【scrapy爬虫】结合正则表达式爬取糗事百科段子首页步骤详解
糗事百科爬虫首页及全站段子爬取步骤详解
- 1. 前提说明
- 2. 创建项目
- 3. 创建爬虫模板
- 4. items.py文件修改
- 5. 爬虫模板文件修改
- 5.1 模板可行性检验
- 5.2 相关字段数据爬取
- 5.3 相关字段数据爬取全部代码
- 6. settings.py文件修改
- 7. pipeline.py文件修改
手动反爬虫:原博地址
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
如若转载,请标明出处,谢谢!
1. 前提说明
前面的item内容字段数据的爬取采用了xpath语法和css语法,那么这一部分就尝试着使用re正则表达式来进行,关于基础scrapy知识可以参看Scrapy安装、详细指令参数讲解及第一个项目实例
2. 创建项目
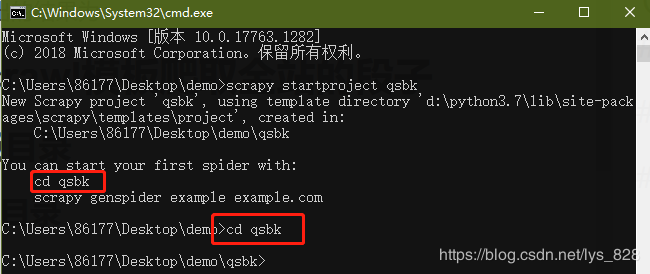
在一个指定的文件路径下,打开cmd,输入创建爬虫项目的指令,文件夹创建完成后,并进入提示路径
scrapy startproject qsbk
→ 输出的结果为:(创建文件夹成功后,注意进入这个指定的文件夹下)
3. 创建爬虫模板
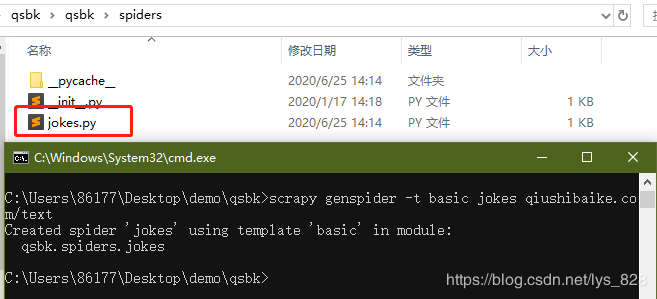
这里选择的是basic模板,创建的指令如下
scrapy genspider -t basic jokes qiushibaike.com/text
→ 输出的结果为:(会在spiders文件夹下多出一个jokes.py文件)
4. items.py文件修改
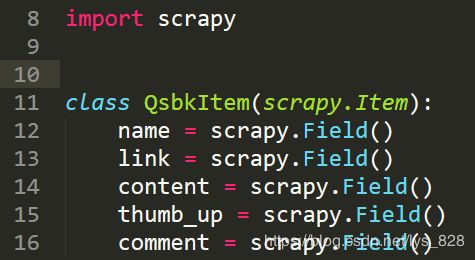
根据要爬取的网站的内容,如下,可以确定要爬取的字段数据,共五个字段,分别为:作者,链接,内容,点赞数,评论数(这些都可以在网页源代码中找到)

修改的item.py文件如下
5. 爬虫模板文件修改
5.1 模板可行性检验
首先习惯性的创建一个爬虫模板后,直接打印返回的内容,看看是否可以正常运行,修改最后一行代码如下,然后在命令行执行爬取的指令
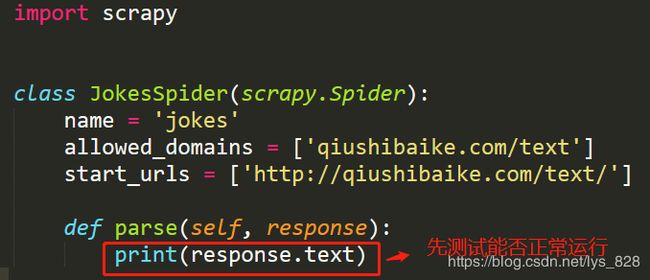
cmd执行的爬取指令
scrapy crawl jokes
输出的结果中显示如下(要求必须使用模拟浏览器的方式爬取)

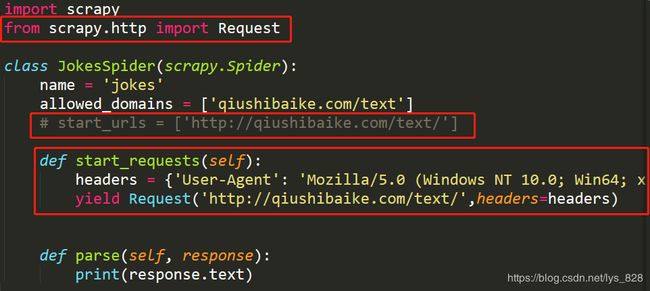
进行代码修改,设置浏览器请求头,baisc模板创建后默认会生成爬取第一页的网址,也就是start_urls参数,这里由于要使用请求头访问,因此可以把这个参数注释掉,自己手动设置请求头和起始网址,需要使用到start_requests函数,注意导入Request方法
保存后在cmd界面执行爬取命令,展示结果如下,可以发现能以正常获取网页内容
这一步的检测非常重要,要养成一个习惯,在爬取内容之前,先测试这个模板是否是直接可用的,然后再进行爬取字段内容代码的输入
5.2 相关字段数据爬取
上面添加请求头之后,就可以正常返回网页请求的数据了,那么接下来就是引入正则表达式,进行相关字段数据的爬取。由于是进行正则表达式提取,所以需要在网页源代码下进行匹配
1) 段子作者
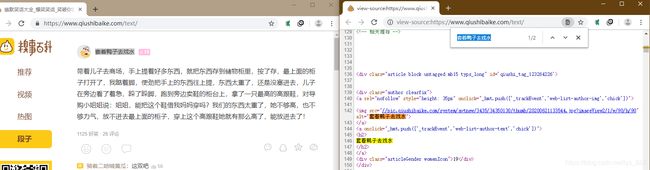
首先需要导入items.py文件中的类名和re库,通过上面的信息匹配可以看到作者信息都是在h2标签中(两个结果中选择简单有规律的标签),对应的数据爬取的代码如下
import scrapy
from scrapy.http import Request
from ..items import QsbkItem
import re
class JokesSpider(scrapy.Spider):
name = 'jokes'
allowed_domains = ['qiushibaike.com/text']
# start_urls = ['http://qiushibaike.com/text/']
def start_requests(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
yield Request('http://qiushibaike.com/text/',headers=headers)
def parse(self, response):
item = QsbkItem()
txt = response.text
item['name'] = re.findall(r'\n(.*?)\n
',txt)
print(item['name'],len(item['name']))
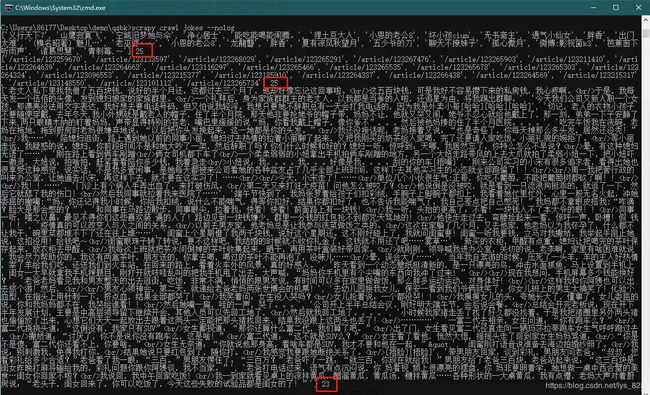
→ 输出的结果为:(刚好对应段子首页的25个作者,后面的计数就是为了验证爬取数据的准确性)

2)段子链接

选取最近的网页链接,进行信息提取,代码如下,直接把网址部分替换
item['link'] = re.findall(r'a href="(.*?)" target="_blank" class="contentHerf"',txt)
print(item['link'],len(item['link']))
★★★ 3) 段子内容的匹配

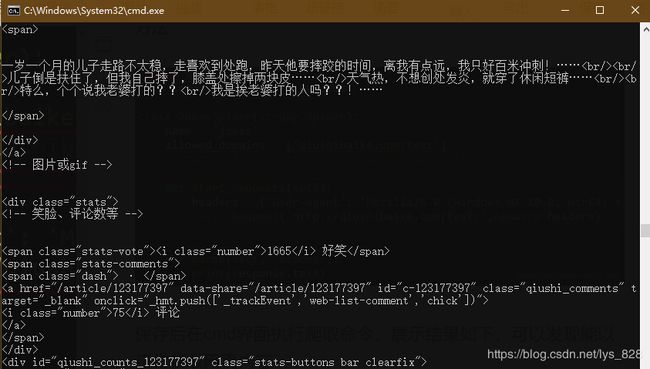
可以看到内容都是在span标签当中,因此可以尝试进行获取,代码如下
item['content'] = re.findall(r'\n\n\n(.*?)\n\n',txt)
print(item['content'],len(item['content']))
→ 输出的结果为:(之前加上的计数,就是为了验证爬取数据的准确性,这里明显少了数据)
因此就需要进行问题的查找,内容都是在span标签中,而span标签太多了,不能作为查找的关键词(这里的意思是如果只查找span这个单词),因此可以查找上面的content标签,对应的刚好为25个结果,然后依次查看每个结果,最终发现问题,如下
a. 尝试着第一次解决问题
第21处,发现多了一个省略号导致并不是两个回车的格式

第25处,也是和上面一样
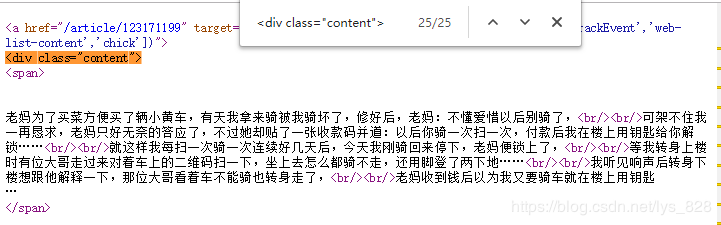
因此代码就需要进行修改,要求可以匹配到一个或者多个回车换行符,代码如下,关于正则表达式的匹配模式可以参考正则表达式模式
#\s匹配字符,匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]
item['content'] = re.findall(r'\s+(.*?)\s+',txt)
print(item['content'],len(item['content']))
→ 输出的结果为:(这时候却发现匹配的结果却多了,存在不需要的信息)

b. 尝试着第二次解决问题
再进行问题的查找,既然内容前后的回车换行符的问题解决了,那么就只剩下内容里面的回车换行符的问题了,因此代码修改如下
#内容中也存在多行,所以偶多次换行的问题,这里使用的就是*,匹配零次或者多次的换行符
item['content'] = re.findall(r'\s+(.*?\s*.*?)\s+',txt)
print(item['content'],len(item['content']))
→ 输出的结果为:(最后的计数检验证明爬取数据成功了)

4) 点赞数匹配

直接可以给出代码
item['thumb_up'] = re.findall(r'(.*?) 好笑',txt)
print(item['thumb_up'],len(item['thumb_up']))
5) 评论数匹配

也是可以直接给出代码
item['comment'] = re.findall(r'(.*?) 评论',txt)
print(item['comment'],len(item['comment']))
5.3 相关字段数据爬取全部代码
也就是爬虫模板jokes.py文件中的全部代码,如下
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from ..items import QsbkItem
import re
class JokesSpider(scrapy.Spider):
name = 'jokes'
allowed_domains = ['qiushibaike.com/text']
# start_urls = ['http://qiushibaike.com/text/']
def start_requests(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
yield Request('http://qiushibaike.com/text/',headers=headers)
def parse(self, response):
item = QsbkItem()
txt = response.text
item['name'] = re.findall(r'\n(.*?)\n
',txt)
item['link'] = re.findall(r'a href="(.*?)" target="_blank" class="contentHerf"',txt)
item['content'] = re.findall(r'\s+(.*?\s*.*?)\s+',txt)
item['thumb_up'] = re.findall(r'(.*?) 好笑',txt)
item['comment'] = re.findall(r'(.*?) 评论',txt)
print(item['name'], len(item['name']))
print(item['link'],len(item['link']))
print(item['content'],len(item['content']))
print(item['thumb_up'],len(item['thumb_up']))
print(item['comment'],len(item['comment']))
return item
→ 输出的结果为:(5个字段的数据量均为25,证明数据获取成功)

6. settings.py文件修改
因为要存储爬取的数据,所以需要开启pipeline管道,修改如下

7. pipeline.py文件修改
确保上一步进行操作了,不然的话,即使代码修改好了也不会保存数据的。在保存数据之前,先查看一下返回的item数据是什么样子的,才能继续下一步操作,很多时候数据的类型并不是我们以为的那样子,比如这里的item就是,看上去像字典,实际上的输出并不是。
操作如下,注释掉模板文件的print语句,在pipeline.py文件中打印item数据及类型,代码如下
class QsbkPipeline(object):
def process_item(self, item, spider):
print(item,type(item))
return item
在cmd执行爬虫指令,输出结果如下

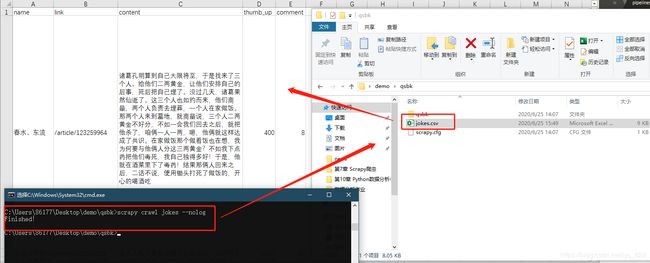
经过查看,发现这种数据转换成为字典之后就是字典套列表的形式,可以直接转化为pandas中的DataFrame格式,然后生成csv或者xlsx文件,代码修改如下
#先导入pandas库
import pandas as pd
class QsbkPipeline(object):
def process_item(self, item, spider):
# print(type(item),item)
df = pd.DataFrame(dict(item)) #转化为字典后之间编程DataFrame数据
df.to_csv('jokes.csv',index=False,encoding='gbk') #注意编码的格式
print('Finished!')
return item
→ 输出的结果为:(数据自动按照设置的字段的先后进行输出了,如过是要在自定义字段输出,因为是DataFrame数据,就变得超级简单了,通过重新制定列顺序即可)
至此,结合正则表达式爬取糗事百科段子首页步骤详解就梳理完毕,下一个博客更新:自动化模板爬取糗事百科全站段子内容步骤详解