sqoop 导入 hive
sqoop 导入 Hive 分三步:
1. 先导入--target-dir 指定的 HDFS 的目录中
2. 在 Hive 中建表
3. 调用 Hive 的 LOAD DATA INPATH 把 --target-dir中的数据移动到 Hive 中
import
--hive-import
--hive-table dw_hd.ods_store
--connect jdbc:oracle:thin:@
--username user
--password 123456
--query
select * from HD.STORE where $CONDITIONS and \
RCVTIME < TO_TIMESTAMP('2017-05-30 00:00:00','yyyy-mm-dd hh24:mi:ss.ff')
--split-by FLOWNO
--direct
--target-dir /user/root/store
--null-string '\\N'
--null-non-string '\\N'
--m 2
--hive-import :指定是导入 Hive
--hive-table:导入 Hive 中的数据库名和表名
--null-string和 --null-non-string:分别代表了 sqoop 对 字符串类型 null 值 和 非字符串类型 null 值 的处理。如果不指定的话,默认导入 Hive 后 字符串类型的 null 值是 ‘null’,非字符串类型 null 值是 ‘NULL’,这里用把这两种情况统一成了 ‘NULL’,sqoop 中用 ‘\N’,如果想要小写的 ‘null’ 的话,使用 ‘\N’。
问题1:导入后从Hive中查到的数据条数比实际从关系数据库中查到的条数多?
解决:原因是使用--hive-import 会使用默认的 Hive 的分隔符,值分隔符^A和行分隔符\n。
这样问题就来了,如果导入的数据中有’\n’,hive会认为一行已经结束,后面的数据被分割成下一行。这种情况下,导入之后hive中数据的行数就比原先数据库中的多,而且会出现数据不一致的情况。
Sqoop也指定了参数 --fields-terminated-by和 --lines-terminated-by来自定义行分隔符和列分隔符。
可是当你真的这么做时 坑爹呀!
INFO hive.HiveImport: FAILED: SemanticException 1:381 LINES TERMINATED BY only supports newline ’\n’ right now. 也就是说虽然你通过--lines-terminated-by指定了其他的字符作为行分隔符,但是hive只支持\n作为行分隔符。
ORACLE中查询某个字段包含 回车 换行 符,||不是或,是 oracle 中的字符串连接符。%是通配符,代表任意字符串。
查看是否包含 回车换行 符,即:\r\n
select * from system.test_tab1 where name like '%'||chr(13)||chr(10)||'%'
单独查看是否包含 回车换行 符,即:\r
select * from system.test_tab1 where name like '%'||chr(13)||'%'
单独查看是否包含 换行 符,即:\n
select * from system.test_tab1 where name like '%'||chr(10)||'%'
解决方法:简单的解决办法就是加上参数--hive-drop-import-delims来把导入数据中包含的hive默认的分隔符去掉。这个最简单,如果确定数据中不该含有这些字符的话,或者确定去掉没影响的话,可以用这个。另外,使用这个就没法使用 --direct 选项了。
sqoop增量导入hive
问题1:导入后每一行所有数据都在第一个字段里?
原因和解决:因为直接导入 HDFS 中 HIve 里的文件夹下的话,sqoop 默认给的 值分隔符 是逗号 ,,而 Hive 默认值分割符是\001,即:^A,所以 Hive 是不认的,所以 需要 把值分隔符改成 ^A,即加上下边的配置:
--fields-terminated-by \001
定义 sqoop job 增量导入
用 sqoop job 做增量更新,它会在它的 metastore 中管理 --last-value,很方便。
step 1 创建sqoop job
a.配置sqoop metastore服务
修改sqoop/conf/sqoop-site.xml文件
相关属性:
sqoop.metastore.server.location
sqoop.metastore.server.port
sqoop.metastore.client.autoconnect.url
b.启动metasotre,控制台执行sqoop metastore命令(如果没有配置前三个属性,请跳过此步骤)
sqoop metastore --shutdown 停止metastore
启动metastore用nohup的方式启动 nohup command &
c.创建sqoop job
(为了方便执行,将下面的脚本写入到文件保存,然后用chmod u+x FILENAME修改权限后,通过 ./FILENAME执行文件,创建job)
1. 使用时间戳的方式增量导入
sqoop import --connect ${jdbc_driver} \
--username ${user_name} \
--password ${password} \
--table ${table_name} \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--incremental lastmodified \
--merge-key FID \
--check-column WORKDATE \
--last-value "2019-06-15" \
--hive-database ${hive_database} \
--null-string '\\N' \
--null-non-string '\\N' \
--hive-drop-import-delims
2. 使用主键自增的方式增量导入
sqoop job --create ${job_name} \
-- import \
--connect ${jdbc_driver} \
--username ${user_name} \
--password ${password} \
--table ${table_name} \
--hive-import \
--hive-table ${hive_table_name} \
--m 1 \
--fields-terminated-by '\001' \
--null-string '\\N' \
--null-non-string '\\N' \
--hive-drop-import-delims \
--incremental append \
--where instrno != 0 \
--check-column ${colum_name} \
--last-value ${last_value}
注意:
1) 如果前面没有配置共享metastore(即”sqoop.metastore.server.location" 、”sqoop.metastore.server.port“、”sqoop.metastore.client.autoconnect.url“三个属性在配置文件中已经注释了),那就需要将上面的脚本中 ”--meta-connect jdbc:hsqldb:hsql://hostIP:16000/sqoop“ 去掉。
2) "--create JOBNAME -- import"中”--“后面加一个空格再写import命令,否则执行出错
3) --check-column列不能是char varchar等,可以是date,int,
step 2 执行sqoop job看是否可以顺利进行
sqoop job --list
sqoop job --delete job名称
sqoop job --exec JOBNAME
step 3 确定sqoop job可以正常执行后,编写脚本定时执行
将下面的脚本写入一个文本文件,如 execJob,然后执行 chmod u+x execJob 命令添加可执行权限
source /etc/profile
rm TABLENAME.
java -f sqoop
job -exec JOBNAME
通过where 子句进行导入
sqoop import \
--connect jdbc:mysql://109.123.121.104:3306/testdb \
--username root \
--password 123456 \
--table user \
--where 'id > 5 and account like "f%"' \
--target-dir /sqoop/import/user_where \
--delete-target-dir \
--fields-terminated-by '\t' \
-m 1 \
--direct
table_name='WORK_DEVSTATETIME'
work_date='2018-05-14'
hive_database='test'
sqoop import --connect jdbc:oracle:thin:@10.60.127.64:1521:ORCL \
--username hhggk \
--password oracle \
--table ${table_name} \
--where "workdate= '${work_date}'" \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--delete-target-dir \
--hive-import \
--hive-database ${hive_database} \
--hive-overwrite \
--null-string '\\N' \
--null-non-string '\\N' \
-m 1 \
--direct \
--hive-drop-import-delims
这里 --direct 和 --hive-drop-import-delims参数不能同时出现,前一个参数可以增加导入的速度,后一个参数可以解决我们表中
有空格的问题,导致导入hive中行数增多
import 可能会用到的参数:
| Argument | Described |
|---|---|
| --append | Append data to an existing dataset in HDFS |
| --as-sequencefile | import序列化的文件 |
| --as-textfile | import plain文件 ,默认 |
| --columns |
指定列import,逗号分隔,比如:--columns "id,name" |
| --delete-target-dir | 删除存在的import目标目录 |
| --direct | 直连模式,速度更快(HBase不支持) |
| --fetch-size |
一次从数据库读取 n 个实例,即n条数据 |
| -m,--num-mappers |
建立 n 个并发执行task import |
| -e,--query |
构建表达式 |
| --split-by |
根据column分隔实例 |
| --autoreset-to-one-mappe | 如果没有主键和split-by 用one mapper import (split-by 和此选项不共存) |
| --table |
指定表名import |
| --target-dir |
HDFS destination dir |
| --warehouse-dir |
HDFS parent for table destination |
| --where |
指定where从句,如果有双引号,注意转义 \$CONDITIONS,不能用or,子查询,join |
| -z,--compress | 开启压缩 |
| --null-string |
string列为空指定为此值 |
| --null-non-string |
非string列为空指定为此值,-null这两个参数are optional, 如果不设置,会指定为"null" |
数据导入Hive
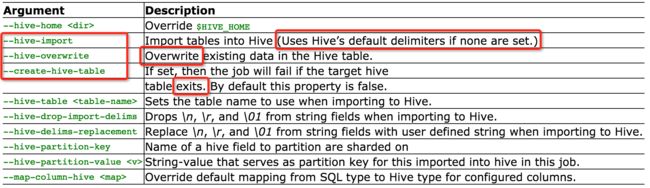
一些分库分表数据接入拉取使用union all优化
myTempSql="select ID,LASTUPDATE from mytbl"${k}"_test.mytbl_0 union all select ID,LASTUPDATE from mytbl"${k}"_test.mytbl_1 union all select ID,LASTUPDATE from mytbl"${k}"_test.mytbl_2 where \$CONDITIONS"
sqoop import --connect $connector --null-string '\\N' --null-non-string '\\N' --query "${myTempSql}" --fields-terminated-by '\001' --lines-terminated-by '\n' -m 1 --hive-drop-import-delims --compression-codec "com.hadoop.compression.lzo.LzopCodec" --target-dir $path
zerodatetimebehavior=converttonull配置的含义,传入的时间格式不对的话可以转化为null
https://blog.csdn.net/sinat_30397435/article/details/72518215