Spark SQL 本地开发环境搭建和案例分析
我的 Scala 基础教程
1_Spark APIs 的演变
Spark SQL,作为Apache Spark大数据框架的一部分,主要用于结构化数据处理和对Spark数据执行类SQL的查询。通过Spark SQL,可以实现多种大针数据业务,比如对PG/TG级别的数据分析、分析预测并推荐、对不同格式的数据执行ETL操作(如JSON,Parquet,MySQL)然后完成特定的查询操作。
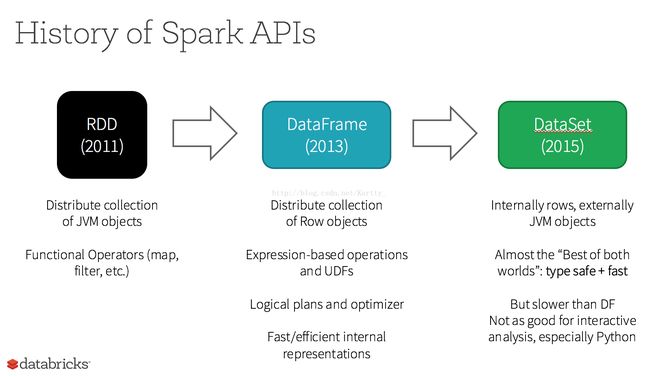
关系:
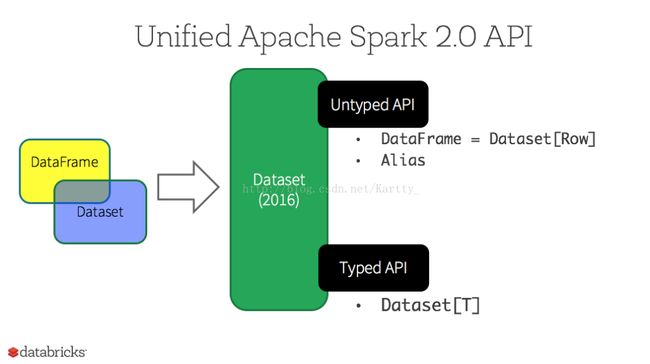
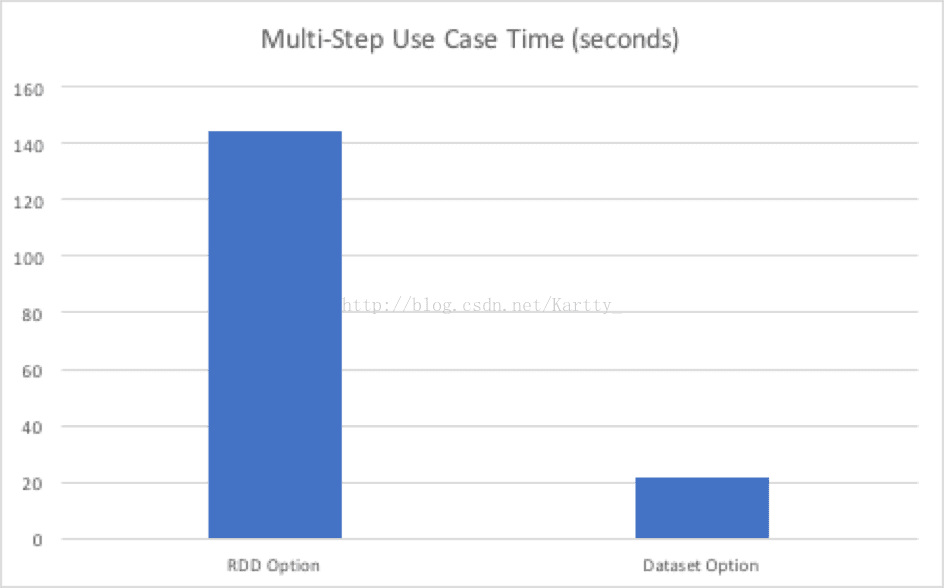
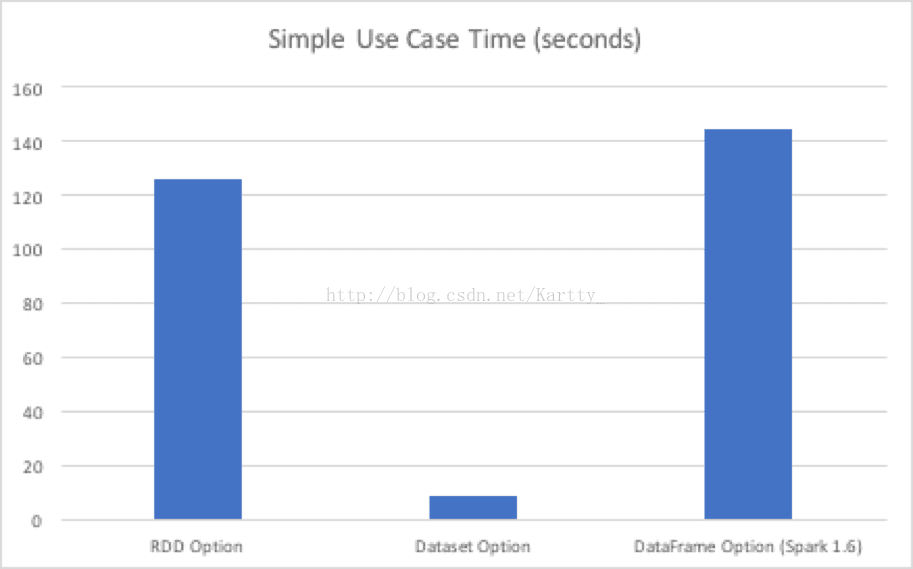
性能对比:
弹性数据集(RDD)
RDD是Spark建立之初的核心API。 RDD是不可变分布式弹性数据集,在Spark集群中可跨节点分区,并提供分布式 low-level API来操作RDD,包括transformation和action。
DataFrame
DataFrame与RDD相同之处,都是不可变分布式弹性数据集。不同之处在于,DataFrame的数据集都是按指定列存储,即结构化数据。类似于传统数据库中的表。 DataFrame的设计是为了让大数据处理起来更容易。DataFrame允许开发者把结构化数据集导入DataFrame,并做了higher-level的抽象; DataFrame提供特定领域的语言(DSL)API来操作你的数据集。
Datasets
map, flatMap, filter。
2_搭建本地开发环境
(1)从群文件中下载 sbt-0.13.8.tar,解压
![]()
下载 .ivy2.zip,避免从外网下载相关 jar,节约时间,解压到 C:\Users\你的用户名,解压时不要选择 “解压到 .ivy” 选项
也可以用 maven 搭建项目,此处介绍 sbt
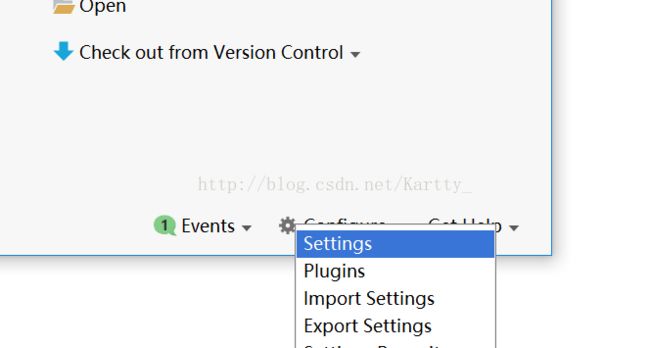
(2)在初始界面,点击 Configures -> Settings
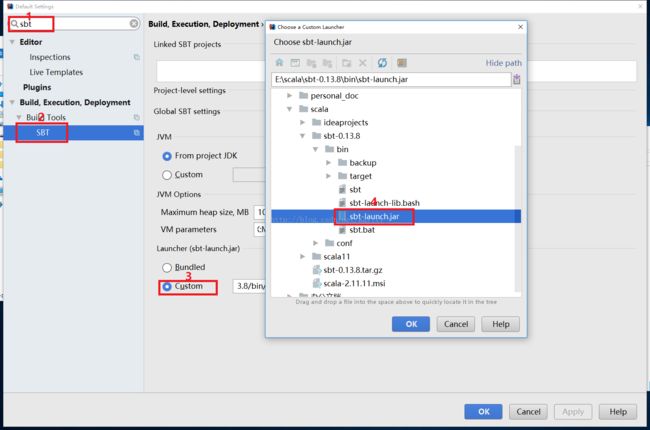
(3)1、搜索 sbt -> 2、 点击SBT工具 -> 3、更改Custom -> 4、选择上一步解压后bin下面的 sbt-launch.jar -> Apply -> OK
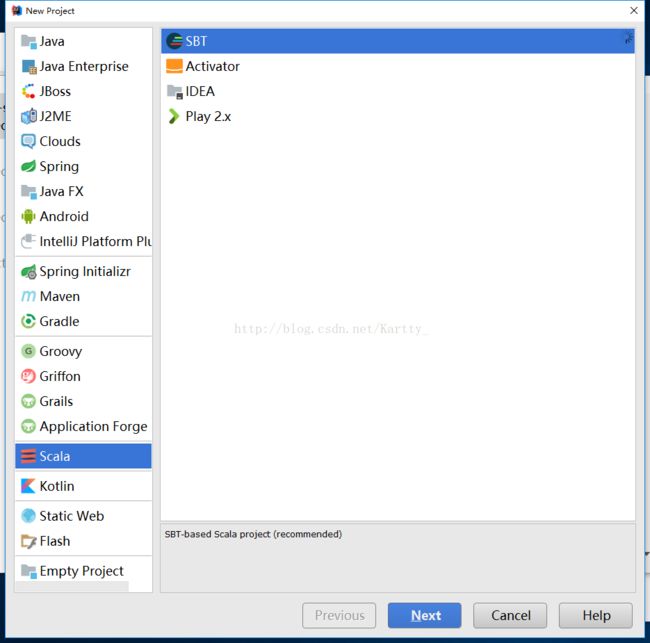
(4)回到初始界面,点击创建新项目
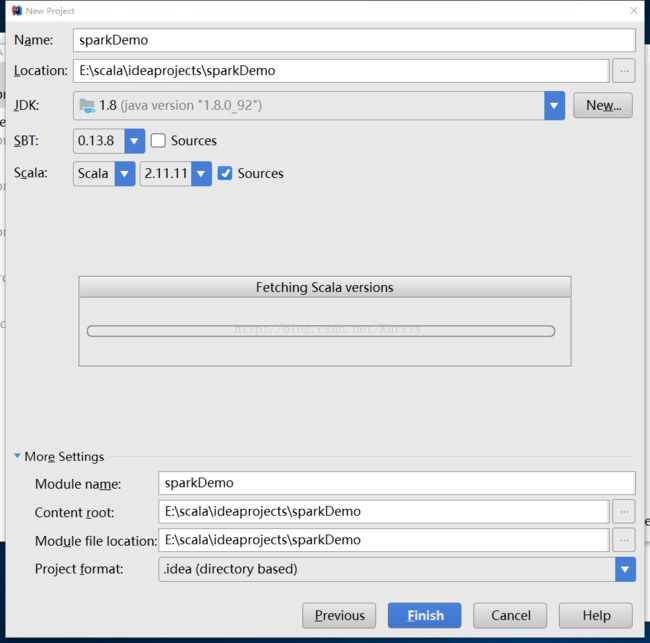
(5)如下图所示选择各种版本,点击 Finish
2_编写 spark 应用
(1)添加依赖,编辑 build.sbt 文件
(2)添加下面的代码
lazy val sparkVer = "2.1.1"
lazy val scalaVer = "2.11"
libraryDependencies ++= Seq(
"org.apache.spark" % s"spark-core_$scalaVer" % sparkVer,
"org.apache.spark" % s"spark-sql_$scalaVer" % sparkVer
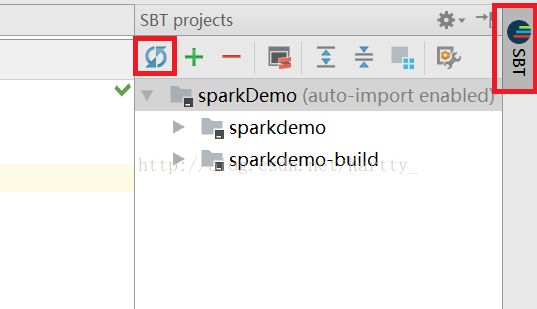
)点击右侧的 SBT 工具栏,再点击 蓝色 的刷新按钮,等待相关 jar 下载完成。目前的配置是从 aliyun nexus 下载。
(3)新建 driver program 入口
右击 scala 包名 -> New -> Scala Class

(4)选择 Object,scala 里只有 Object 里的方法和变量是静态的,只有这样才能声明 main 方法。

(5)写 main 方法,run 后可得结果。
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.master("local[4]") //使用本地内置 4核CPU master
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
val dataframe = spark.read.json("src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
dataframe.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
}3_更多 spark 案例
demo (1-2)为最基本的查询方式,不涉及修改数据,也不是万能的。
(1)接上例,DataFrames 就是 Rows 的 Dataset。这些操作也被归类为无类型的转换 “untyped transformations”,与之相比,强类型的 Datasets 被称之为有类型的转换 “typed transformations”:
// This import is needed to use the $-notation
import spark.implicits._
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// Select everybody, but increment the age by 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// Select people older than 21
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// Count people by age
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+(2)或者直接使用 sql 语句,如果同时读取多个数据源,并注册成临时表,则可以直接跨表查询。
// Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+//case class 省略了构造器和 getter setter 方法的声明,编译为 .class 后和 java 类无异。
case class Person(name: String, age: Long)
//申明一个“序列”,Seq 就是一种集合
val seq = Seq(Person("Andy", 32))
//隐式地为 case classes 创建 Encoders(scala 自动检测),如果是 Java,则必须明确的传入一个
//Encoder personEncoder = Encoders.bean(Person.class);
//正是这种隐式特性的广泛使用,使得scala更简洁
val caseClassDS = seq.toDS() //转换为 DataSet
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
//map(_ + 1) 中的 "_" 指代上一步集合中的每个变量,map 算子传入一个匿名函数为参数,作用是为每个值加 1
//collect() 将各个节点的数据收集到当前 driver program(main 所在的 JVM 进程)
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
//如果用 java 写这一段,则复杂很多,虽然 java8 的 lambda 有所改进,但有些地方仍然很啰嗦,如下:
Encoder integerEncoder = Encoders.INT();
Dataset primitiveDS = spark.createDataset(Arrays.asList(1, 2, 3), integerEncoder);
Dataset transformedDS = primitiveDS.map(new MapFunction() {
@Override
public Integer call(Integer value) throws Exception {
return value + 1;
}
}, integerEncoder);
transformedDS.collect();
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+其他更多详细教程见官网:
https://spark.apache.org/docs/latest/sql-programming-guide.html