Ubuntu系统下用U-Net模型进行细胞分割的学习成果(附代码)
最近在做有关细胞分割的毕设内容,用到了U-Net模型,于是本小白花了十几天时间摸爬滚打从配置环境到修改代码终于把这个模型搞懂了!下面简单总结一下自己修改出来的代码。
原文出处
U-Net: Convolutional Networks for Biomedical Image Segmentation
也可以直接从我的网盘链接看论文原文和原代码
链接:https://pan.baidu.com/s/1LDVjZNTJWXt8Y-z5j9X3-w
提取码:l1vy
环境配置
(因为我跑代码时总是遇到因为版本不匹配无法运行的情况,所以我会尽量把版本信息写的细点)
系统:Ubuntu 16.04.4
Anaconda版本:4.5.0
Python版本:3.6.0
Keras版本:2.2.4
Keras后端:TensorFlow-GPU 1.3.0
Keras后端:TensorFlow-GPU 1.2.0(更新一下)
大致思路
U-Net模型是目前比较常用的用于细胞分割的深度学习模型。输入一些细胞图像以及每张图对应的标记出轮廓的标记图像作为训练集(由于人工进行标记是个很繁琐的过程,一般也不容易获取到大量细胞图并对其标记,所以本文采取弹性形变的方法,将原本的30对训练集的图像进行扩充),通过U型网络的训练产生一个训练模型,之后用新的细胞图像作为测试集来对训练模型进行测试。
原始训练集的原始图像
从0开始按顺序标号,保存为png格式
原始训练集的标记图像
从0开始以‘_mask’为后缀按顺序标号,保存为png格式

一定要注意保存的时候每组图的对应关系是否正确!!!
我就因为把顺序存乱了导致最后训练效果极差找不到原因而苦恼了好久。。。
文件夹的安排
我总共分了以下几个文件夹:

其中code用于存放代码及之后的训练模型,data是原始的数据(将原始数据处理完后这个文件夹可以删掉),deform存放通过弹性形变进行扩充后的训练集(在这里建两个文件夹train和label,分别存放),npydata存放训练中产生的npy文件,results存放测试出来的结果,test为测试集
代码介绍
原代码中有一部分我没用上,就给删了,顺便根据我的需求对其进行了修改,并加入了一些我自己的文件,最后分为了以下几个文件:elastic_deform.py、data.py、unet.py、see.py
原文所提供的数据是三个图片集,train,label,test各为30张叠在一起的图片,这里我直接用wps把每张图片都提取了出来。原代码中好像也有提取图片相关的代码,正好我用不到了也没太看懂,就连着数据增强部分一起都删了,之后用其他的代码用弹性形变对数据进行了增强处理。
elastic_deform.py
这部分代码是从网上找的,有一些改动。用于将原有的30张进行扩充。每运行一遍这个文件可以产生30张形变的用于训练的数据。加上原始的训练集数据,我一共用了150组数据作为最后的训练集,从测试结果看来150组够用了。
import numpy as np
import cv2
from skimage import exposure
import random
from scipy.ndimage.interpolation import map_coordinates
from scipy.ndimage.filters import gaussian_filter
from skimage.transform import rotate
from PIL import Image
def elastic_transform(image, alpha, sigma, alpha_affine, random_state=None):
"""
Elastic deformation of images as described in [Simard2003]_ (with modifications).
.. [Simard2003] Simard, Steinkraus and Platt, "Best Practices for
Convolutional Neural Networks applied to Visual Document Analysis", in
Proc. of the International Conference on Document Analysis and
Recognition, 2003.
Based on https://gist.github.com/erniejunior/601cdf56d2b424757de5
"""
if random_state is None:
random_state = np.random.RandomState(None)
shape = image.shape
shape_size = shape[:2]
# Random affine
center_square = np.float32(shape_size) // 2
square_size = min(shape_size) // 3
pts1 = np.float32([center_square + square_size, [center_square[0] + square_size, center_square[1] - square_size],
center_square - square_size])
pts2 = pts1 + random_state.uniform(-alpha_affine, alpha_affine, size=pts1.shape).astype(np.float32)
M = cv2.getAffineTransform(pts1, pts2)
image = cv2.warpAffine(image, M, shape_size[::-1], borderMode=cv2.BORDER_REFLECT_101)
dx = gaussian_filter((random_state.rand(*shape) * 2 - 1), sigma) * alpha
dy = gaussian_filter((random_state.rand(*shape) * 2 - 1), sigma) * alpha
x, y, z = np.meshgrid(np.arange(shape[1]), np.arange(shape[0]), np.arange(shape[2]))
indices = np.reshape(y + dy, (-1, 1)), np.reshape(x + dx, (-1, 1)), np.reshape(z, (-1, 1))
return map_coordinates(image, indices, order=1, mode='reflect').reshape(shape)
# Define function to draw a grid
def draw_grid(img, grid_size):
# Draw grid lines
for x in range(0, img.shape[1], grid_size):
cv2.line(img, (x, 0), (x, im.shape[0]), color=(255,))
for y in range(0, img.shape[0], grid_size):
cv2.line(img, (0, y), (im.shape[1], y), color=(255,))
def augmentation(image, imageB, org_width=256, org_height=256, width=270, height=270):
max_angle = 360
image = cv2.resize(image, (height, width))
imageB = cv2.resize(imageB, (height, width))
angle = np.random.randint(max_angle)
if np.random.randint(2):
angle = -angle
image = rotate(image, angle, resize=True)
imageB = rotate(imageB, angle, resize=True)
xstart = np.random.randint(width - org_width)
ystart = np.random.randint(height - org_height)
image = image[xstart:xstart + org_width, ystart:ystart + org_height]
imageB = imageB[xstart:xstart + org_width, ystart:ystart + org_height]
if np.random.randint(2):
image = cv2.flip(image, 1)
imageB = cv2.flip(imageB, 1)
if np.random.randint(2):
image = cv2.flip(image, 0)
imageB = cv2.flip(imageB, 0)
image = cv2.resize(image, (org_height, org_width))
imageB = cv2.resize(imageB, (org_height, org_width))
return image, imageB
for i in range(0, 30):
# Load images
print(i)
im = cv2.imread('../data/train/%d.png' % i, 0) # 原始训练集的原始图像的位置
im_mask = cv2.imread('../data/label/%d_mask.png' % i, 0) # 原始训练集的标记图像的位置
# 以下两行每次选一行注释掉
im = exposure.adjust_gamma(im, random.uniform(1.2, 1.8)) # 调暗
# im = exposure.adjust_gamma(im, random.uniform(0.6, 0.9)) # 调亮
a, b = augmentation(im, im_mask)
# Merge images into separete channels (shape will be (cols, rols, 2))
im_merge = np.concatenate((im[..., None], im_mask[..., None]), axis=2)
# Apply transformation on image
im_merge_t = elastic_transform(im_merge, im_merge.shape[1] * 2, im_merge.shape[1] * 0.1, im_merge.shape[1] * 0.1)
# Split image and mask
im_t = im_merge_t[..., 0]
im_mask_t = im_merge_t[..., 1]
origin = Image.fromarray(im_merge_t[..., 0])
# 下面的120在每次运行时要进行更改,表示保存图像时第一张图的标号
# 如果把原始数据也算作最后训练集的一组,第一次从30开始,之后依次改为60、90、120
origin.save('../deform/train/%d.png' % (i + 120)) # 形变后的原始图像存放位置
label = Image.fromarray(im_merge_t[..., 1])
label.save('../deform/label/%d_mask.png' % (i + 120)) # 形变后的标记图像存放位置
data.py
用于读取训练集和测试集的数据并存为npy文件,方便之后模型训练时进行读取。
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
import numpy as np
import os
import glob
import cv2
OUT_ROWS = 256 # 确定模型要识别的图像的高和宽
OUT_COLS = 256
class dataProcess(object):
def __init__(self, out_rows, out_cols, data_path="../deform/train", label_path="../deform/label",
test_path="../test", npy_path="../npydata", img_type="png"):
"""
A class used to process data.
"""
self.out_rows = out_rows
self.out_cols = out_cols
self.data_path = data_path
self.label_path = label_path
self.img_type = img_type
self.test_path = test_path
self.npy_path = npy_path
# 创建训练集的npy文件
def create_train_data(self):
print('-'*30)
print('Creating training images...')
print('-'*30)
imgs = os.listdir(self.data_path)
total = len(imgs)
print(total)
imgdatas = np.ndarray((total, self.out_rows, self.out_cols, 1), dtype=np.uint8)
imglabels = np.ndarray((total, self.out_rows, self.out_cols, 1), dtype=np.uint8)
i = 0
for i in range(total):
imgname = str(i) + "." + self.img_type
labelname = str(i) + "_mask." + self.img_type
img = cv2.imread(os.path.join(self.data_path, imgname), cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (OUT_ROWS, OUT_COLS))
label = cv2.imread(os.path.join(self.label_path, labelname), cv2.IMREAD_GRAYSCALE)
label = cv2.resize(label, (OUT_ROWS, OUT_COLS))
imgdatas[i, :, :, 0] = img
imglabels[i, :, :, 0] = label
if i % 10 == 0:
print('Done: {0}/{1} images'.format(i, total))
i += 1
print('loading done')
np.save(self.npy_path + '/imgs_train.npy', imgdatas)
np.save(self.npy_path + '/imgs_mask_train.npy', imglabels)
print('Saving to .npy files done.')
return i
# 创建测试集的npy文件
def create_test_data(self):
print('-'*30)
print('Creating test images...')
print('-'*30)
imgs = os.listdir(self.test_path)
total = len(imgs)
print(total)
imgdatas = np.ndarray((total, self.out_rows, self.out_cols, 1), dtype=np.uint8)
i = 0
for i in range(total):
imgname = str(i) + "." + self.img_type
img = cv2.imread(os.path.join(self.test_path, imgname), cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (OUT_ROWS, OUT_COLS))
imgdatas[i, :, :, 0] = img
if i % 10 == 0:
print('Done: {0}/{1} images'.format(i, total))
i += 1
print('loading done')
np.save(self.npy_path + '/imgs_test.npy', imgdatas)
print('Saving to imgs_test.npy files done.')
return i
# 读取训练集的npy文件
def load_train_data(self):
print('-'*30)
print('load train images...')
print('-'*30)
imgs_train = np.load(self.npy_path+"/imgs_train.npy")
imgs_mask_train = np.load(self.npy_path+"/imgs_mask_train.npy")
imgs_train = imgs_train.astype('float32')
imgs_mask_train = imgs_mask_train.astype('float32')
imgs_train /= 255
mean = imgs_train.mean(axis=0)
imgs_train -= mean
imgs_mask_train /= 255
imgs_mask_train[imgs_mask_train > 0.5] = 1
imgs_mask_train[imgs_mask_train <= 0.5] = 0
return imgs_train, imgs_mask_train
# 读取测试集的npy文件
def load_test_data(self):
print('-'*30)
print('load test images...')
print('-'*30)
imgs_test = np.load(self.npy_path+"/imgs_test.npy")
imgs_test = imgs_test.astype('float32')
imgs_test /= 255
mean = imgs_test.mean(axis=0)
imgs_test -= mean
return imgs_test
if __name__ == "__main__":
mydata = dataProcess(OUT_ROWS, OUT_COLS)
mydata.create_train_data()
mydata.create_test_data()
unet.py
用于对训练模型进行训练并用测试集对训练出来的模型进行测试。
import numpy as np
from keras.models import *
from keras.layers import Input, merge, Conv2D, MaxPooling2D, UpSampling2D, Dropout, Cropping2D, Concatenate
from keras.optimizers import *
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
from keras import backend as keras
from data import dataProcess, OUT_ROWS, OUT_COLS
import pandas as pd
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
class myUnet(object):
def __init__(self, img_rows=OUT_ROWS, img_cols=OUT_COLS, BATCH_SIZE = 8, EPOCHS = 200, UNET = 'unet.hdf5'):
# UNET为模型名称,BACTH_SIZE为一次输入图片数量,EPOCHS为训练轮数
self.img_rows = img_rows
self.img_cols = img_cols
self.BATCH_SIZE = BATCH_SIZE
self.EPOCHS = EPOCHS
self.unet_name = UNET
def load_train_data(self):
mydata = dataProcess(self.img_rows, self.img_cols)
imgs_train, imgs_mask_train = mydata.load_train_data()
imgs_test = mydata.load_test_data()
return imgs_train, imgs_mask_train
def load_test_data(self):
mydata = dataProcess(self.img_rows, self.img_cols)
imgs_test = mydata.load_test_data()
return imgs_test
def get_unet(self):
inputs = Input((self.img_rows, self.img_cols, 1))
'''
unet with crop(because padding = valid)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(inputs)
print "conv1 shape:",conv1.shape
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv1)
print "conv1 shape:",conv1.shape
crop1 = Cropping2D(cropping=((90,90),(90,90)))(conv1)
print "crop1 shape:",crop1.shape
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
print "pool1 shape:",pool1.shape
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool1)
print "conv2 shape:",conv2.shape
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv2)
print "conv2 shape:",conv2.shape
crop2 = Cropping2D(cropping=((41,41),(41,41)))(conv2)
print "crop2 shape:",crop2.shape
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
print "pool2 shape:",pool2.shape
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool2)
print "conv3 shape:",conv3.shape
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv3)
print "conv3 shape:",conv3.shape
crop3 = Cropping2D(cropping=((16,17),(16,17)))(conv3)
print "crop3 shape:",crop3.shape
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
print "pool3 shape:",pool3.shape
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
crop4 = Cropping2D(cropping=((4,4),(4,4)))(drop4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = merge([crop4,up6], mode = 'concat', concat_axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
merge7 = merge([crop3,up7], mode = 'concat', concat_axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
merge8 = merge([crop2,up8], mode = 'concat', concat_axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
merge9 = merge([crop1,up9], mode = 'concat', concat_axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv9)
'''
conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(inputs)
print("conv1 shape:", conv1.shape)
conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv1)
print("conv1 shape:", conv1.shape)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
print("pool1 shape:", pool1.shape)
conv2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool1)
print("conv2 shape:", conv2.shape)
conv2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv2)
print("conv2 shape:", conv2.shape)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
print("pool2 shape:", pool2.shape)
conv3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool2)
print("conv3 shape:", conv3.shape)
conv3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv3)
print("conv3 shape:", conv3.shape)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
print("pool3 shape:", pool3.shape)
conv4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool3)
conv4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation='relu', padding='same', kernel_initializer='he_normal')(UpSampling2D(size=(2, 2))(drop5))
merge6 = Concatenate(axis=3)([drop4, up6])
conv6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge6)
conv6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv6)
up7 = Conv2D(256, 2, activation='relu', padding='same', kernel_initializer='he_normal')(UpSampling2D(size=(2, 2))(conv6))
merge7 = Concatenate(axis=3)([conv3, up7])
conv7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge7)
conv7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv7)
up8 = Conv2D(128, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(conv7))
merge8 = Concatenate(axis=3)([conv2, up8])
conv8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge8)
conv8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv8)
up9 = Conv2D(64, 2, activation='relu', padding='same', kernel_initializer='he_normal')(UpSampling2D(size=(2, 2))(conv8))
merge9 = Concatenate(axis=3)([conv1, up9])
conv9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge9)
conv9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv9)
conv9 = Conv2D(2, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv9)
conv10 = Conv2D(1, 1, activation='sigmoid')(conv9)
model = Model(inputs=inputs, outputs=conv10) # input output
model.compile(optimizer=Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy'])
return model
def train(self):
print("loading data")
imgs_train, imgs_mask_train = self.load_train_data()
print("loading data done")
model = self.get_unet()
print("got unet")
model_checkpoint = ModelCheckpoint(self.unet_name, monitor='loss', verbose=1, save_best_only=True)
print('Fitting model...')
model.fit(imgs_train, imgs_mask_train, batch_size=self.BATCH_SIZE, epochs=self.EPOCHS, verbose=1, shuffle=True, callbacks=[model_checkpoint])
def test(self):
model = load_model(self.unet_name)
print("loading data")
imgs_test = self.load_test_data()
print('predict test data')
imgs_mask_test = model.predict(imgs_test, batch_size=1, verbose=1)
np.save('../npydata/imgs_mask_test.npy', imgs_mask_test)
if __name__ == '__main__':
myunet = myUnet()
myunet.train()
myunet.test()
see.py
用于将训练结果从npy格式转换成png格式的图片。
import numpy as np
import cv2
def see(i_path, m_path, s_path):
image = np.load(i_path)
mask = np.load(m_path)
for i in range(0, image.shape[0]):
cv2.imwrite(s_path + str(i) + ".png", image[i, :, :])
cv2.imwrite(s_path + str(i) + "_mask.png", mask[i, :, :])
print(str(i), "is saved.")
print("All works are finished.")
if __name__ == '__main__':
img_path = "../npydata/imgs_test.npy"
mask_path = "../npydata/imgs_mask_test.npy"
save_path = "../results/0325/"
see(img_path, mask_path, save_path)
转换出来的标记图像可能因为格式问题是全黑的,这里我用MATLAB处理了以下就可以看到正常的图像啦。
clear,clc,close all;
filenames=dir('*_mask.png');
for i=1:length(filenames)
filename=imread([num2str(i - 1) '_mask.png']);
temp = double(filename);
imwrite(temp, [num2str(i - 1) '_mask.png']);
end
训练模型的测试结果
以下为测试集及其通过训练模型得到的标记结果。
其他问题
匹配问题
这是非常重要的一点,安装的tensorflow版本一定要和显卡匹配!至少也要是接近的版本,具体匹配版本可以参考这篇博客:tensorflow各个版本的CUDA以及Cudnn版本对应关系
我的CUDA是8.0,cudnn是5.1.10,应该对应1.2.0的tensorflow。
最初不知道这个问题装的1.14.0的tensorflow,一直运行报错,找了好久原因才发现是我们学校CUDA版本太低了,又不得不退到1.2.0的版本才能运行程序 (虽然后来因为各种原因改装成了1.3.0,不过好像因为版本没差那么多也没啥影响) 更新一下,1.3是模型训练完才改装的,之后再训练一直不出结果,重新装回1.2后才能跑,事实证明版本真的必须得对应,错一点都不行!
附上查显卡版本的方法:
CUDA版本:nvcc -V (最后一行为版本信息)
cudnn版本:cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR (三行的数字合起来为版本号X.X.X)
版本查询
打开终端的命令应该都会了,为了全面我就顺便提一下:Ctrl+Alt+T
以下附上我的查询结果
系统版本:cat /proc/versionad
![]()
Anaconda版本:conda -V
![]()
在终端打开Python后可以直接看到Python的版本
打开Python:python
在Python中查询各类安装包的版本,以tensorflow为例:
import tensorflow as tf
tf.__version__

这里查询TensorFlow版本的时候还是查的1.3.0,不过还是得改成1.2.0。
虚拟环境
从上一张图也看到了,因为我是用的学校服务器,其他人所用后端跟我不一样,为了不影响别人使用,我创建了一个以tensorflow为名的虚拟环境,创建方法也很简单:conda create -n tensorflow
之后需要安装的安装包全都在这个虚拟环境下执行,就不会影响外面的大环境啦!
不过在使用虚拟环境中的python时要先激活:source activate tensorflow
激活后输入指令最左边会出现虚拟环境的名字。
所有操作完成后可以关闭虚拟环境:source deactivate tensorflow
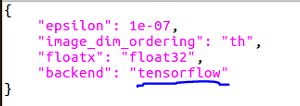
要注意的是,tensorflow下载好后需要在系统文件.keras.json中确认下后端是否是tensorflow,如果不是的话即使安装好了keras也是无法正常运行的哦!
从终端打开.keras.json:sudo gedit ~/.keras/keras.json
打开后大概长这样,其他行不用管,就要注意backend是不是对应的tensorflow