JDK 1.8 流式编程在数据处理方面的应用
文章目录
- 一、Lambda表达式
- 1.1、基本使用
- 1.2、实现原理
- 二、Stream流式编程
- 2.1、Stream API 和 Lambda Expression实现遍历的Demo
- 2.2、Stream常用方法
- 2.2.1、 of(T... values)
- 2.2.2、filter(Predicate predicate)
- 2.2.3、 forEach(Consumer action)
- 2.2.4、map(Function mapper)
- 三、使用Stream和Lambda表达式进行数据处理
- 3.1、基本应用
- 3.2、基本原理
Stream流式编程在JDK 1.8版本中与Lambda表达式一起推出,这一特性标志着JDK 1.8成为Java历史上的又一里程碑。之前在公司接手的关于数据分析及展示需求中就会频繁地使用到Stream流式编程。今天来看一看Stream流式编程在数据分析方面的应用及原理,并且这里会再次带大家回顾一下Lambda表达式的使用。
一、Lambda表达式
之前写过关于JDK函数式编程的文章,可以先进行了解:
https://blog.csdn.net/pbrlovejava/article/details/85226974
1.1、基本使用
在介绍Stream流式编程之前,需要先了解Lambda表达式的使用及基本原理。
一般使用Lambda表达式的场景是优化匿名内部类的繁琐声明,以达到简化代码的效果,譬如在JDK 1.7版本,我们需要声明一个线程(Thread)并且包含一个匿名任务(Runnable)时,我们会这样做:
- JDK 1.7版本
public static void main(String[] args) {
Runnable task = new Runnable() {
@Override
public void run() {
// 具体的任务执行内容
}
};
Thread thread = new Thread(task);
thread.start();
}
这里的task的本质是一个实现了Runnable接口的匿名内部类,最后在new Thread(task)时将其传入构造方法中,以创建一个线程来执行这段任务。
当然,我们还可以进一步进行简化:
- JDK 1.7版本(简化)
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// 具体的任务执行内容
}
});
thread.start();
}
我们可以直接在创建Thread时,直接在构造函数中传入new Runnable并重写run方法,实现具体的任务执行内容。
此时,若没有Idea的帮助,写出这段代码你至少需要记得:
- Thread类构造方法可传入类型
- 传入类型需要重写的方法
但是这种写法很麻烦,我们明明知道这样写不过是为了符合当初的构造定义,但是确实有些脱裤子放屁的意思,此时,Lambda表达式的出现解决了这一问题:
我们只需要记住匿名内部类需要被重写的方法参数及返回值,剩下的,交给Lambda就好了!
- JDK 1.8(Lambda)
public static void main(String[] args) {
Thread thread = new Thread(()->{
// 具体的任务执行内容
});
thread.start();
}
多么地简单明了?现在代码看起来变得更易于阅读了。下面再举几个例子来看看:
- 实现大顶堆(JDK 1.7)
public static void main(String[] args) {
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer x, Integer y) {
return y - x;
}
});
}
- 实现大顶堆(JDK 1.8 Lambda)
public static void main(String[] args) {
PriorityQueue<Integer> maxHeap = new PriorityQueue<>((x, y) -> y - x);
}
是不是可以很明显地看出差距了呢,使用Lambda表达式只需要一行就可以声明一个大顶堆,而不需要手动创建比较器、重写比较器方法这两个步骤。
最后需要注意的是:在使用Lambda表达式去代替匿名接口重写方法时,这个接口有且只有唯一的一个抽象方法,不然Lambda表达式无法判断需要重写哪个方法。
1.2、实现原理
看完了基本使用后,现在来了解一下Lambda表达式的实现原理。
还是上面那段代码,Debug可以发现:
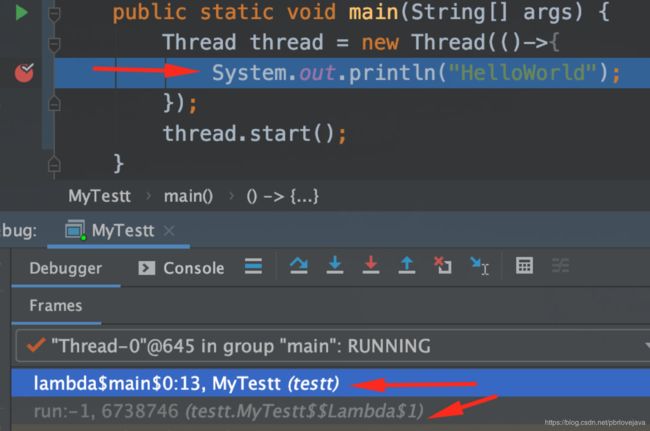
当执行到Lambda表达式的时候,其实是通过字节码技术与反射技术,生成了相应的匿名内部类实现。(因为是在内存中生成,所以只能通过Idea查看运行时状态)
所以使用Lambda表达式时,相较于普通的匿名内部类方式会产生额外的字节码生成及反射带来的效率损失,但是只要不是特别频繁地、多地的使用,一般察觉不到。
更深入地了解请阅读:
https://cloud.tencent.com/developer/article/1328370
二、Stream流式编程
Stream流式编程的使用依赖于Lambda表达式,是JDK 1.8的一大特点所在。使用Stream流式编程可以很方便和灵活地处理数据,而不需要通过数据库去做额外的处理,所以被广泛地应用在数据处理相关程序中。
2.1、Stream API 和 Lambda Expression实现遍历的Demo
现在假设我们需要获取List< String >中首字母为a的数据,可以有以下两种写法,我们可以发现使用流式编程和Lambda表达式后会更加地凝练:
获取流-过滤流-遍历流。
String[] arrays = {"a1","a2","b","c"};
//将arrays转化为List2.2、Stream常用方法
Stream是在Java 8之后更新的一种流,它不同于io流中的InputStream、OutputStream等,准确地说,这个位于java.util下的Stream和io中的流毫无关系。这里的Stream是数据流和对象流。
2.2.1、 of(T… values)
要把List、Set转化为数据流可以使用xxxList.stream()或者使用Stream.of(T…values),T…values代表着数组或者是不定数量的数据,它们会按顺序转换成数据流。
- 获得Stream的三种方式
//1
Stream<String> stringStream1 = Stream.of(new String[]{"a","b","c"});
//2
Stream<String> stringStream2 = Stream.of("a","b","c");
//3
Stream<String> stringStream3 = stringList.stream();
2.2.2、filter(Predicate predicate)
filter用以将流按需过滤成新的流,需要传入的参数为一个位于java.util.function下的Predicate接口并重写test方法去进行校验:
Stream newStream = stringList.stream().filter(new Predicate() {
@Override
public boolean test(Object s) {
if (s.toString().charAt(0) == 'a') {
return true;
}
return false;
}
});
利用Lambda表达式,我们可以将上述代码简化为:
Stream newStream = stringList.stream().filter(s->s.charAt(0) == 'a');
2.2.3、 forEach(Consumer action)
对此流的每一个元素进行操作,需要传入的参数为Consumer接口并且实现其accept方法:
stringStream.forEach(new Consumer(){
@Override
public void accept(Object s) {
System.out.println(s);
}
});
结合Lambda表达式:
stringStream.forEach(s->System.out.println(s));
2.2.4、map(Function mapper)
map方法的作用是对Stream进行处理并且返回一个其他对象充当原Stream。
- 将数据转换为大写
String[] arrays = {"a1","a2","b","c"};
//将arrays转化为List需要说明的是,map方法需要传入的参数是一个函数式方法,可以使用lambda表达式也可直接使用双冒号表达式(现在可以将双冒号表达式::理解为对象通过::调用方法并且传入当前的数据作为参数);而collect方法则是将经过map处理的流“收集”起来形成新的流,传递参数Collectors.toList()表示以List的形式转化流。
- 删除末尾的数字
List<String> collect1 = Stream.of(arrays)
.filter(v -> v != null)
.map(v -> {
if (v.length() == 2) {
//删除尾部
v = v.substring(0, v.length()-1);
}
//返回最终结果
return v;
})
.collect(Collectors.toList());
System.out.println(collect1);
- 将Person对象转化为Student对象
class Person implements Serializable {
//编号
private int id;
//姓名
private String name;
//年龄
private int age;
//getter setter...
}
class Student implements Serializable {
//学号
private int schoolId;
//姓名
private String name;
//年龄
private int age;
//getter setter...
}
public static void main(String[] args) {
List<Person> personList = Arrays.asList(new Person(1, "lily", 18)
, new Person(2, "arong", 19)
, new Person(3, "joke", 20));
//将PersonList转化为Studentlist
List<Student> studentList = personList.stream().map(p -> {
Student student = new Student();
student.setSchoolId(3111000 + p.getId());
student.setName(p.getName());
student.setAge(p.getAge());
//将转化好的student作为结果返回
return student;
}).collect(Collectors.toList());
System.out.println(studentList.toString());
}
}
三、使用Stream和Lambda表达式进行数据处理
3.1、基本应用
现在来看看Stream流式编程在数据处理方面的一些优势。
假设有这么一个需求,前端需要获取到后端这边提供的基础监控数据用以展示,基础监控数据和MySQL交互的VO已经封装成如下:
- BasicDataVO
/**
* @Auther: ARong
* @Date: 2020/7/9 5:59 下午
* @Description: 基础数据VO
*/
public class BasicDataVO {
private String name; // 数据名称
private String type; // 数据类别
private int count; // 数据数量
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public String toString() {
return "BasicDataVO{" +
"name='" + name + '\'' +
", type='" + type + '\'' +
", count=" + count +
'}';
}
}
现在需要在一个页面中展示如下数据表格:
- 数量前三的基础数据(根据数量排序)
- 类别为"国内"的基础数据(根据数量排序)
- 将类别"海外"的基础数据中的数量进行精度修正并和全量数据一起返回(根据数量进行排序)
如果按正常的编程逻辑,这3个需求需要查询3次数据库,跑3个不同的SQL以组合成所需的数据集:
- BasicDataController
@Controller
public class BasicDataController {
@RequestMapping("/getBasicData")
public Map<String, List<BasicDataVO>> getBasicData() {
HashMap<String, List<BasicDataVO>> res = new HashMap<String, List<BasicDataVO>>();
// 数量前三的基础数据(根据数量排序)
List<BasicDataVO> dataList1 = queryLimit3OrderByCount();
// 类别为"国内"的基础数据(根据数量排序)
List<BasicDataVO> dataList2 = queryType1OrderByCount();
// 将类别"海外"的基础数据中的数量进行精度修正并和全量数据一起返回(根据数量进行排序)
List<BasicDataVO> dataList3 = queryType2AndFixDataOrderByCount();
// 数据封装
res.put("list1", dataList1);
res.put("list2", dataList2);
res.put("list3", dataList3);
return res;
}
}
当然这是没有问题的,但是为了3份区别不大的数据进行了3次MySQL连接和查询,这其实是比较浪费资源的,所以另外的方案就是先查询出通用数据,然后在通用数据的基础上使用Steam流式编程与Lambda表达式获取到所需的定制化数据:
- BasicDataController
@Controller
public class BasicDataController {
@RequestMapping("/getBasicData")
public Map<String, List<BasicDataVO>> getBasicData() {
HashMap<String, List<BasicDataVO>> res = new HashMap<String, List<BasicDataVO>>();
// 获取通用数据
List<BasicDataVO> dataList = queryBasicData();
// 数量前三的基础数据(根据数量排序)
List<BasicDataVO> dataList1 = dataList.stream()
.sorted((x, y) -> x.getCount() - y.getCount())
.limit(3)
.collect(Collectors.toList());
// 类别为"国内"的基础数据(根据数量排序)
List<BasicDataVO> dataList2 = dataList.stream()
.filter(x -> "国内服务器".equals(x.getType()))
.sorted((x, y) -> x.getCount() - y.getCount())
.collect(Collectors.toList());
// 将类别"海外"的基础数据中的数量进行精度修正并和全量数据一起返回(根据数量进行排序)
// 此处存在浅拷贝问题
List<BasicDataVO> dataList3 = dataList.stream().map(x -> {
x.setCount(fixData(x.getName()));
return x;
})
.sorted((x, y) -> x.getCount() - y.getCount())
.collect(Collectors.toList());
// 数据封装
res.put("list1", dataList1);
res.put("list2", dataList2);
res.put("list3", dataList3);
return res;
}
}
3.2、基本原理
Stream流的原理和实现是很复杂的,这里只是作为简单学习和了解,需要深入了解请点击这篇文章,讲的很好:
https://www.cnblogs.com/CarpenterLee/p/6637118.html
当使用list.stream()的时候,会返回一个Stream对象,这是因为在JDK 1.8中,开发者们修改了Collection,即集合框架的顶层接口,并在里头新增了一个钩子方法:
- Collection
public interface Collection<E> extends Iterable<E> {
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
}
这个钩子方法就是stream(),然后通过StreamSupport这个类获取到相应的流对象。
- StreamSupport
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
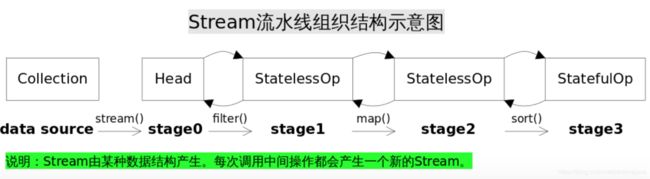
可以看到,StreamSupport会新创建一个ReferencePipeline.Head这个类,看到Head会不会有些眼熟?是的,整个Stream是通过一个双向链表组织起来的,每一个阶段会对应着一个Stream: