ICLR论文盲审大反转:三个“8”完美过关,又来两个“1”彻底拒绝
赖可 发自 凹非寺
量子位 出品 | 公众号 QbitAI
一篇投递ICLR2020的论文,得了三个8,是不是表现完美?
事情没有那么简单,额外增加的两个评审又给了两个1。
有网友说:这操作,就是”对冲“分数嘛。
也有网友觉得,虽然论文有问题,但是这样给高分和低分,都过分极端了。
到底怎么回事?
论文
这篇论文提出了一种新的模型,以便在语料中同时捕获语法和全局语义。
怎么做到的?
论文认为传统的RNN语言模型会忽略长距离的单词依赖性,和句子顺序。
新模型将随机-梯度MCMC和循环自编码变分贝叶斯相结合。不仅能够捕获句子内的单词依赖性,还可以捕获句子和句子内部主题依赖性的时间迁移。
在语料库的实验结果表明,这一模型优于现有的RNN模型,并且能够学习可解释的递归多层主题,生成语法正确、语义连贯的句子和段落。

(a)(b)(c)分别是三层rGBN-RNN的生成模型;语言模型组件概述;提出的模型的整体架构
第一轮评审:三个8
第一轮三个评审的分数简直完美,虽然打分很高,评审们都提出了一些建议。
匿名评审1
该方法是将已有的两种方法,伽马信念网络(gamma-belief networks)和叠加RNN相结合,利用递归伽马信念网络的信息对叠加RNN进行改进。
总的来说,这是一篇写得很好的论文,表达清晰,有一定的新意。该方法具有良好的数学表达和实验评价。结果看起来很有趣,特别是对于捕获长期依赖关系,如BLEU分数所示。一个建议是,与基线方法相比,作者没有对所提出方法的复杂性和负载进行计算分析。
匿名评审2
总的来说,我认为这是一篇写得很清楚的论文。我认为这是一份可以接受发表的可靠文件。
一些有待改善的地方:
奇怪的是,不提最近所有备受瞩目的基于LM的预训练的工作,我的印象是,这些模型在大型多句上下文中有效地运行。像BERT和GPT-2这样的模型没有考虑句子之间的关系吗?我想看到更多关于这项工作与之配合的讨论。
我不认为强调这个模型的贡献,即它可以“同时捕获句法和语义”合理。我不清楚其他语言模型是否不能捕获语义(请记住,语义应用于句子中,而不只是在全局级别)——相反,该模型的优势似乎在于捕获句子级别之上的语义关系。如果这是正确的,那就应该更准确地表达出来。
匿名评审3
该模型扩展了以往基于深度rGBN模型的主题引导语言建模方法。虽然模型的新颖性有限,但所提出的模型的学习和推理是有价值的。此外,与SOTA方法相比,本文还展示了该方法在语言建模方面的性能改进,说明了该方法的重要性。
领域主席提出意见之后,另外两个评审给出了1
领域主席意见
这篇论文看起来很有趣,但是最近在语言建模和生成方面的最新成果主要基于Transformer模型。然而,任何对这些模型的比较和提及,似乎都明显地在本文中缺失。我想知道:作者是否与任何模型进行了对比?我怀疑这些模型在某种程度上已经能够捕获主题,可能排除了对本文中提出的方法的需要(但是我很高兴被证明是错误的)。
主席建议研究者,把他们的rGBN-RNN模型和 Transformer-XL进行比较。
作者则表示,rGBN-RNN和Transformer-XL不适合直接比较。因为两者在模型大小、模型建构以及可解释性不同,而且Transformer-XL不尊重自然单词的边界,rGBN-RNN尊重单词-句子-文档的结构。
在这之后,增加的两个匿名评审就画风大变,都给出了1分(拒绝)。
匿名评审4
虽然其基本思想很有趣,但我最大的问题是论文一开始的误导。在第一节的第二段,文章声称基于RNN的LMs经常在句子之间做出独立假设,因此他们开发了一个主题建模方法来对文档级信息建立模型。这种说法存在一些问题。
几乎所有评估语言建模基准的LM论文都使用LSTM / Transformer,通过一种非常简单的方法将所有句子连接起来,并添加唯一的标记来标记句子边界,从而将跨句的文档级信息作为上下文。…………
匿名评审5
模型描述是混乱的,许多陈述没有适当或足够的理由。例如:
(1)在第2页的最后一段,他们声称在他们的模型中使用了语言组件来捕获语法信息,我不太愿意接受;
(2)在第3页的第一段,它说“我们定义d_j为弓向量,只是总结了前面的句子”,没有进一步的信息,我不知道弓向量是什么样子的,它是如何构成的……更重要的是,我认为Eq.(5)是错误的,这让我对他们的整个方法论产生了质疑。……
后两个评审被主席带偏了?还是前三个有问题?
这篇论文争议的关键就是作者使用的新模型有没有和已有的方法做比较。
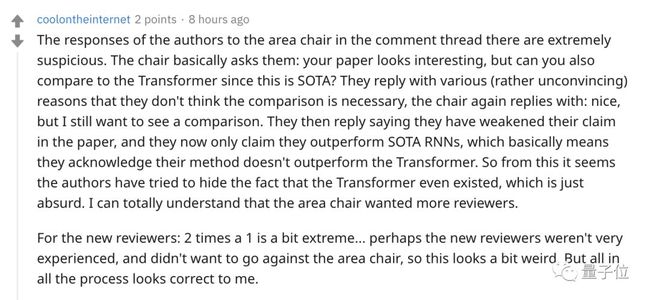
有网友觉得作者自己在回避这个问题
他们以各种理由(没有说服力)回答,他们认为没有必要进行比较,主席再次回答:很好,但是我仍然希望看到一个比较。然后他们回答说,他们削弱了在论文中的主张,现在只声称他们的表现优于SOTA RNN,这基本上意味着他们承认他们的方法没有表现出Transformer更好。因此,从这一点看来,作者似乎试图掩盖Transformer存在的这个事实存在,这是荒谬的。
面对截然相反的打分,网友看法各异。
有人觉得后两个评委一致打最低分,真是“随机”的盲审吗?

也有人觉得两边都有问题,新方法缺少和Transformers的比较是绝对不能打8分的,但是打1分也站不住脚。

还有觉得是主席在“带节奏”,主席觉得评审可以再严谨一些,就找了两个新的评审,这导致新的评审对原先的评审产生了不信任的感觉。

还有网友表示,这个问题具有代表性
这反映了当今机器学习中更广泛的常见问题。评论如此混乱,顶级会议的许多提交都有很大的差异。实际上,论文获得完美的评价和最低的分数是很普遍的。我无法确定所有确切原因,但我相信这与该领域的研究数量和速度有关:论文被立即上传到arxiv,在下一次大会上,就会有许多追随这一研究的,未经过同行评审的研究出现。再加上领域的大容量、年会的压力/期限,而不是每月或每周的科学期刊,这种情况就开始发生。

这究竟是一个特殊情况,还是值得关注的普遍现象?
小编想起,之前身边的同学毕业论文盲审也得到了两级分化的评价。你有没有过类似的经历呢?
传送门
https://openreview.net/forum?id=Byl1W1rtvH