R语言学习(二)数据分析数据探索
文章目录
- 第三章 数据探索
- 3.1数据质量分析
- 1.主要任务
- 2.缺失值分析
- 3.异常值分析
- 4.一致性分析
- 3.2数据特征分析
- 1.分布分析
- 2.对比分析
- 3.统计量分析
- 4.周期性分析
- 5.相关性分析
- 3.3 R语言主要数据探索函数
- 1.统计特征函数
- 2.统计作图函数
第三章 数据探索
-
什么是数据探索
数据探索:检测数据,了解数据,这一步只做数据的分析,下一步针对这一步的分析结果,做数据的预处理。
书上的定义:对样本数据集的结构和规律进行分析的过程就是数据探索。数据探索有助于选择合适的数据预处理和建模方法。
为什么叫套路的总结:比如你初到某个地方,要了解这个地方,第一件事情就是可以随便逛随便观察,了解这个地方的结构,数据探索就是做这个事情的。 -
分类
数据质量分析。
数据特征分析。
3.1数据质量分析
1.主要任务
- 缺失值。
- 异常值,甚至不一致的值。
- 重复数据。
- 含有特殊符号的数据(如% # /等)。
2.缺失值分析
- 缺失值产生的原因:各种原因。
- 主要内容:缺失值的个数;缺失率。
- 处理方式:对缺失值进行插值或者直接删掉。
- 注意:这个不是数据质量分析,这个是数据预处理的内容。
3.异常值分析
- 异常值也称为离群点,异常值也称为离群点分析。
- 简单统计量分析:对变量做一个描述型统计,最常用的统计量是最大值和最小值,用来判断这个变量是否有问题。
- 如客户年龄这个变量最大值为199岁,则易知这个变量取值存在异常。
- 3delta原则:如数据服从正态分布,则取值与mean超过3标准差的值为异常值。-> 极小概率事件为异常值。

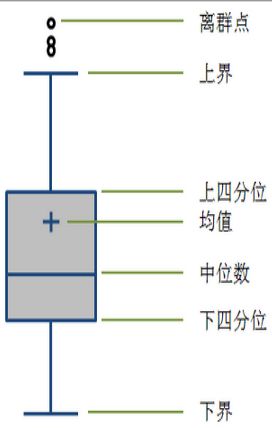
- 箱形图分析
- QU:上四分位置——数据按大小分四段,中段(2和3)最上面值。
- QL:下四分位。
- IQR:四分位间距
- 箱形图分析:异常值通常被定义为小于QL -1.5IQR或大于QU +1.5IQR的值。
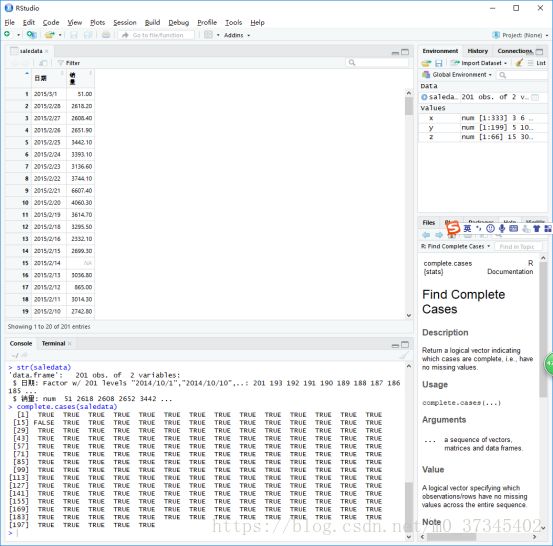
缺失值——complete.cases() 帮助系统 ?complete.cases
> ?complete.cases
> saledata=read.csv(file = "G://!!aaclassnew//R语言//20181011//catering_sale.csv",header = TRUE)
> View(saledata)
> attributes(saledata)
> str(saledata)
> complete.cases(saledata)

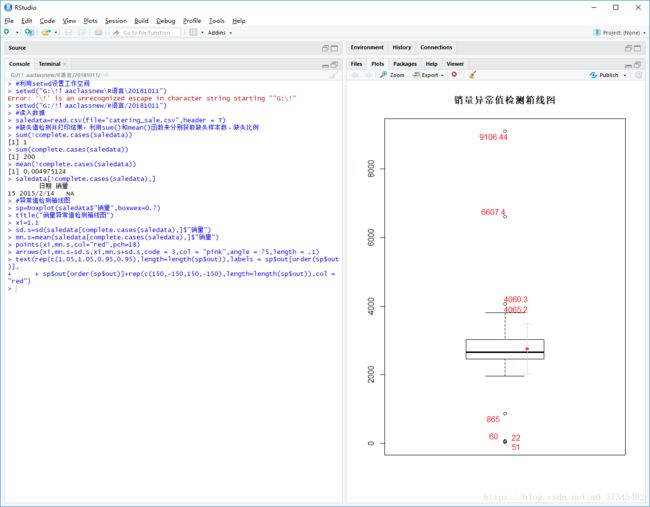
> #利用setwd设置工作空间
> setwd("G:\!!aaclassnew\R语言\20181011")
Error: '\!' is an unrecognized escape in character string starting ""G:\!"
> setwd("G:/!!aaclassnew/R语言/20181011")
> #读入数据
> saledata=read.csv(file="catering_sale.csv",header = T)
> #缺失值检测并打印结果,利用sum()和mean()函数来分别获取缺失样本数、缺失比例
> sum(!complete.cases(saledata))
[1] 1
> sum(complete.cases(saledata))
[1] 200
> mean(!complete.cases(saledata))
[1] 0.004975124
> saledata[!complete.cases(saledata),]
日期 销量
15 2015/2/14 NA
> #异常值检测箱线图
> sp=boxplot(saledata$"销量",boxwex=0.7)
> title("销量异常值检测箱线图")
> xi=1.1
> sd.s=sd(saledata[complete.cases(saledata),]$"销量")
> mn.s=mean(saledata[complete.cases(saledata),]$"销量")
> points(xi,mn.s,col="red",pch=18)
> arrows(xi,mn.s-sd.s,xi,mn.s+sd.s,code = 3,col = "pink",angle = 75,length = .1)
> text(rep(c(1.05,1.05,0.95,0.95),length=length(sp$out)),labels = sp$out[order(sp$out)],
+ + sp$out[order(sp$out)]+rep(c(150,-150,150,-150),length=length(sp$out)),col = "red")
4.一致性分析
- 是指数据相互矛盾,不一致。
- 常发生在不同数据源集成的过程中。
3.2数据特征分析
1.分布分析
对数据整体的一个可视化,从而对数据有个大致的认识。
- 计算出变量的频率分布表,并画出频率分布直方图。
- 基本步骤——就是画频率直方图的步骤:
- 求出极差:最大值-最小值
- 决定组距和组数
- 决定画图时分布区间
- 列出频率分布表
- 绘制直方图
2.对比分析
对两个或多个变量进行比较分析。
绝对值对比或相对值对比。
3.统计量分析
常用指标:集中趋势和离中趋势。
- 集中趋势量
- 均值/期望:什么是均值;什么是期望。
- 中位数:中间那个位置的数——思考偶数个数值和基数个数值的处理。
- 众数:数据集中出现最频繁的值——不具唯一性。
- 离中趋势量
- 极差
- 标准差
- 变异系数:标准差相对于均值的离中趋势。
- 四分位数间距
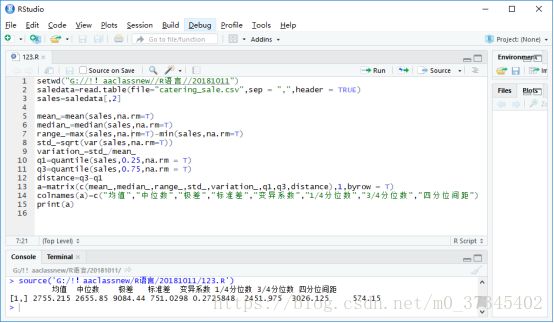
setwd("G://!!aaclassnew//R语言//20181011")
saledata=read.table(file="catering_sale.csv",sep = ",",header = TRUE)
sales=saledata[,2]
#统计量分析
#均值
mean_=mean(sales,na.rm=T)
#中位数
median_=median(sales,na.rm=T)
#极差
range_=max(sales,na.rm=T)-min(sales,na.rm=T)
#标准差
std_=sqrt(var(sales,na.rm=T))
#变异系数
variation_=std_/mean_
#四分位数间距
q1=quantile(sales,0.25,na.rm = T)
q3=quantile(sales,0.75,na.rm = T)
distance=q3-q1
a=matrix(c(mean_,median_,range_,std_,variation_,q1,q3,distance),1,byrow = T)
colnames(a)=c("均值","中位数","极差","标准差","变异系数","1/4分位数","3/4分位数","四分位间距")
print(a)
4.周期性分析
画出变量值-时间轴曲线。
5.相关性分析
- 相关关系:若变量之间存在密切的关系,但又不能由一个或几个变量的值确定另一个变量的值,当自变量x取一定值时,因变量y的值可能有多个,这种变量之间的非一一对应的、不确定的关系,称为相关关系。
- 相关性分析:分析连续变量之间线性相关程度的强弱,并用统计指标表示出来的过程。
- 分析方法:
- 可视化——直接绘制散点图:
- 完全相关:一个变量的取值完全取决于另一个变量。
- 相关
- 不相关
- 计算相关系数:
- Pearson相关系数——要求连续变量取值服从正态分布。
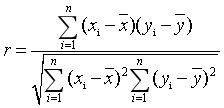

- Pearson相关系数——要求连续变量取值服从正态分布。
- 可视化——直接绘制散点图:
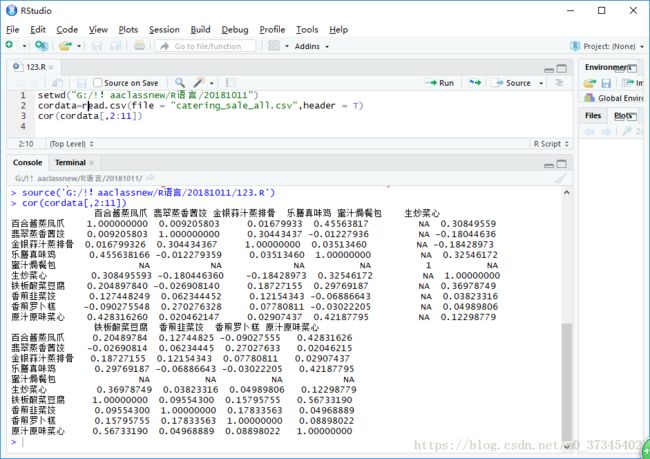
setwd("G:/!!aaclassnew/R语言/20181011")
cordata=read.csv(file = "catering_sale_all.csv",header = T)
cor(cordata[,2:11])
3.3 R语言主要数据探索函数
1.统计特征函数
算术平均数:n<-mean(X)。
- X可为向量、矩阵或多维数组:当成一维计算所有元素的平均值。
- 方差var(): v<-var(X)。
- 若X为向量,计算向量的样本方差;若X为矩阵,则v为各列矩阵向量的样本方差构成的行向量。
- 标准差sd():s=sd(X)——类似var()
- 相关关系矩阵cor():
- R<-cor(x,y=NULL,use=“everything”,method=c(“person”,”Kendall”,”spearman”))
- 计算列向量x,y的相关系数矩阵R。
- use,method参数取值。
- 协方差矩阵cov(): R<-cov(x)
- 若x为向量,R表示x的方差;x为矩阵,cov(x)计算协方差矩阵
- cov(x,y):其中x,y为长度相等的列向量相当于 cov(cbind(x,y))
2.统计作图函数
barplot(x):画条形图。
X可为向量或矩阵。若x为矩阵,依次按列画出条形图。

二维条形直方图
hist(x,freq=TRUE)
X为向量;
把x中的数值自动分组,各组组距相等,条形图每一条的高度表示频率或者频数——频数条形图;频率条形图。
breaks用来设置分组
- 其为一个数值向量时,则为其分组
- 若为一个整数,代表建议R所采取的分组数。
与barplot区别:
- 条形图中间有间隔,多用于分类数据作图。
- 直方图各条中间没有间隔,多用于连续型数据分段作图


箱图:boxplot
箱图:boxplot(x)—绘制向量x的箱形图
中间的箱子的上下边,分别是第三,一个四分位数。
中间的黑线是第二四分位数(中位数)。
设r是变量的四分位距,箱图上方的小横线是小于或等于第三个四分位数+1.5r的最大观测值。同时下方的小横线是,大于等于第一个四分位数减去1.5r的最大的观测值。
图中的小白圈,代表很大可能性上是离群点(outlier).(在其他图中也适用)

函数图/散点图:plot(x,y)
X、y为向量;以x为横轴,y为重轴,画图。
参数teype指定绘图样式
- “o”:散点
- “l”:曲线
- “b”:点线混合
单变量散点图:dotchat(x)
- x为向量或者矩阵,若为矩阵则按列画散点图,然后拼到一起。

