【算法实战篇】时序多分类赛题-2020数字中国创新大赛-智慧海洋建设top5方案(含源码)...
 Hi,大家好!这里是AILIGHT!AI light the world!这次给大家带来的是2020数字中国创新大赛-数字政府赛道-智能算法赛:智慧海洋建设的算法赛复赛赛道B top5的方案以及代码开源。比赛传送门:https://tianchi.aliyun.com/competition/entrance/231768/introduction 这是我们队伍参加的为数不多的数据挖掘类的算法竞赛。经过两个多月的时间,我们队伍最终在算法赛道B阶段取得top5的成绩。说一下参赛体验:都是神仙打架,太难了!接下来进入正题吧!
Hi,大家好!这里是AILIGHT!AI light the world!这次给大家带来的是2020数字中国创新大赛-数字政府赛道-智能算法赛:智慧海洋建设的算法赛复赛赛道B top5的方案以及代码开源。比赛传送门:https://tianchi.aliyun.com/competition/entrance/231768/introduction 这是我们队伍参加的为数不多的数据挖掘类的算法竞赛。经过两个多月的时间,我们队伍最终在算法赛道B阶段取得top5的成绩。说一下参赛体验:都是神仙打架,太难了!接下来进入正题吧!
本方案采用特征工程 + NLP的相关技术,下面为大家进行详细介绍。
任务介绍
赛题基于位置数据对海上目标进行智能识别和作业行为分析,要求选手通过分析渔船北斗设备位置数据,得出该船的生产作业行为,具体判断出是拖网作业、围网作业还是流刺网作业。数据包含脱敏后的渔船ID、经纬度坐标、上报时间、速度、航向信息,由于真实场景下海上环境复杂,经常出现信号丢失,设备故障等原因导致的上报坐标错误、上报数据丢失、甚至有些设备疯狂上报等。每一个渔船ID对应多条上报数据。数据示例如图: 分析完整个赛题其实是一个时序多分类的任务。
分析完整个赛题其实是一个时序多分类的任务。
评价标准:以3种类别的各自F1值取平均做为评价指标

数据分析&特征分析
主要从以下4个方面去进行了数据分析和特征的分析
2-1. 基本信息
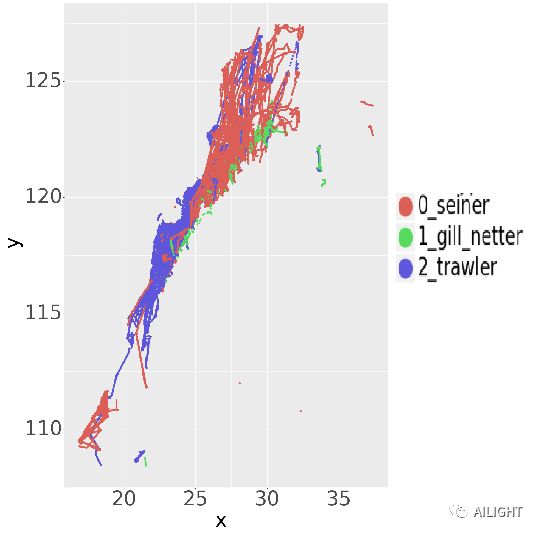 经纬度/x-y的分布
经纬度/x-y的分布
不同渔船的作业方式的区域有很大的区分度;
区域的重叠部分容易混淆,需要更多的信息进行判断;
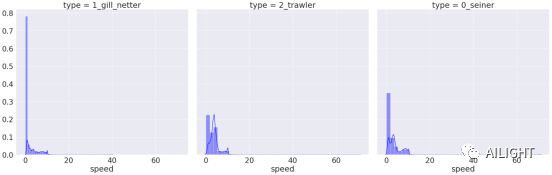 速度/speed的分布
速度/speed的分布
gill netter(刺网)作业方式大部分都在速度0或接近0的情况下作业;
速度的稳定性 trawler(拖网) > seiner(围网) > gill netter(刺网);
 方向/direction的分布
方向/direction的分布
三种作业方式的方向/direction在方向特别小的情况有一定差异;
我们对基础特征进行max,min...等进行统计得到一些基础特征
def group_feature(df, key, target, aggs,flag):
agg_dict = {}
for ag in aggs:
agg_dict['{}_{}_{}'.format(target,ag,flag)] = ag
print(agg_dict)
t = df.groupby(key)[target].agg(agg_dict).reset_index()
return t
t = group_feature(df, 'ship','x',['max','min','mean','median','std','skew'],flag)
t = group_feature(df, 'ship','speed',['max','mean','median','std','skew'],flag)
t = group_feature(df, 'ship','direction',['max','median','mean','std','skew'],flag)
t = group_feature(df, 'ship','y',['max','min','mean','median','std','skew'],flag)
2-2. 细致信息
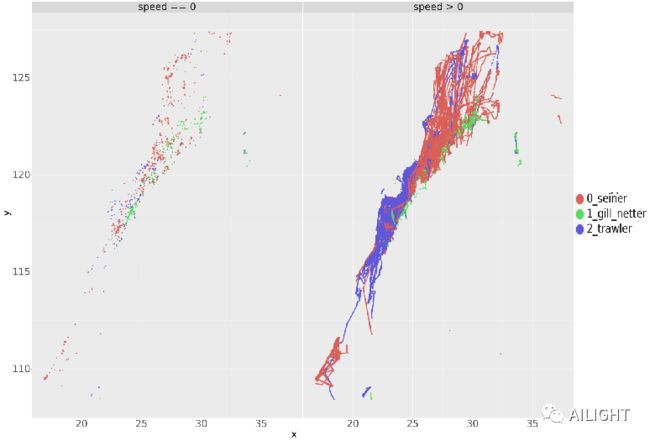 speed > 0 & speed == 0 经纬度/x-y 分布
speed > 0 & speed == 0 经纬度/x-y 分布
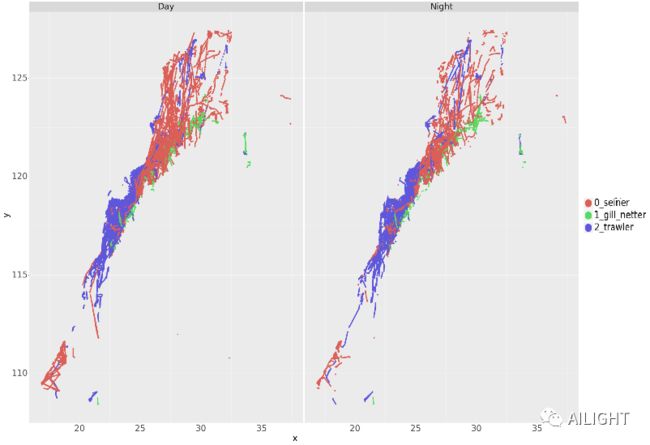 Day&Night 经纬度/x-y 分布
Day&Night 经纬度/x-y 分布
同一种作业方式在不同速度的位置区域(经纬度)也有着一定的差异
同一种作业方式在Day&Night上速度上有着一定的差异
同一种作业方式在Day&Night上位置区域(经纬度)有着一定的差异
data_1 = data[data['speed']==0]
data_2 = data[data['speed']!=0]
data_label = extract_feature(data_1, data_label,"0")
data_label = extract_feature(data_2, data_label,"1")
df['day_nig'] = 0
df.loc[(df['hour'] > 5) & (df['hour'] < 20),'day_nig'] = 1
data_1 = data[data['day_nig'] == 0]
data_2 = data[data['day_nig'] == 1]
data_label = extract_feature(data_1, data_label,"on_night")
data_label = extract_feature(data_2, data_label,"on_day")
2-3. 动态信息
每个渔船id的速度、经纬度看做是一个序列信息
利用速度、经纬度的分位数统计量,将浮点特征分桶转成一个类型特征
使用不同的ngram提取TF-IDF 特征(ngram=1, 2, 3)
对不同ngram提取的特征t-SNE 降维到二维,进行可视化
最终,利用NLP的TF-IDF提取关键高维的ngram信息,有效获取速度和经纬度动态变化的信息
#分桶
def cut_bins(raw_data, col_name=None, q=49):
features, bins = pd.qcut(raw_data[col_name], q=q, retbins=True, duplicates="drop")
labels = list(range(len(bins) - 1))
features, bins = pd.qcut(raw_data[col_name], labels=labels, q=q, retbins=True, duplicates="drop")
return features, bins, labels
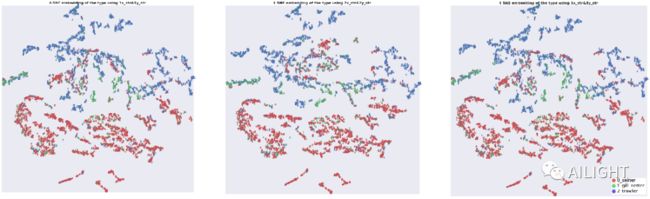 经纬度/x-y ngram=1, ngram=2, ngram=3降维之后结果(从左到右)
经纬度/x-y ngram=1, ngram=2, ngram=3降维之后结果(从左到右)
# 讲融合后的taglist当作一句话进行文本处理
self.data['title_feature'] = self.data[self.to_list].apply(lambda x: x.split('|'))
self.data['title_feature'] = self.data['title_feature'].apply(lambda line: [w for w in line if w not in stop_words])
self.data['title_feature'] = self.data['title_feature'].apply(lambda x: ' '.join(x))
print('start NMF')
# 使用tfidf对元素进行处理
tfidf_vectorizer = TfidfVectorizer(ngram_range=(tf_n,tf_n))
tfidf = tfidf_vectorizer.fit_transform(self.data['title_feature'].values)
#使用nmf算法,提取文本的主题分布
text_nmf = NMF(n_components=self.nmf_n).fit_transform(tfidf)
2-4. 基于word2vec的表征
使用深度学习的word2vec的CBOW算法无监督训练,获取经纬度(x-y)和速度(speed)的类型向量
每个渔船id的经纬度和速度向量取平均作为特征,然后使用t-SNE 降维到二维,进行可视化
最终,利用NLP的word2vec提取区域的交互动态信息,有效获取速度和经纬度信息
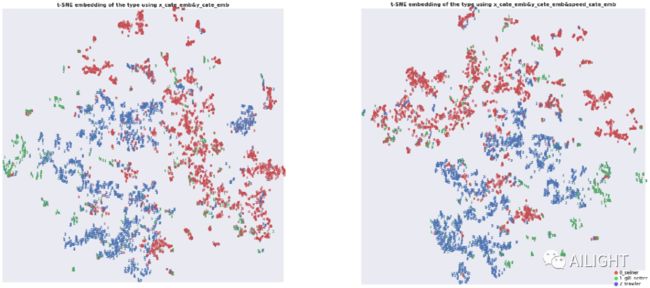 word2vec 降维之后可视化(从左到右)·经纬度· ·经纬度+速度·
word2vec 降维之后可视化(从左到右)·经纬度· ·经纬度+速度·
from gensim.models import Word2Vec
import gc
def emb(df, f1, f2):
emb_size = 23
print('====================================== {} {} ======================================'.format(f1, f2))
tmp = df.groupby(f1, as_index=False)[f2].agg({'{}_{}_list'.format(f1, f2): list})
sentences = tmp['{}_{}_list'.format(f1, f2)].values.tolist()
del tmp['{}_{}_list'.format(f1, f2)]
for i in range(len(sentences)):
sentences[i] = [str(x) for x in sentences[i]]
model = Word2Vec(sentences, size=emb_size, window=5, min_count=3, sg=0, hs=1, seed=2222)
emb_matrix = []
for seq in sentences:
vec = []
for w in seq:
if w in model:
vec.append(model[w])
if len(vec) > 0:
emb_matrix.append(np.mean(vec, axis=0))
else:
emb_matrix.append([0] * emb_size)
emb_matrix = np.array(emb_matrix)
for i in range(emb_size):
tmp['{}_{}_emb_{}'.format(f1, f2, i)] = emb_matrix[:, i]
del model, emb_matrix, sentences
return tmp
最终模型
训练模型前采用Lightgbm进行初步的特征筛选
最后用我们非常熟悉的Lightgbm进行模型训练,单模型5折最终线上F1=0.8990
from feature_selector import FeatureSelector
fs = FeatureSelector(data = train_label[features], labels = train_label[target])
fs.identify_zero_importance(task = 'classification', eval_metric = 'multiclass',
n_iterations = 10, early_stopping = True)
fs.identify_low_importance(cumulative_importance = 0.97)
low_importance_features = fs.ops['low_importance']
print('====low_importance_features=====')
print(low_importance_features)
for i in low_importance_features:
features.remove(i)
def macro_f1(y_hat, data):
y_true = data.get_label()
y_hat = y_hat.reshape(-1, y_true.shape[0])
y_hat = np.argmax(y_hat, axis=0)
f1_multi = precision_recall_fscore_support(y_true, y_hat, labels=[0, 1, 2])[2]
f1_macro = f1_score(y_true, y_hat, average ="macro")
assert np.mean(f1_multi) == f1_macro
return 'f1', f1_macro, True
params = {
'task':'train',
'num_leaves': 63,
'objective': 'multiclass',
'num_class': 3,
'metric': 'None', # [f1_0, f1_1, f1_2],
'min_data_in_leaf': 10,
'learning_rate': 0.01,
'feature_fraction': 0.7,
'bagging_fraction': 0.95,
'early_stopping_rounds': 2000,
# 'lambda_l1': 0.1,
# 'lambda_l2': 0.1,
"first_metric_only": True,
'bagging_freq': 3,
'max_bin': 255,
'random_state': 42,
'verbose' : -1
}
To do:
将渔船每条航行的时序数据当做一个句子/段落/文档进行处理
提取更深含义的渔船航线特征,学习到更高层次的渔船航线规律
多模型加权融合or stacking(lgb,xgb,...)
关注并回复“AILIGHT智慧海洋建设”获取源码链接以及完整的特征分析可视化方案,还没有关注的朋友,扫描下方二维码识别关注吧。有什么建议也可以后台留言哦!
个人微信:加时请注明 (昵称+公司/学校+方向)

也欢迎小伙伴加入NLP交流群,刚刚创的,想和大家讨论NLP(若二维码过期可加作者微信)!

