8.Flink 广播变量\累加器

1. 广播变量
1.1 介绍
在Flink中,同一个算子可能存在若干个不同的并行实例,计算过程可能不在同一个Slot中进行,不同算子之间更是如此,因此不同算子的计算数据之间不能像Java数组之间一样互相访问,而广播变量Broadcast便是解决这种情况的. 在 flink 中,针对某一个算子需要使用公共变量的情况下,就可以把对应的数据给
广播出去,这样在所有的节点中都可以使用了
注意点:
- 广播变量中封装的数据集的大小要适宜,太大容易造成OOM
- 广播变量中封装的数据要求是可序列化的,否则不能在网络上进行传输
1.2 有界流DataSet进行join操作
1.2.1 源码
package com.jd.bounded.sample_join
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
/**
* Description DataSet进行join
* 需求: 有两个有界流,其中一个有界流中存储的是性别信息,另一个有界流存储的是学生信息,需要将学生的信息完整显示
*
* @author lijun
* @create 2020-03-29
*/
object JoinTest {
def main(args: Array[String]): Unit = {
//1.环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.获取两个DataSet
val ds1 = env.fromElements((1,'男'),(2,'女'))
val ds2 = env.fromElements((101,"jackson",1,"上海"),(104,"jane",2,"天津"),(108,"leon",1,"重庆"))
//3.进行join计算,并输出结果
ds1.join(ds2)
.where(0)//添加一个条件,左侧dataSet中的每个tuple类型的元素中的具体值,此处0代表性别
.equalTo(2) //添加相等的条件 2代表右侧中tuple中的性别元素
.map(perEle=>{
val genderTuple = perEle._1
val stuInfoTuple = perEle._2
(stuInfoTuple._1,stuInfoTuple._2,genderTuple._2,stuInfoTuple._4)
})
.print()
}
}
1.2.2 效果

1.3 有界流使用广播变量对Join进行优化
原因: 进行join时,若一方DataSet中存储了海量的数据,另外一方数据量较小,会给下游的reduce造成压力,很容易出现数据倾斜
优化方案:
使用广播变量进行优化,将reduce端全局聚合的压力进行缓解,通过向每一个TaskManager进程的内存中分发一个广播变量,让所有的处理操作在map端完成
join使用的场合:待join的数据量不是很庞大的场合
1.3.1 源码
package com.jd.bounded.sample_broadcast
import java.util
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import scala.collection.JavaConversions._
import scala.collection.mutable
/**
* Description
* 需求: 有两个有界流,其中一个有界流中存储的是性别信息,另一个有界流存储的是学生信息,需要将学生的信息完整显示
* @author lijun
* @create 2020-03-29
*/
object BroadcastDemo {
def main(args: Array[String]): Unit = {
//1.环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.获取两个DataSet
val ds1: DataSet[(Int, Char)] = env.fromElements((1,'男'),(2,'女'))
val ds2 = env.fromElements((101,"jackson",1,"上海"),(104,"jane",2,"天津"),(108,"leon",1,"重庆"))
//3.将ds1作为广播变量送往每个TaskManager进程的内存中进行处理,并输出结果
ds2.map(new RichMapFunction[(Int,String,Int,String),(Int,String,Char,String)] {
//用来存储从广播变量中获取的值
var container:mutable.Map[Int,Char] = _
/**
* 用来进行初始化操作的,针对一个DataSet,该方法只会执行一次
* @param parameters
*/
override def open(parameters: Configuration): Unit = {
container = mutable.Map()
//获得广播变量中封装的性别信息
val lst: util.List[(Int,Char)] = getRuntimeContext.getBroadcastVariable("genderInformations")
//将信息拿出来,存入到Map集合中
for((id:Int,gender:Char) <-lst){
container.put(id,gender)
}
}
/**
* 每次分析DataSet中的一个元素时,该方法就会触发一次
* @param value
* @return
*/
override def map(value: (Int, String, Int, String)): (Int, String, Char, String) = {
val genderFlg = value._3
val gender = container.getOrElse(genderFlg,'x')
(value._1,value._2,gender,value._4)
}
}).withBroadcastSet(ds1,"genderInformations")
.print()
}
}
1.4 无界流使用广播流变量优化Join操作
1.4.1 源码
package com.jd.unbounded.sample_broadcast
import org.apache.flink.api.common.state.MapStateDescriptor
import org.apache.flink.api.common.typeinfo.BasicTypeInfo
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.datastream.BroadcastStream
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction
import org.apache.flink.streaming.api.scala.{BroadcastConnectedStream, DataStream, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
/**
* Description
* 需求: 有两个无界流,其中一个无界流中存储的是性别信息,另一个无界流存储的是学生信息,需要将学生的信息完整显示
* @author lijun
* @create 2020-03-29
*/
object BroadcastUnboundedTest {
def main(args: Array[String]): Unit = {
//1.环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.获取两个无界流
val dstream1: DataStream[(Int, Char)] = env.fromElements((1,'男'),(2,'女'))
val dstream2: DataStream[(Int, String, Int, String)] = env.socketTextStream("localhost",8888)
.filter(_.trim.nonEmpty)
.map(perLine=>{
val arr = perLine.split(",")
val id = arr(0).trim.toInt
val name = arr(1).trim
val genderFlg = arr(2).trim.toInt
val address = arr(3).trim
(id,name,genderFlg,address)
})
//3.将存储性别信息的无界流封装成广播流
val broadcastStateDescriptors: MapStateDescriptor[Integer, Character] = new MapStateDescriptor("genderInfo",BasicTypeInfo.INT_TYPE_INFO,BasicTypeInfo.CHAR_TYPE_INFO)
val bcStream: BroadcastStream[(Int, Char)] = dstream1.broadcast(broadcastStateDescriptors)
//4. 存储了学生的信息无界流与广播流进行connect操作,并使用自定义广播处理函数进行计算,显示结果
//获取广播连接流实例
val bcConnectStream: BroadcastConnectedStream[(Int, String, Int, String), (Int, Char)] = dstream2.connect(bcStream)
//对广播连接流中的元素进行操作
bcConnectStream.process(new MyBroadcastProcessFunction(broadcastStateDescriptors)).print("广播流效果-->")
//5.启动
env.execute()
}
class MyBroadcastProcessFunction(bc:MapStateDescriptor[Integer, Character]) extends BroadcastProcessFunction[(Int, String, Int, String), (Int, Char),(Int,String,Char,String)]{
/**
* 该方法会执行多次,每次分析的是非广播流dstream2中的每个元素
* @param value 封装当前学生的信息
* @param ctx 上下文,用于读取广播变量中的值
* @param out 用来向结果Datastream中发处理后的结果
*/
override def processElement(value: (Int, String, Int, String),
ctx: BroadcastProcessFunction[(Int, String, Int, String), (Int, Char), (Int, String, Char, String)]#ReadOnlyContext,
out: Collector[(Int, String, Char, String)]): Unit = {
//从广播流中获取数据
val genderFlg = value._3
val genderName = ctx.getBroadcastState(bc).get(genderFlg)
out.collect((value._1,value._2,genderName,value._4))
}
/**
* 每次分析的是广播流bcStream中的一个元素
* @param value 当前的性别信息
* @param ctx 上下文,用来设置广播变量中具体要封装的值
* @param out
*/
override def processBroadcastElement(value: (Int, Char),
ctx: BroadcastProcessFunction[(Int, String, Int, String), (Int, Char), (Int, String, Char, String)]#Context,
out: Collector[(Int, String, Char, String)]): Unit = {
val genderFlg = value._1
val genderName = value._2
ctx.getBroadcastState(bc).put(genderFlg,genderName)
}
}
}
1.4.2 测试
socket输入

控制台输出

2. 累加器
2.1 介绍
技术说明
累加器使用之前需要进行注册,需要在富函数中注册
读取累加器的值,需要在无界流应用执行完毕之后,才能读取
在TaskManager进程中的slot所维护的线程中读取累加器的值,结果不正确,只是局部的结果,不是全局的结果,最终的结果需要将所有TaskManager进程中的slot所维护的线程累计后的结果合并起来
若不希望将累加器的值持久化起来,只是进行应用运行期间的监控,可以使用flink分布式集群中的standalone的模式的可视化的客户端进行监控
业务说明
需要统计本次到站的所有旅客中,总的旅客数,体温正常的旅客数,体温异常的旅客数
2.2 实操步骤
2.2.1 代码实现
package com.jd.unbounded.sample_accumulator
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.accumulators.IntCounter
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
/**
* Description flink 累加器演示
* 需求 需要统计本次到站的所有旅客中,总的旅客数,体温正常的旅客数,体温异常的旅客数
*
* @author lijun
* @create 2020-03-30
*/
object AccumulatorTest {
def main(args: Array[String]): Unit = {
//1.环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.获取两个无界流
env.socketTextStream("localhost",8888)
.filter(_.trim.nonEmpty)
.map(perInfo=>{
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).map(new MyRichMapFunction())
.print("累加处理后结果是-->")
//3. 启动
val result = env.execute()
//4. 显示累加器的值
val totalCnt = result.getAccumulatorResult[Int]("totalAcc")
val normalCnt = result.getAccumulatorResult[Int]("normalAcc")
val exceptionCnt = result.getAccumulatorResult[Int]("exceptionAcc")
println(s"本次列车,旅客总数->$totalCnt,体温正常的旅客数->$normalCnt,体温异常的旅客数->$exceptionCnt")
}
//自定义的富函数,因为只有富函数中,才能获取上下文的信息,才能注册累加器,否则不能使用累加器
class MyRichMapFunction extends RichMapFunction[Raytek,(Raytek,String)]{
//统计所有旅客数的累加器
private var totalAcc:IntCounter = _
//统计体温正常旅客数的累加器
private var normalAcc:IntCounter = _
//统计体温异常旅客数的累加器
private var exceptionAcc:IntCounter = _
//初始化,
override def open(parameters: Configuration): Unit = {
//初始化累加器
totalAcc = new IntCounter()
normalAcc = new IntCounter()
exceptionAcc = new IntCounter()
//注册累加器
val context = getRuntimeContext
context.addAccumulator("totalAcc",totalAcc)
context.addAccumulator("normalAcc",normalAcc)
context.addAccumulator("exceptionAcc",exceptionAcc)
}
/**
* 依次分析DataStream中的每个元素 调用n次
* @param value
* @return
*/
override def map(value: Raytek): (Raytek, String) = {
//步骤
//1. 总数累加器累加1
totalAcc.add(1)
//2. 根据当前旅客的体温进行处理
val temperature = value.temperature
val normal = temperature >= 36.3 && temperature <= 37.2
if(normal){ // a 体温正常
normalAcc.add(1)
(value,"恭喜,你的体温正常,可通过")
}else{// b 体温异常
exceptionAcc.add(1)
(value,"抱歉,你的体温偏常,请稍等...")
}
}
}
}
2.2.2 socket源

2.2.3 控制台输出
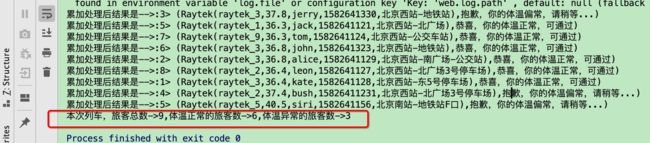
注意点:
只有先 ctrl+c停止 socket源 累加器中的结果才会输出