并从两方面来确定:是否识别到目标;目标真正被识别到的置信度的衡量,这也称为置信度评分,在实际应用中可以通过设置阈值来进行筛选,置信度高于该阈值的人脸将会被丢弃。
这里我们主要来介绍一下利用特征脸进行人脸识别的方法,特征脸法,本质上其实就是PCA降维,这种算法的基本思路是,把二维的图像先灰度化,转化为一通道的图像,之后再把它首尾相接转化为一个列向量,假设图像大小是20*20的,那么这个向量就是400维,理论上讲组织成一个向量,就可以应用任何机器学习算法了,但是维度太高算法复杂度也会随之升高,所以需要使用PCA算法降维,然后使用简单排序或者KNN都可以。
#1、生成自己人脸识别数据
def generator(data):
'''
生成的图片满足以下条件
1、图像是灰度格式,后缀为.pgm
2、图像大小要一样
params:
data:指定生成的人脸数据的保存路径
'''
'''
打开摄像头,读取帧,检测帧中的人脸,并剪切,缩放
'''
name = input('my name:')
#如果路径存在则删除
path = os.path.join(data,name)
if os.path.isdir(path):
#os.remove(path) #删除文件
#os.removedirs(path) #删除空文件夹
shutil.rmtree(path) #递归删除文件夹
#创建文件夹
os.mkdir(path)
#创建一个级联分类器 加载一个 .xml 分类器文件. 它既可以是Haar特征也可以是LBP特征的分类器.
face_cascade = cv2.CascadeClassifier('./haarcascades/haarcascade_frontalface_default.xml')
#打开摄像头
camera = cv2.VideoCapture(0)
cv2.namedWindow('Dynamic')
#计数
count = 1
while(True):
#读取一帧图像
ret,frame = camera.read()
#判断图片读取成功?
if ret:
gray_img = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#人脸检测
faces = face_cascade.detectMultiScale(gray_img,1.3,5)
for (x,y,w,h) in faces:
#在原图像上绘制矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
#调整图像大小 和ORL人脸库图像一样大小
f = cv2.resize(frame[y:y+h,x:x+w],(92,112))
#保存人脸
cv2.imwrite('%s/%s.pgm'%(path,str(count)),f)
count += 1
cv2.imshow('Dynamic',frame)
#如果按下q键则退出
if cv2.waitKey(100) & 0xff == ord('q') :
break
camera.release()
cv2.destroyAllWindows()
#2、读取ORL人脸数据库 准备训练数据
def LoadImages(data):
'''
加载数据集
params:
data:训练集数据所在的目录,要求数据尺寸大小一样
ret:
images:[m,height,width] m为样本数,height为高,width为宽
names:名字的集合
labels:标签
'''
images = []
labels = []
names = []
label = 0
#过滤所有的文件夹
for subDirname in os.listdir(data):
subjectPath = os.path.join(data,subDirname)
if os.path.isdir(subjectPath):
#每一个文件夹下存放着一个人的照片
names.append(subDirname)
for fileName in os.listdir(subjectPath):
imgPath = os.path.join(subjectPath,fileName)
img = cv2.imread(imgPath,cv2.IMREAD_GRAYSCALE)
images.append(img)
labels.append(label)
label += 1
images = np.asarray(images)
labels = np.asarray(labels)
return images,labels,names
def FaceRec(data):
#加载训练数据
X,y,names=LoadImages('./face')
model = cv2.face.EigenFaceRecognizer_create()
model.train(X,y)
#创建一个级联分类器 加载一个 .xml 分类器文件. 它既可以是Haar特征也可以是LBP特征的分类器.
face_cascade = cv2.CascadeClassifier('./haarcascades/haarcascade_frontalface_default.xml')
#打开摄像头
camera = cv2.VideoCapture(0)
cv2.namedWindow('Dynamic')
while(True):
#读取一帧图像
ret,frame = camera.read()
#判断图片读取成功?
if ret:
gray_img = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#人脸检测
faces = face_cascade.detectMultiScale(gray_img,1.3,5)
for (x,y,w,h) in faces:
#在原图像上绘制矩形
frame = cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray_img[y:y+h,x:x+w]
try:
#宽92 高112
roi_gray = cv2.resize(roi_gray,(92,112),interpolation=cv2.INTER_LINEAR)
params = model.predict(roi_gray)
print('Label:%s,confidence:%.2f'%(params[0],params[1]))
cv2.putText(frame,names[params[0]],(x,y-20),cv2.FONT_HERSHEY_SIMPLEX,1,255,2)
except:
continue
cv2.imshow('Dynamic',frame)
#如果按下q键则退出
if cv2.waitKey(100) & 0xff == ord('q') :
break
camera.release()
cv2.destroyAllWindows()