ASCII,UTF-16,UTF-8编码的区别
在计算机中,所有的数据在存储和运算时,都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0)
ASCII码
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
Unicode
UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
UTF-8
是以字节为单位对Unicode进行编码。
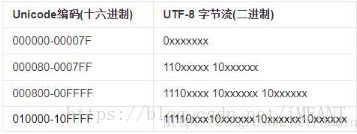
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
例子:
11100110 10001000 10010001 11100110 10011000 10101111 01110100 01100001 01110010 01101111 01101100
以上有11个byte,我们从第一个byte11100110开始,数第一个0前面的1的数量,有3个1,代表3个byte是一组的。然后我们跳过这3个,第四个byte是11100110,继续数1得出有3个1,然后又给这3个byte分组。跳过这三个,到了第7个byte,这往后的5个byte都是以0开头,说明每个byte为1组。现在我们分好组了,有7个组,分别是
[11100110, 10001000, 10010001], [11100110, 10011000, 10101111], [01110100], [01100001], [01110010], [01101111], [01101100]
现在我们按组找到表右对应的行,第一组、第二组对应第五行,其他组对应第三行,我们把行内x对应的位置保留,10的位置删除,得到新的数组
[0110, 001000, 010001], [0110, 011000, 101111], [1110100], [1100001], [1110010], [1101111], [1101100]
然后把组内的二进制串起来得到Unicode
[0110001000010001], [0110011000101111], [1110100], [1110100], [1100001], [1110010], [1101111], [1101100]
这时候我们再按byte进行拆分以便阅读,并且在高位补0
[01100010 00010001], [01100110 00101111], [01110100], [01110100], [01100001], [01110010], [01101111], [01101100]
再转换成16进制
[62 11], [66 2F], [74], [61], [72], [6F], [6C]
这时候我们打开F12,在控制台输入对应的Unicode(语法要求必须使用4位16进制数字)
‘\u6211\u662f\u0074\u0061\u0072\u006f\u006c’
得到了对应的字符串“我是tarol”。
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是6个字节。从上表可以看出,6字节模板有31个x,即可以容纳31位二进制数字。Unicode的最大码位0x7FFFFFFF也只有31位。
UTF-16
UTF-16编码是以16位无符号整型数据为单位的。能够对Unicode的所有1,112,064个有效代码点进行编码。编码是可变长度的,因为编码点是用一个或两个16位代码单元编码的。
Unicode编码0x10000-0x10FFFF的UTF-16编码有两个WORD(一个8位叫做字节,一个16位称为一个字,或者双字节),第一个WORD的高6位是110110,第二个WORD的高6位是110111。可见,第一个WORD的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二个WORD的取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。
1.首先按现在17个平面的限制,辅助平面的码位是U+10000到U+10FFFF,我们得到了一个辅助平面的Unicode码时,先减去BMP的码数0x10000,得到的数介于0到0xFFFFF之间,最多用20bit表示
2.然后我们把20bit从中间隔开,分为高位的10bit和低位的10bit
3.我们知道10bit的取值范围是0到0x3FF,高位的10bit加上固定值0xD800,得到的值叫做前导代理(lead surrogate),范围是0xD800到0xDBFF
4.低位的10bit加上固定值0xDC00,得到的值叫做后尾代理(tail surrogate),范围是0xDC00到0xDFFF。这样一来,不仅高位和低位都落在了保留区块内,而且彼此还做了区分。
例子:
��,这个字是个异体字,通“碎”,位于辅助平面,Unicode码位是U+24B62,我们来算一下它的UTF16编码结果
1.首先0x24B62减去10000得到0x14B62,根据这5个byte得到20bit,0001 0100 1011 0110 0010
2.然后分成高位的10bit(0001010010)和低位的10bit(1101100010)
3.高位+0xD800得到(1101 1000 0101 0010)
4.低位+0xDC00得到(1101 1111 0110 0010)
5.转换为16进制就是0xD852和0xDF62,这就是��的UTF16表示。