数据工场
基本概念 https://help.aliyun.com/document_detail/30257.html?spm=a2c4g.11186623.6.541.oiqbz7
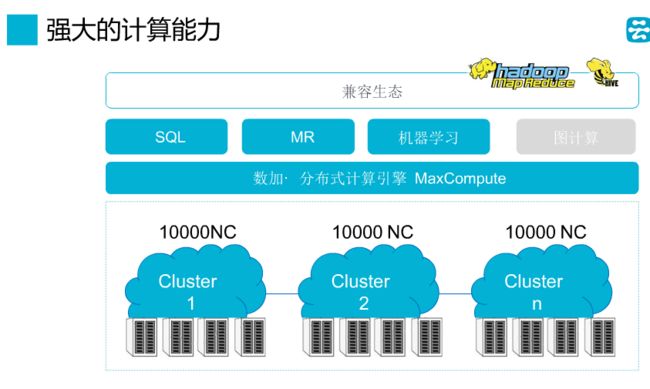
MaxCompute 支持 SQL、MapReduce、Graph 等计算类型及 MPI 迭代类算法。
MaxCompute批量、历史数据通道是Tunnel,实时、增量数据通道,可以用DataHub,DataHub还支持多种数据传输插件:Logstash、Flume、Fluentd、Sqoop,支持日志服务Log Service。
MaxCompute 支持多种计算模型:SQL、UDF、MapReduce、Graph
MaxCompute SDK:
https://help.aliyun.com/document_detail/34614.html?spm=a2c4g.11186623.2.18.uBsiqW
MapReduce:
https://help.aliyun.com/document_detail/27875.html?spm=a2c4g.11186623.2.13.uBsiqW
UDF:
https://help.aliyun.com/document_detail/27866.html?spm=a2c4g.11186623.2.22.cmHUQg
MaxCompute Graph 是一套面向迭代的图计算处理框架。图计算作业使用图进行建模,图由点(Vertex)和边(Edge)组成,点和边包含权值(Value)。https://help.aliyun.com/document_detail/27901.html?spm=a2c4g.11186623.6.669.MLWaOz
DataHub
https://help.aliyun.com/document_detail/47439.html?spm=a2c4g.11174283.3.1.vKmf5b
阿里云流数据处理平台DataHub是流式数据(Streaming Data)的处理平台,提供对流式数据的发布(Publish),订阅(Subscribe)和分发功能,让您可以轻松构建基于流式数据的分析和应用。DataHub服务可以对各种移动设备,应用软件,网站服务,传感器等产生的大量流式数据进行持续不断的采集,存储和处理。您可以编写应用程序或者使用流计算引擎来处理写入到DataHub的流式数据,比如:实时web访问日志、应用日志、各种事件等,并产出各种实时的数据处理结果,比如:实时图表、报警信息、实时统计等。
DataHub服务基于阿里云自研的飞天平台,具有高可用,低延迟,高可扩展,高吞吐的特点。DataHub与阿里云流计算引擎StreamCompute无缝连接,您可以轻松使用SQL进行流数据分析。
DataHub服务也提供分发流式数据到各种云产品的功能,目前支持分发到MaxCompute(原ODPS),OSS等。

StreamCompute是阿里云提供的流计算引擎,提供使用类SQL的语言来进行流式计算。DataHub 和StreamCompute无缝结合,可以作为StreamCompute的数据源和输出源。

DataWorks
项目状态:项目一般分为正常、初始化中、初始化失败、删除中、删除五种状态。
修改服务

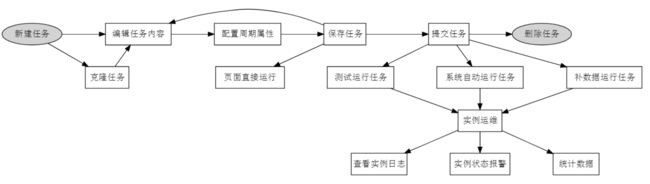
通常情况下,通过DataWorks的项目空间实现数据开发和运维,包含以下操作:
步骤1:建表并上传数据
(创建;本地上传·最大10M;tunnel;dataX)
步骤2:创建工作流
(支持的任务类型:ODPS_SQL、ODPS_MR、数据同步、OPEN_MR、机器学习、SHELL、虚节点)
步骤3:创建同步任务
步骤4:设置周期和依赖

步骤5:运维及日志排错
如何确认实例运行的定时时间和相互依赖关系符合预期呢?提供三种触发方式:测试运行、补数据运行、周期运行。
测试运行:手动触发方式。如果您仅需确认单个任务的定时情况和运行,建议使用测试运行。
补数据运行:手动触发方式。如果您需要确认多个任务的定时情况和相互依赖关系,或者需要从某个根任务开始重新执行数据分析计算,可以考虑使用此方式。
周期运行:系统自动触发方式。提交成功的任务,调度系统在第二天0点起会自动生成当天不同时间点的运行实例,并在定时时间达到时检查各实例的上游实例是否运行成功,如果定时时间已到并且上游实例全部运行成功,则当前实例会自动触发运行,无需人工干预。
调度资源
资源名称:调度资源组名称,由英文字母、下划线、数字组成,不超过 60 个字符,创建后不支持修改。
DataWorks(数据工场)的调度资源分为以下两种模式:
默认调度资源、自定义调度资源。
自定义调度资源指用户自购 ECS,配置成可以执行分发任务的调度服务器。组织管理员(主账号)可以新建自定义调度资源,调度资源包括若干台物理机或 ECS,用于执行数据同步任务、SHELL 任务、ODPS_SQL、OPEN_MR 任务。
数据集成,是阿里集团对外提供的稳定高效、弹性伸缩的数据同步平台。致力于提供复杂网络环境下、丰富的异构数据源之间数据 高速稳定的数据移动及同步能力。

数据集成提供丰富的数据源支持,如下所示:
文本存储(FTP / SFTP / OSS / 多媒体文件等)。
数据库(RDS / DRDS / MySQL / PostgreSQL 等)。
NoSQL(Memcache / Redis / MongoDB / HBase 等)。
大数据(MaxCompute / AnalyticDB / HDFS 等)。
MPP 数据库(HybridDB for MySQL 等)。
同步有两种模式:向导模式、脚本模式;
脚本模式用json脚本,向导模式生成的代码可以转换为脚本模式,但不能反向。代码编写前要完成数据源的配置和目标表的创建。
同步·网络类型,三种:
经典网络:统一部署在阿里云的公共基础网络内,网络的规划和管理由阿里云负责,更适合对网络易用性要求比较高的客户。
专有网络(VPC):基于阿里云构建出一个隔离的网络环境。可以完全掌控自己的虚拟网络,包括选择自有的 IP 地址范围,划分网段,以及配置路由表和网关。
本地IDC网络(规划中):您自身构建机房的网络环境,与阿里云网络是隔离不可用的。
配置同步,不懂:https://help.aliyun.com/document_detail/49808.html?spm=a2c4g.11186623.6.588.VxW0nN
……【整个数据集成基本处于懵逼状态,毕竟没有实践经验离应用场景太远,还得沉下心好好看看】
数据开发
数据开发阶段,DataWorks提供4种对象供使用:任务、脚本、资源、函数。
一个任务的开发和使用流程:

各种权限点:https://help.aliyun.com/document_detail/30277.html?spm=a2c4g.11186623.6.621.TfXC9G
DataWorks(数据工场,原大数据开发套件)提供了 2种 任务类型 7种 节点类型:
任务类型:节点任务和工作流任务。
节点类型:虚节点类型,ODPS_SQL 节点类型,SHELL 节点类型,数据同步节点类型,机器学习节点类型,ODPS_MR 节点类型和 OPEN_MR 节点类型。
调度参数配置:
https://help.aliyun.com/document_detail/30281.html?spm=a2c4g.11186623.2.14.PWxXPY
发布管理:
https://help.aliyun.com/document_detail/30282.html?spm=a2c4g.11186623.6.652.Wpndsr
DataWorks三种数据:表、函数、资源。
题目:
MaxCompute只支持结构化数据的存储和处理。 × 支持非结构,如图片
MaxCompute对表的列数和列的内容没有限制。 ×最多1024列,内容大小受限于数据类型。
Select的where子句可以指定查询范围,这样可以避免全表扫描。 ×只有分区表能避免全表扫描。
下列产品中,能满足用户使用SQL进行交互式查询需求的是
A:MaxCompute B:AnalyticDB C:RDS D:TS
BC;MaxCompute是批量计算模型;TS不支持SQL访问。
MaxCompute使用DDL建表一开始没有分区字段,在使用时可以动态增加或更改分区。×不能直接增加/更改分区键,可以增加分区,不能增加分区字段。
关于阿里云流计算错误的是()
A、是运行在阿里云平台上的流式大数据分析平台
B、提供给用户在云上进行流式数据实时化分析工具
C、可以使用阿里云StreamSQL进行流式数据分析
D、流计算的数据存储是基于盘古分布式文件系统
D错,阿里云流计算不存储数据,计算结果直接推送给下游。
流计算特点描述,正确的是()
A、实时且流式的
B、数据是无界的
C、事件触发
D、用户触发
ABC
阿里云流计算目前可以支持SQL和MapReduce。×不支持MapReduce
流计算对不同的项目进行了严格的项目权限区分,不同用户/项目之间是无法进行访问、操作。✔️
Oracle存储过程可以使用阿里云流计算替换。×
现有Spark作业可以无缝迁移到流计算。×,无法无缝迁移。
DataWorks中工作流任务如果配置为周期性调度,所支持的周期包括哪些?
A、月调度 B、周调度 C、天调度 D、季度调度 E、小时调度 F、1分钟调度
ABCE,没有季度调度,最小单位5分钟
通过安全授权,用户可以访问的项目空间中的对象有()?
A、表 B、项目 C、函数 D、资源
ACD 表、资源、函数、实例
MaxCompute支持外部表,外部表中的数据可以存储在OSS或TS中?✔️
MaxCompute支持的分区类型包括()
A、STRING B、TINYINT C、BIGINT D、VARCHAR
还有smallint、bigint
DataWorks中任务包括哪些类型?
A、节点任务 B、工作流任务 C、内部节点 D、外部节点
ABC
MaxCompute Graph支持一下图编辑操作:ABC (没有节点间通信)
Graph最早是由Google提出的分布式数据处理模型。× MapReduce才是
Graph擅长完成学术论文、专利文献的引用分析和统计。× 是MapReduce擅长的
Graph节点的Halted标志的含义是节点是否参与迭代计算。✔️
对AnalyticDB正确的是?()
A、分析型数据库 B、可用于流式计算 C、支持SQL查询 D、基本计算单元是ECU
ACD
AnalyticDB是阿里云提供的数据仓库,可用于完成PB级别数据的批量计算。×擅长的是交互式查询
每个DataWorks任务使用0个或0个以上的数据表(数据集)作为输入,生成一个或多个数据表(数据集)作为输出。 ✔️
MaxCompute中日期型和布尔型不允许参与算术运算。✔️String也可以参与算术运算
MaxCompute中,A和B都是bigint类型,A/B返回结果为___。 Double
MaxCompute的Table的名字,错误的是:
A、建表时可使用中文作为表名
B、表名中不能有特殊字符
C、表名只能用a-z,A-Z及数字和下划线_,且以字母开头
D、长度不超过128字节
A
MaxCompute SQL中位运算只允许bigint类型。✔️
MaxCompute SQL中常量定义100BD表示的含义是___。数值为100的decimal
MaxCompute SQL中隐式类型转换规则是有发生作用域的,在某些作用域中,只有一部分规则可以生效。✔️
MaxCompute中一个multi-insert中:对于未分区表,该表不能出现多次。✔️
MaxCompute中如果目标表有多级分区,在运行insert语句时允许指定部分分区为静态,但静态分区必须是高级分区。✔️





任务调度时间为2017-10-2701:00:00,那么bdp.system.cyctim的结果为20171027010000
A. 是
B. 否
答案: A
解析: ${bdp.system.cyctime}=$[yyyymmddhh24miss]可以任意分解组合,即某一时刻进行调度就显示某个时间的值,精确到秒
DataX是阿里巴巴集团内广泛使用的离线数据同步工具/平台,实现包括MySQL、Oracle、HDFS、Hive、Table Store、MaxCompute等各种异构数据源之间高效的数据同步功能,支持数据续传
A. 是
B. 否
答案: B
解析:Datax不支持断点续传,一般基于日志才支持数据中断才进行续传。而Datax是reader和writer的配置整合到一起,故错了
Mapreduce支持对视图处理
A. 是
B. 否
答案: B
Tunnel支持那种SDK
A. Java
B. C++
C. Python
D. C#
答案: A
用户A有访问users表的权限,当管理员把Users表删除后,再新建了一张users表,此时users表与原来的表结构不一样,用户A还能访问users吗?
A. 能
B. 不能
答案A
解析:权限只识别对象,并不识别对象的具体内容。
阿里云大数据计算服务(MaxCompute,原 ODPS)中的 MapReduce 是一种编程模型,用于大规模数据集的并行运算,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。其中,两个主要阶段 Map和 Reduce 相互配合,可以完成对海量数据的处理。关于这两个阶段的关系,说法正确的有________。(正确答案的数量:3 个)
a) 一个 map 的输出结果可能会被分配到多个 reduce 上去
b) 一个 reduce 的输入数据可能来自于多个 map 的输出
c) 一个 MR 处理可以不包括任何 map
d) 一个 MR 处理可以不包含任何 reduce
ABC
select ID,name from Table_A where ID not in (select ID from Table_B)
这句是最经典的not in查询了。改为表连接代码如下:
select Table_A.ID,Table_A.name from Table_A left join Table_B on Table_A.ID=Table_B.ID and Table_B.ID is null
select * from a where aid not in (select id from b)
改成如下语句:
select a.* from a left outer join (select distinct id from b) bb on a.id=bb.id where bb.id is null;
Q:MaxCompute 项目中的 Owner 能否更换为子账号?
A:项目的 Owner 不可以更换,谁创建的 Project,谁就是 Owner。您可以将 Admin 的角色赋予子账号。
Q:与 Owner 相比,Admin 角色有哪些限制?
A: 与 Owner 相比,Admin 角色不能进行如下操作:
Admin 角色不能将 admin 权限指派给用户。
不能设定项目空间的安全配置。
不能修改项目空间的鉴权模型。
Admin 角色所对应的权限不能被修改。
Q:在 MaxCompute SQL 执行过程中,报错为Table xx has n columns, but query has m columns。
A:MaxCompute SQL 使用 INSERT INTO/OVERWRITE TABLE XXX SELECT 插入数据时,需要保证 SELECT 查询出来的字段和插入的表的字段,包括顺序、字段类型都能匹配,当然总的字段数量上也要能对的上。
目前 MaxCompute 不支持指定插入表中某几个字段,其他字段为 NULL 或者其他默认值的情况,您可以在 SELECT 的时候设置成 NULL,例如:SELECT ‘a’,NULL FROM XX。
Q:用insert into…values...语句插入表记录报错,请问如何向 MaxCompute 表中插入记录?
A:向 MaxCompute 表中插入记录的操作步骤如下:
创建一个表, 例如 dual 表。语句如下:
createtabledual(cntbigint);
insertintotabledualselectcount(*) as cnt from dual;
执行完上述语句便生成了一张有 1 条记录的 dual 表。
执行下述语句,即可向 MaxCompute 表中插入记录。
insert into table xxxx select 1,2,3 from dual;
tunnel:
Q:是否支持 ascii 字符的分隔符?
A:命令行方式不支持,配置文件可以用十六进制表示。如 \u000A,表示回车。
Q:文件大小是否有限制?
A:文件大小没有限制,但一次 upload 无法超过 24 小时,可以根据实际上传速度和时间来估算能够上传的数据量。
Q:记录大小是否有限制?
A:记录大小不能超过 200M。
Q:是否要使用压缩?
A:默认会使用压缩,如果带宽允许的情况下,可以关掉压缩。
Q:同一个表或 partition 是否可以并行上传?
A:可以。
Q:是否支持不同字符编码?
A:支持不同的编码格式参数,带 bom 标识文件不需要指定编码。
Q:导入后的脏数据怎么处理?
A:导入结束后,如果有脏数据可以通过 tunnel show bad [sessionid] 查看脏数据。
Q:上传下载的文件路径是否可以有空格?
A:可以有空格,参数需要用双引号括起来。
Q:为什么会出现乱码?
A:可能是上传文件的字符编码和工具指定的编码不符。
Q:导入数据最后一列为什么多出\r符号?
A:windows 的换行符是\r\n,macosx 和 linux 的换行符是\n,tunnel 命令使用系统换行符作为默认列分隔符,所以从 macosx 或 linux 上传 windows 编辑保存的文件会把\r作为数据内容导进去。
Q:Tunnel 下载/上传速度正常速度范围是多少?
A:Tunnel 下载上传,受网络因素影响较大,正常网络情况下速度范围在 1MB/s-20MB/s 区间内。
Q:Tunnel 域名是什么?
A:不同 region 对应不同的域名,详情请参见 访问域名和数据中心。
Q:无法上传/下载怎么办?
A:找到配置中配置的 tunnel 域名,通过 curl -i 域名例如 curl -i http://dt.odps.aliyun.com 测试网络是否连通,若无法连通请检查机器网络或更换为正确的域名。
Q:上传/下载速度缓慢怎么办?
A:您可以从以下几方面进行检查:
检查机器网络状态,ping tunnel_endpoint 域名延迟是否异常。
检查流量状态, 通过 ifstat 等命令检查客户端机器流量是否满载。
若为 ECS 机器,请检查是否使用的公网域名而不是跨域或 ECS 域名,若使用公网域名,请检查 ECS 的带宽使用情况是否打满或更换域名。
Q:报 Java heap space FAILED: error occurred while running tunnel command 错误怎么办?
A:若出现上述错误,您可以从以下几方面进行解决:
若是上传数据,应当是单行数据太大导致,与整体文件的大小无关。先确认是不是分隔符没写对,导致所有数据都搞到一行 record 里去了。
若是分隔符没写错,您文件中的单行数据的确很大,那么就是 console 程序的内存不够用了,需要调整 console 进程启动的参数。
具体方法:打开 odpscmd 脚本,适当增加 java 进程启动选项中的内存值 。如 java -Xms64m -Xmx512m -classpath "${clt_dir}/lib/*:${clt_dir}/conf/"com.aliyun.openservices.odps.console.ODPSConsole "$@" 中将 -Xms64m -Xmx512m 的值增大即可。
若是下载数据,可能是数据量太大,console 程序的内存不够用了。打开 odpscmd 脚本,适当增加 java 进程启动选项中的内存值 。如 java -Xms64m -Xmx512m -classpath"${clt_dir}/lib/*:${clt_dir}/conf/"com.aliyun.openservices.odps.console.ODPSConsole "$@" 中将 `-Xms64m -Xmx512m`` 的值增大即可。
Q:Tunnel 需注意的分隔符问题有哪些?
A:Tunnel 需要注意的分隔符问题,如下所示:
列分隔符 fd 不能包含行分隔符 rd。
行分隔符 rd。
默认值: \r\n (windows) 和 \n(linux)。
上传开始的时候会打印提示信息,告知本次上传所使用的行分隔符(0.21.0 版本及以后)供用户查看和确认。
列分隔符 fd。
默认值:, (逗号)。
Q:DataHub 表和 MaxCompute 中创建的表,是否是一个表?
A:MaxCompute 的表分离线表和在线表两种,datahub 是在线表。只有在线表才能处理 datahub,也才能作为流式计算的输入源,而在线表的数据,会几分钟起一个定时任务归档到离线表里,所以在线表的数据和离线表的数据是有几分钟的延迟的。
SQLTask 查询数据和 DownloadSession 在使用及功能上,有何不同?
A:SQLTask 是运行 SQL 并返回结果,返回条数有限制,默认是 1000 条。
DownloadSession 是下载某个存在的表里数据,结果条数没限制。
Q:MaxCompute 如何在客户端上查看一个任务的历史信息?
A:如果您想查看一个历史任务的运行详情,可以通过以下步骤进行操作:
找到想要查看任务的 instanceId。您可通过任务列表来查看最近的任务记录:

如果是 SQL 任务的话,可以直接看到 SQL 的内容。
如果要查看几天前的 instance,可以运行命令: show p from date1 to date2 number,eg:show p from 2015-5-20 to 2015-5-22 2000
找到任务后,可以看一下任务的信息,核对是否确实是这个任务:
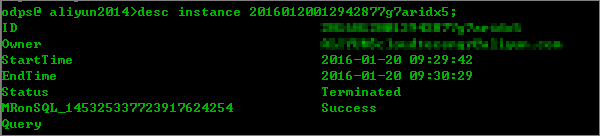
通过 wait 命令,获得任务的运行日志:
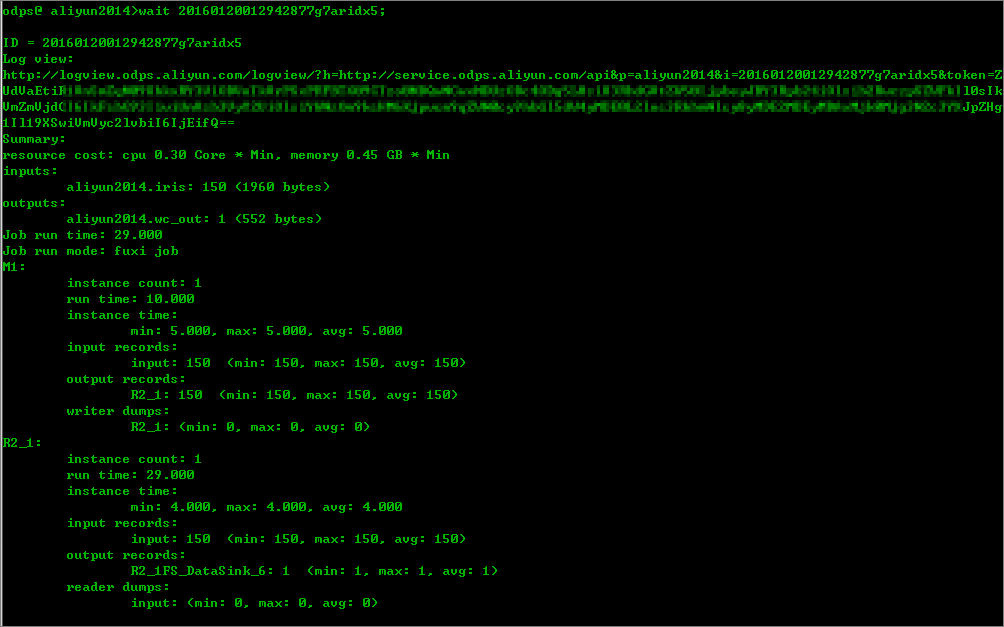
通过 logview,即可获得任务的详细日志。