大数据的生态系统
1.存储
Hadoop hdfs
2.计算引擎
map/reduce v1
map/reduce v2(map/reduce on yarn)
Tez
spark
3.Impala Presto Drill 直接跑在hdfs上
pig(脚本方式)hive(SQL语言)跑在map/reduce上
hive on tez/sparkSQL
4.流式计算-storm
5.kv store cassandra mongodb hbase
6. Tensorflow Mahout
7.Zookeeper Protobuf
8. sqoop kafka flume.....
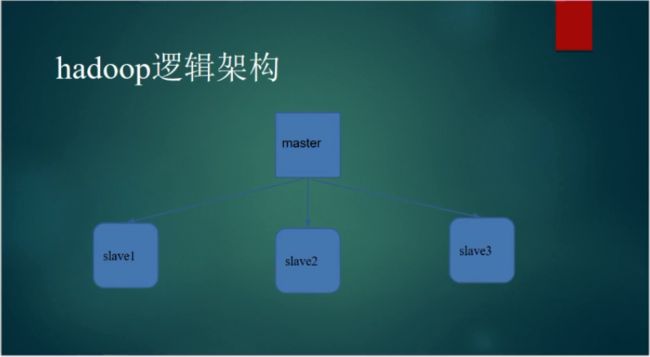
一、安装Hadoop
(先在本机上安装Hadoop ,解压的即是安装。)
1、安装VirtualBox
2、安装完成后新建虚拟机名称为master
3、设定VirtualBox虚拟网卡的IP地址:
先设置虚拟机中的网络设置
在虚拟机中选用host-only网络模式
然后进入Linux界面进行IP地址配置:
vi /etc/sysconfig/network-sripts/ifcfg-enp0s3
TYPE=Ethernet
IPADDR=192.168.56.100
NETMASK=255.255.255.0
修改Linux主机名:(主机名千万不能有下划线!)
hostnamectl set-hostname master
4、重启网络(使网卡生效)service network restart
互相ping,看是否测试成功,若不成功,注意防火墙的影响。关闭windows或虚拟机的防火墙。systemctl stop firewalld system disable firewalld
使用XShell登陆
检查ssh服务状态
systemctl status sshd (service sshd status)
5、验证使用XShell是否能登陆成功。
将hadoop和jdk上传到虚拟机(用xftp5上传)
在Linux中安装
JDK rpm -ivh ./xxxxx.jdk
6、验证
rpm -qa | grep jdk
7、在命令行中敲java命令,确认jdk已经安装完成
(jdk默认安装在/usr/java目录下)
8、在Linux中安装hadoop
cd /usr/local(到存放Hadoop目录下准备解压)
tar –xvf ./hadoop-2.7.2.tar.gz
9、把目录修改为:
hadoop mv hadoop-2.7.2 hadoop(方便今后操作)
10、修改
hadoop-env.sh(配置Hadoop运行环境)
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
11、修改export JAVA_HOME (为了Java能够找到执行的命令)
export JAVA_HOME=/usr/java/default
12、把/usr/hadoop/bin和/usr/hadoop/sbin设到PATH中
vi /etc/profile
追加
export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin(为了能让系统找到并使用Hadoop命令)
source etc/profile(让配置文件生效)
测试hadoop命令是否可以直接执行,任意目录下敲hadoop
关闭master虚拟机并复制3份master虚拟机
分别修改3份虚拟机的ip和hostname,确认互相能够ping通,用ssh登陆,同时修改所有虚拟机的/etc/hosts,确认使用名字可以ping通
二、Hadoop测试
1、下面搭建Hadoop集群
首先配置core-site文件
cd /usr/local/hadoop/etc/hadoop
vim core-site.xml(配置所有datanode的管理者信息)
fs.defaultFS
hdfs://master:9000
(然后将上面的配置文件分发到各个datanode,目的是让各个datanode知道自己 的管理者是谁)
2、启动集群
1)在master上启动
hadoop-daemon.sh start namenode
2)在slave上启动
hadoop-daemon.sh start datanode
3)用jps指令观察执行结果
4)用hdfs dfsadmin -report观察集群配置情况
5)通过http://192.168.56.100:50070到web界面观察集群运行情况
6)用hadoop-daemon.sh stop ...手工关闭集群
3、对集群进行集中管理(避免每次对每个机器进行手动启动)
1)修改master上文件
vi /etc/hadoop/slaves
slave1
slave2
slave3
2)使用start-dfs.sh启动集群,并观察结果
3)使用stop-dfs.sh停止集群
4)配置免密SSH远程登陆(此时需要密码才能登陆)
ssh slave1
输入密码
exit
修改每次远程登录的密码问题
cd
ls -la
cd .ssh
ssh-keygen -t rsa (四个回车)
会用rsa算法生成私钥id_rsa和公钥id_rsa.pub
(id_rsa 标志root的私钥)
ssh-copy-id slave1/2/3
(把公钥拷贝到slave上面,以后远程登录slave就用公钥去解开root的私钥)
再次ssh slave1
(此时已经不再需要密码)
5)重新使用start-dfs.sh启动集群
5、修改windows机上C:\Windows\System32\drivers\etc\hosts文件,可以通过名字访问集群web界面
192.168.56.100 master
6、使用hdfs dfs 或者hadoop fs命令对文件进行增删改查的操作
1)hadoop fs -ls / 查看Hadoop根目录下的文件
2)hadoop fs -put file / 把Linux本地的file文件丢到Hadoop的根目录下
3)hadoop fs -mkdir /dirname 在Hadoop下新建dirname目录
4)hadoop fs -text /filename 查看filename文件内容
5)hadoop fs -rm /filename 删除filename文件
7、通过网页观察文件情况
8、将hdfs-site.xml的replication值设为2,通过网页观察分块情况
vi hdfs-site.xml
dfs.replication
2
9、设定dfs.namenode.heartbeat.recheck-interval为10000,然后停掉其中一台slave,观察自动复制情况
(服务器会默认5分钟自动检测机器的运行情况,如果一台机器done掉,系统会让其他机器去替代那个done掉的机器,把那个机器的文件备份到其他的机器上,这里把检测的时间设置为10秒。)
10、启动停掉的slave节点,通过网页观察datanode的动态添加
11、添加新的节点,体会hadoop的横向扩展
1)启动slave4,关闭防火墙,修改hostname
2)修改etc/hosts,加入对自己以及其他机器的解析,重启网络
3)在master中设定对于slave4的解析
4)启动slave4的datanode,通过网页进行观察
5)hdfs dfsadmin –shutdownDatanode slave4:50020
(通过java程序访问hdfs,就把HDFS集群当成一个大的系统磁盘就行了!)
12、使用FileSystem类解决问题
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.56.100:9000");
FileSystem fileSystem = FileSystem.get(conf);
boolean b = fileSystem.exists(new Path("/hello"));
System.out.println(b);
boolean success = fileSystem.mkdirs(new Path("/mashibing"));
System.out.println(success);
success = fileSystem.delete(new Path("/mashibing"), true);
System.out.println(success);
FSDataOutputStream out = fileSystem.create(new Path("/test.data"), true);
FileInputStream fis = new FileInputStream("c:/test/core-site.xml");
IOUtils.copyBytes(fis, out, 4096, true);
FileStatus[] statuses = fileSystem.listStatus(new Path("/"));
//System.out.println(statuses.length);
for(FileStatus status : statuses) {
System.out.println(status.getPath());
System.out.println(status.getPermission());
System.out.println(status.getReplication());
}