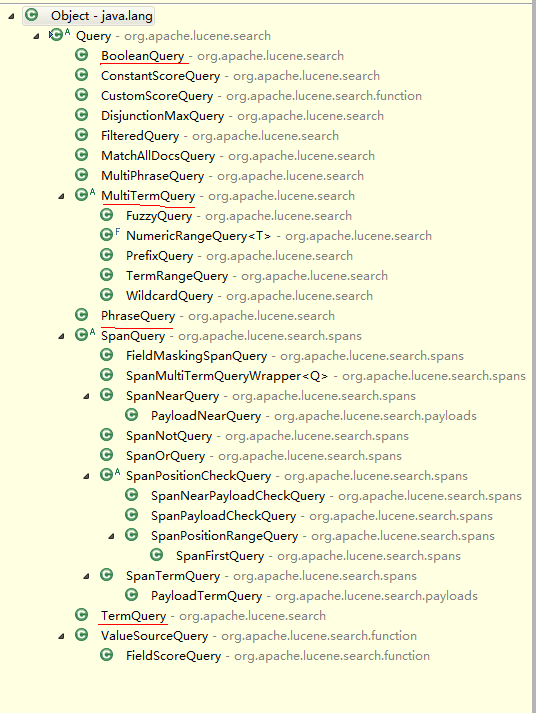
【Lucene】查询term后加上'*'对打分的影响
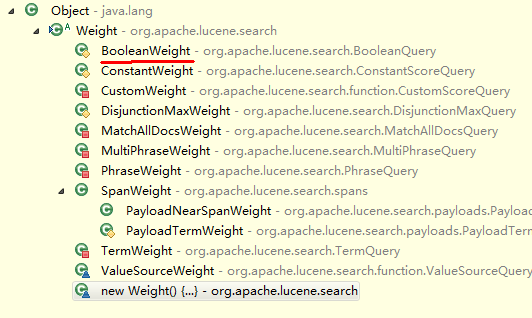
BooleanWeight里sumOfSquaredWeights实现
@Override
public float sumOfSquaredWeights() throws IOException {
float sum = 0.0f;
for (int i = 0 ; i < weights.size(); i++) {
// call sumOfSquaredWeights for all clauses in case of side effects
float s = weights.get(i).sumOfSquaredWeights(); // sum sub weights
if (!clauses.get(i).isProhibited())
// only add to sum for non-prohibited clauses
sum += s;
}
sum *= getBoost() * getBoost(); // boost each sub-weight
return sum ;
}
query=1065800715* OR 106580071517
在BooleanWeight里sumOfSquaredWeights打断点,查看值如下:
Weight对象树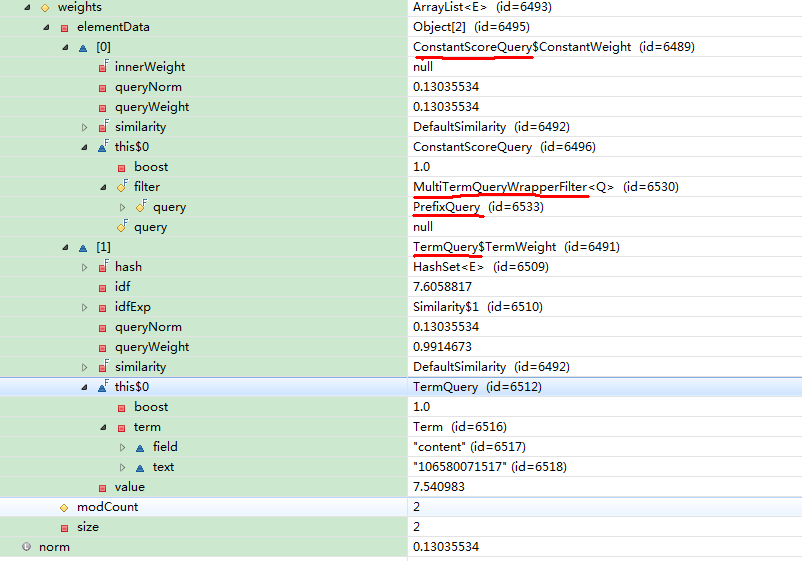
》》》继续 《lucene原理与代码分析》p266
query=1065800715*
note:没有执行ConstantScoreQuery.sumOfSquaredWeights()、TermQuery.sumOfSquaredWeights()
====================分析=====================
对查询语句解析会生成一个Query对象树,
如Query query = queryParser.parse("+(+apple* -boy)(cat* dog)-(eat~ foods)");
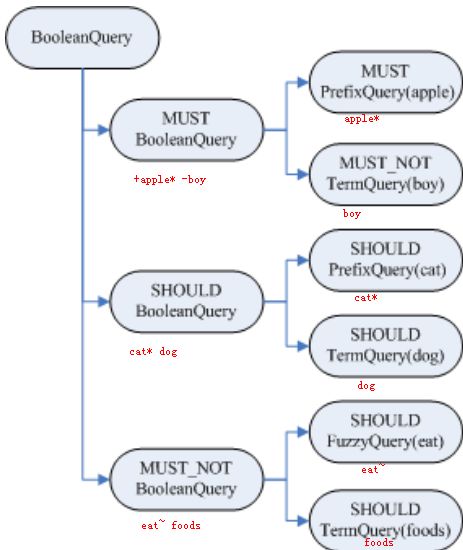
在树的叶子节点中:
1.最基本的是TermQuery,表示一个词
2.还可以是PrefixQuery(前缀查询)、FuzzyQuery(模糊查询),这些查询语句由于特殊的语法,可能对应的不是一个词,而是多个词,在查询过程中会得到特殊处理。
PrefixQuery,比如 PrefixQuery("/usr/local")那么"/usr/local/a"、"/usr/local/b"都满足该前缀,term就有多个;
FuzzyQuery,用于匹配与指定term相似的term,如"three"和"tree";
在搜索过程中,会重写Query对象树,重写过程是一个递归过程,会一直处理到叶子节点。如果有子句被重写,则返回新的对象树,否则获得的是老的Query对象树。
为什么要对Query对象树重写(Query对象树重写是怎样一个过程)?
Query树的叶子节点基本是两种,或是TermQuery,或是MultiTermQuery(如上面提到的 PrefixQuery和 FuzzyQuery )。
MultiTermQuery继承结构如下:
TermQuery的重写方法返回对象本身,真正需要重写的是MultiTermQuery,也即一个Query代表多个Term参与查询。
重写过程如下:
首先,从索引文件的词典中,将多个Term都找出来,比如"appl*",可以从词典中找出如下Term:"apple","apples","apply",这些Term都要参与查询,而非原来的"appl*"参与查询过程,因为词典中是没有"appl*"。
然后,将取出的多个Term重新组织成新的Query对象进行查询(就是上面说的Query对象树重写),基本有两种方式:
方式1:将多个Term看成一个Term,即将包含它们的文档号取出来放在一起(Docid set),作为一个统一的倒排表参与倒排表的合并。——具体实现可以参看源码
对于方式1,多个Term,将包含Term的文档号放在一个docid set里,作为统一倒排表参与合并,这样多个Term之间的tf,idf的差别就会被忽略,所以采用方式一的RewriteMethod为CONSTANT_SCORE_XXX,也即除了用户指定的query boost(和 queryNorm )外,其他的因子不参与计算。
查看search的explanation:
1.0 = (MATCH) ConstantScore(content:1065800715*), product of:
1.0 = boost
1.0 = queryNorm
1.7799454 = (MATCH) sum of:
0.13035534 = (MATCH) ConstantScore(content:1065800715*), product of:
1.0 = boost
0.13035534 = queryNorm
1.64959 = (MATCH) weight(content:106580071517 in 900495), product of:
0.9914673 = queryWeight(content:106580071517), product of:
7.6058817 = idf(docFreq=14268, maxDocs=10550949)
0.13035534 = queryNorm
1.6637866 = (MATCH) fieldWeight(content:106580071517 in 900495), product of:
1.0 = tf(termFreq(content:106580071517)=1)
7.6058817 = idf(docFreq=14268, maxDocs=10550949)
0.21875 = fieldNorm(field=content, doc=900495)
至
0.06517767 = (MATCH) product of:
0.13035534 = (MATCH) sum of:
0.13035534 = (MATCH) ConstantScore(content:1065800715*), product of:
1.0 = boost
0.13035534 = queryNorm
0.5 = coord(1/2)
方式2:将多个Term组成一个BooleanQuery,这些Term之间是OR的关系。
对于 MultiTermQuery这种查询打分忽略tf-idf是合理的么?
Lucene认为对于 MultiTermQuery这种查询,打分忽略tf-idf是合理的。因为当用户输入"appl*"时,用户也不确切清楚索引中有什么与"appl*"相关,也就不偏爱其中之一,这样计算词之间的差别(tf-idf)对用户而言也就没有什么意义。
何时用方式一进行Query对象树重写?
如果Term数目超限,或者文档数目超限(在播发日志查询里,如查1065800715*就属于这种情况),采用的是方式一,这样能避免文档数目太多而使倒排表合并大的性能消耗。
方式一源码分析:
MultiTermQuery里
public static final RewriteMethod CONSTANT_SCORE_FILTER_REWRITE = new RewriteMethod() {
@Override
public Query rewrite(IndexReader reader, MultiTermQuery query) {
Query result = new ConstantScoreQuery(new MultiTermQueryWrapperFilter(query));
result.setBoost(query.getBoost());
return result;
}
// Make sure we are still a singleton even after deserializing
protected Object readResolve() {
return CONSTANT_SCORE_FILTER_REWRITE;
}
}; MultiTermQueryWrapperFilter
/**
* Returns a DocIdSet with documents that should be
* permitted in search results.
*/
@Override
public DocIdSet getDocIdSet(IndexReader reader) throws IOException {
//得到MutilTermQuery的Term枚举器
final TermEnum enumerator = query.getEnum(reader);
try {
// if current term in enum is null, the enum is empty -> shortcut
if (enumerator.term() == null)
return DocIdSet.EMPTY_DOCIDSET;
// else fill into a FixedBitSet
//创建包含多个Term的文档号集合
final FixedBitSet bitSet = new FixedBitSet(reader.maxDoc());
final int[] docs = new int[32];
final int[] freqs = new int[32];
TermDocs termDocs = reader.termDocs();
try {
int termCount = 0;
//每次循环,取出MutilTermQuery中的Term,取出还有该Term的所有文档号,加入集合中
do {
Term term = enumerator.term();
if (term == null)
break;
termCount++;
termDocs.seek(term);
while (true) {
final int count = termDocs.read(docs, freqs);
if (count != 0) {
for(int i=0;i
附:
Lucene Query继承结构