《Python数据分析与挖掘实战》第四章案例代码总结与修改分析
第四章案例代码总结与修改分析
【有问题或错误,请私信我将及时改正;借鉴文章标明出处,谢谢】
每个案例代码全部为书中源代码,出现错误按照每个案例下面给出的代码错误,原因,及怎样修改进行修改即可解决每个案例错误
4-1
#拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = 'F:/大二下合集/Python数据分析与挖掘/catering_sale.xls' #销量数据路径
outputfile = 'F:/大二下合集/Python数据分析与挖掘/sales.xls' #输出数据路径
data = pd.read_excel(inputfile) #读入数据
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile) #输出结果,写入文件
代码错误:
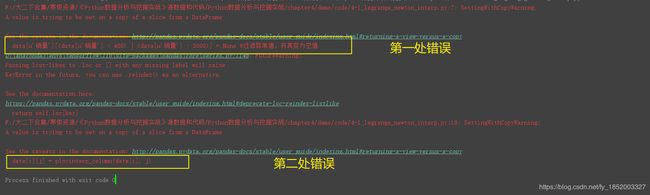
第一个错误原因:
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值
修改为:
row_indexs = (data[u'销量'] < 400) | (data[u'销量'] > 5000)
data.loc[row_indexs, u'销量'] = None # 过滤异常值,将其变为空值
第二个错误原因:(需要改两个地方代码)
第①处
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
修改为:
y = s.reindex(list(range(n - k, n)) + list(range(n + 1, n + 1 + k))) # 取数
第②处
data[i][j] = ployinterp_column(data[i], j)
修改为:
data[i, j] = ployinterp_column(data[i], j)
4-2
#-*- coding: utf-8 -*-
#数据规范化
import pandas as pd
import numpy as np
datafile = 'F:/大二下合集/Python数据分析与挖掘/normalization_data.xls' #参数初始化
data = pd.read_excel(datafile, header = None) #读取数据
(data - data.min())/(data.max() - data.min()) #最小-最大规范化
(data - data.mean())/data.std() #零-均值规范化
data/10**np.ceil(np.log10(data.abs().max())) #小数定标规范化
代码错误:
没有报错,但是在idea中运行没有结果
原因:
(data - data.min())/(data.max() - data.min()) #最小-最大规范化
(data - data.mean())/data.std() #零-均值规范化
data/10**np.ceil(np.log10(data.abs().max())) #小数定标规范化
修改为:
print((data - data.min()) / (data.max() - data.min())) #最小-最大规范化
print((data - data.mean()) / data.std()) #零-均值规范化
print(data / 10 ** np.ceil(np.log10(data.abs().max()))) #小数定标规范化
4-3
#-*- coding: utf-8 -*-
#数据规范化
import pandas as pd
datafile = 'F:/大二下合集/Python数据分析与挖掘/discretization_data.xls'
data = pd.read_excel(datafile)
data = data[u'肝气郁结证型系数'].copy()
k = 4
d1 = pd.cut(data, k, labels = range(k))
#等频率离散化
w = [1.0*i/k for i in range(k+1)]
w = data.describe(percentiles = w)[4:4+k+1]
w[0] = w[0]*(1-1e-10)
d2 = pd.cut(data, w, labels = range(k))
from sklearn.cluster import KMeans
kmodel = KMeans(n_clusters = k, n_jobs = 4)
kmodel.fit(data.reshape((len(data), 1)))
c = pd.DataFrame(kmodel.cluster_centers_).sort(0)
w = pd.rolling_mean(c, 2).iloc[1:]
w = [0] + list(w[0]) + [data.max()]
d3 = pd.cut(data, w, labels = range(k))
def cluster_plot(d, k):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).show()
cluster_plot(d2, k).show()
cluster_plot(d3, k).show()
代码错误1:

错误原因:(需要改两个地方代码)
第①个地方
kmodel.fit(data.reshape((len(data), 1)))
修改为:
kmodel.fit(data.values.reshape((len(data),1)))
第②个地方
c = pd.DataFrame(kmodel.cluster_centers_).sort(0)
修改为:
c=pd.DataFrame(kmodel.cluster_centers_).sort_values(0)
解决完第一个错误再次运行发现错误2:

原因:
w = pd.rolling_mean(c, 2).iloc[1:]
修改为:
w=c.rolling(2).mean().iloc[1:]
4-4
#线损率属性构造
import pandas as pd
inputfile= 'F:/大二下合集/Python数据分析与挖掘/electricity_data.xls' #供入供出电量数据
outputfile = 'F:/大二下合集/Python数据分析与挖掘/electricity_data.xls' #属性构造后数据文件
data = pd.read_excel(inputfile) #读入数据
data[u'线损率'] = (data[u'供入电量'] - data[u'供出电量'])/data[u'供入电量']
data.to_excel(outputfile, index = False) #保存结果
这个案例代码没问题
4-5
#-*- coding: utf-8 -*-
#利用小波分析进行特征分析
#参数初始化
inputfile= 'F:/大二下合集/Python数据分析与挖掘/leleccum.mat' #提取自Matlab的信号文件
from scipy.io import loadmat #mat是MATLAB专用格式,需要用loadmat读取它
mat = loadmat(inputfile)
signal = mat['leleccum'][0]
import pywt #导入PyWavelets
coeffs = pywt.wavedec(signal, 'bior3.7', level = 5)
#返回结果为level+1个数字,第一个数组为逼近系数数组,后面的依次是细节系数数组
代码整体没有错误,但是运行没有结果需要在代码最后加一行
print(coeffs)
4-6
import pandas as pd
inputfile = 'F:/大二下合集/Python数据分析与挖掘/principal_component.xls'
outputfile = 'F:/大二下合集/Python数据分析与挖掘/1.xls'
data = pd.read_excel(inputfile, header = None)
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data)
pca.components_
pca.explained_variance_ratio_
print("-----------4-6.2-----------------")
pca=PCA(3)
pca.fit(data)
low_d=pca.transform(data)
pd.DataFrame(low_d).to_excel(outputfile)
low_d
pca.inverse_transform(low_d)
代码错误:
没有报错,但是在idea中运行没有结果,而且最后两行标红
①将:
pca.components_
pca.explained_variance_ratio_
修改为:(即添加print)
print(pca.components_)
print(pca.explained_variance_ratio_)
②将:
low_d
pca.inverse_transform(low_d)
修改为:(即添加print)
print(low_d)
print(pca.inverse_transform(low_d))
4-7(即预处理函数的两个实例)
import numpy as np
import pandas as pd
print("-----------------unique---------------------")
D=pd.Series([1,1,2,3,5])
D.unique()
np.unique(D)
print("---------------isnull/notnull---------------------")
from sklearn.decomposition import PCA
D=np.random.rand(10,4)
pca=PCA()
pca.fit(D)
pca.components_ #返回模型的各个特征向量
pca.explained_variance_ratio_
代码错误:
没有报错,但是在idea中运行没有结果,而且最后两行标红
①将:
D.unique()
np.unique(D)
修改为:(即添加print)
print(D.unique())
print(np.unique(D))
②将:
pca.fit(D)
pca.components_ #返回模型的各个特征向量
pca.explained_variance_ratio_
修改为:(即添加print)
print(pca.fit(D))
print(pca.components_) #返回模型的各个特征向量
print(pca.explained_variance_ratio_)
【有问题或错误,请私信我将及时改正;借鉴文章标明出处,谢谢】