差一点就错过跟大佬们交流的机会
文章目录
- 一、Mysql的逻辑分层
- 二、SQL优化
- 1、Insert的优化
- 第一种情况(合并插入)
- 第二种情况(事务手动提交)
- 第三种情况(主键顺序)
- 2、order by的优化
- 环境准备
- 两种排序方式
- 1)filesort排序
- 2)index排序
- Filesort优化
- 三、JOIN的用法
- 四、额外补充能量
- 为什么要优化?
- 哪些方面可以优化?
- 1、优化硬件、操作系统
- 2、优化MySQL服务器
- 最大连接数:
- 指定MySQL可能的连接数量
- 索引块的缓冲区大小
- MySQL执行排序使用的缓冲大小
- MYSQL读入缓冲区大小
- Join操作缓存大小
- MySQL的随机读缓冲区大小
- 缓存排序索引大小
- 缓存空闲的线程以便不被销毁
- 3、优化DB设计
- 建索引的目的
- 1)B-Tree 索引
- 2)Hash 索引
- 3)什么时候可以建索引
- 4)什么时候不可以建索引
- 4、优化架构设计方案
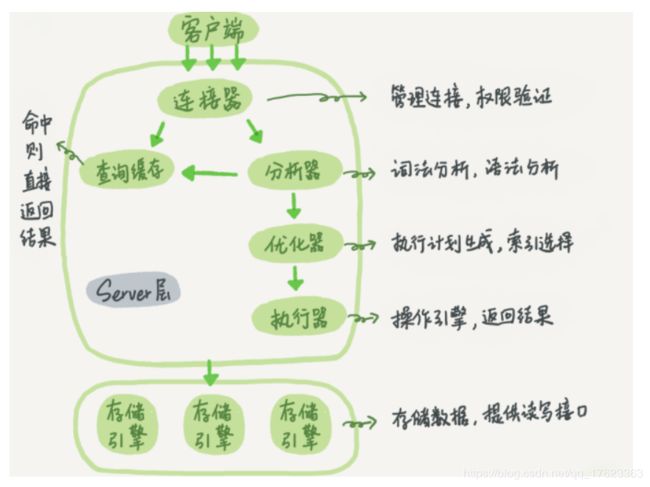
一、Mysql的逻辑分层
Mysql分为:连接层、服务层、引擎层、存储层。
当客户端向服务端发起操作请求的时候,执行过程是这样的:
1、客户端端与Mysql服务端的连接层建立连接,根据请求类型去选择相应的服务层的请求接口。
二、SQL优化
1、Insert的优化
在执行insert操作时经常遇到插入多条数据的时候,例如:
- 管理员在同时添加多名用户的时候
- 在某种数据结构比较复杂的情况下添加数据
在1对n的表结构的情况下,经常会遇到这种插入多次子表的情况。那么程序开发人员在开发时候,首先想到的是利用for循环进行插入子表数据:
第一种情况(合并插入)
例如:我想插入三条,利用for循环在循环3次才能执行,那么就需要这样执行:
insert into st(name,password) values('zhangsan','123456');
insert into st(name,password) values('lisi','123456');
insert into st(name,password) values('wangwu','123456');
怎么才能改进呢?mysql的sql有一个语法可以支持,如下:
insert into st(name,password) values('zhangsan','123456'),('lisi','123456'),('wangwu','123456');
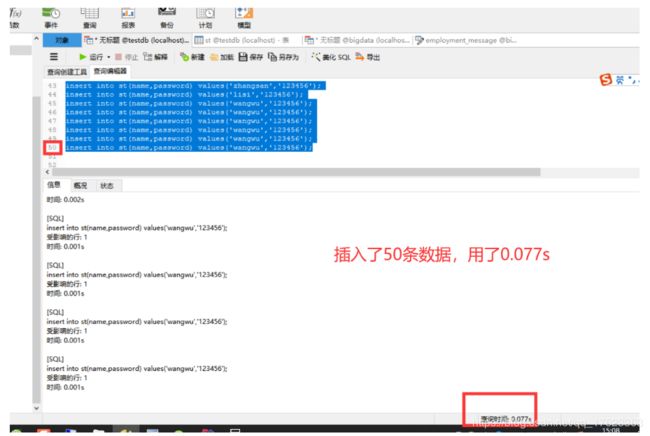
只有三条可能看不出来,那么接下来做一个测试,复制了50次遍。
- 测试结果1:以单个插入的的方式,插入了50条数据,用了0.077s
- 测试结果2:插入了271条数据,用了0.077s
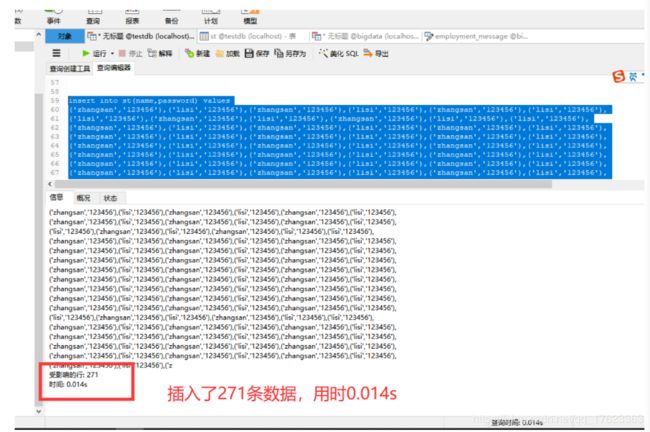
插入3241条用了0.044s
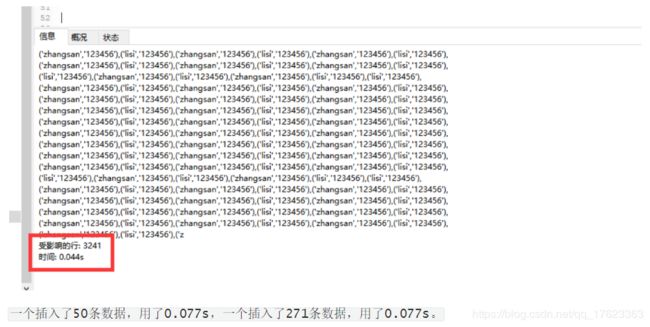
一个插入了50条数据,用了0.077s,一个插入了271条数据,用了0.077s。
很明显的对比。
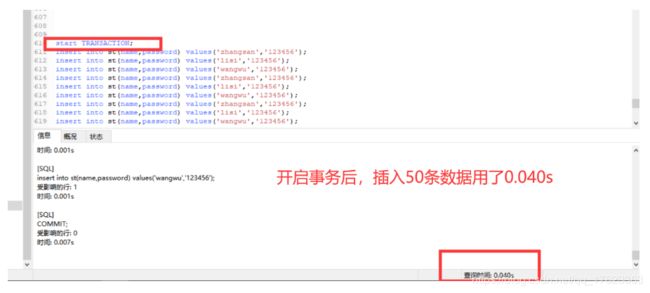
第二种情况(事务手动提交)
开启事务,事务提交,改为手动提交。
start TRANSACTION; #先开启事务
insert into st(name,password) values('zhangsan','123456');
insert into st(name,password) values('lisi','123456');
insert into st(name,password) values('wangwu','123456');
COMMIT; #最后提交
测试结果:开启事务后,插入50条数据用了0.040s,比没开启事务插入数据快了将近一半。
第三种情况(主键顺序)
在插入大批量的数据时,建议归类、有序的插入数据。
st(id key,name)
insert into st(name,id) values('zhangsana',10);
insert into st(name,id) values('lisi',3);
insert into st(name,id) values('wangwu',2);
insert into st(name,id) values('wangwub',8);
insert into st(name,id) values('wangwua',34);
优化后:(进行排序,按主键的顺序)
insert into st(name,id) values(2,'wangwu');
insert into st(name,id) values(3,'lisi');
insert into st(name,id) values(8,'wangwub');
insert into st(name,id) values(10,'zhangsana');
insert into st(name,id) values(34,'wangwua');
2、order by的优化
环境准备
-
准备测试表
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `password` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `age` varchar(20) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `sex` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `email` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=23 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; -
准备测试数据
INSERT INTO `user` VALUES ('1', 'zhangsan', 'zhangsan123', '30', '男', '[email protected]'); INSERT INTO `user` VALUES ('2', 'lisi', 'lisi', '21', '男', '[email protected]'); INSERT INTO `user` VALUES ('3', 'wangwu', 'wangwu', '34', '男', '[email protected]'); INSERT INTO `user` VALUES ('4', 'zhaoqi', 'zhaoqi', '32', '男', '[email protected]'); INSERT INTO `user` VALUES ('5', 'wuliu', 'wuliu', '33', '男', '[email protected]'); INSERT INTO `user` VALUES ('6', 'xiaoming', 'xiaoming', '51', '男', '[email protected]'); INSERT INTO `user` VALUES ('7', 'xiaozhang', 'xiaozhang', '23', '男', '[email protected]'); INSERT INTO `user` VALUES ('8', 'xiaoli', 'xiaoli', '30', '男', '[email protected]'); INSERT INTO `user` VALUES ('9', 'xiaozheng', 'xiaozheng', '13', '男', '[email protected]'); INSERT INTO `user` VALUES ('10', 'xiaohua', 'xiaohua', '54', '男', '[email protected]'); INSERT INTO `user` VALUES ('11', 'xiaozeng', 'xiaozeng', '66', '男', '[email protected]'); INSERT INTO `user` VALUES ('12', 'xiaozhao', 'xiaozhao', '12', '男', '[email protected]'); INSERT INTO `user` VALUES ('13', 'xiaoa', 'xiaoa', '32', '男', '[email protected]'); INSERT INTO `user` VALUES ('14', 'xiaob', 'xiaob', '13', '男', '[email protected]'); INSERT INTO `user` VALUES ('15', 'xiaoc', 'xiaoc', '32', '男', '[email protected]'); INSERT INTO `user` VALUES ('16', 'xiaod', 'xiaod', '43', '男', '[email protected]'); INSERT INTO `user` VALUES ('17', 'xiaoe', 'xiaoe', '23', '男', '[email protected]'); INSERT INTO `user` VALUES ('18', 'xiaof', 'xiaof', '65', '男', '[email protected]'); INSERT INTO `user` VALUES ('19', 'xiaog', 'xiaog', '30', '男', '[email protected]'); INSERT INTO `user` VALUES ('20', 'xiaoe', 'xiaoe', '30', '男', '[email protected]'); -
建立索引
#给id与age建立索引
create index index_user_salary_age on user(age,salary);
#查询表的索引
show index from testdb.user;
两种排序方式
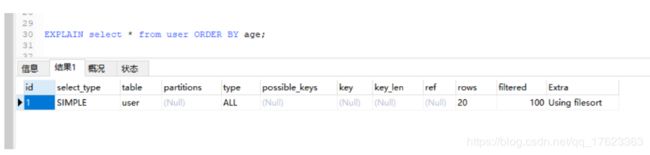
1)filesort排序
EXPLAIN select * from user ORDER BY age;
- 多字段排序

- 多字段升序或者降序,都是走的全表扫描
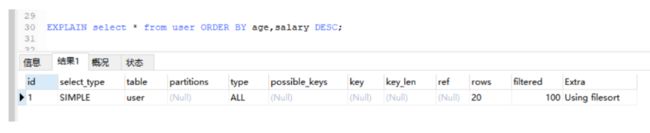
可以从上面的例子中看出,都是Using filesort,全部走了全表扫描
效率是比较低的。
2)index排序
通过using index排序
#在查询的时候,只把加了索引的给查出来
EXPLAIN select id,age,salary from user ORDER BY age DESC,salary DESC;
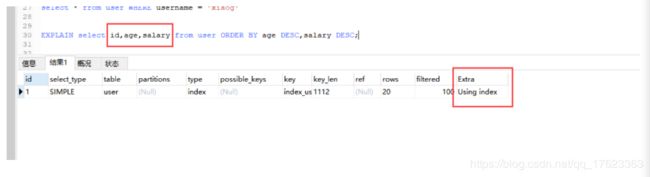
- 如果想要其他字段也想走index排序的话,也需要给这个字段加上索引
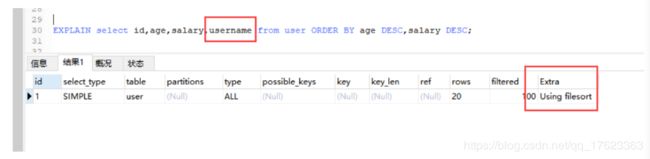
- 给username加索引
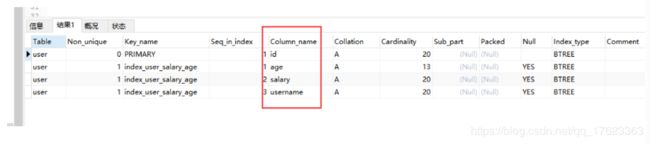
- 给username加索引后
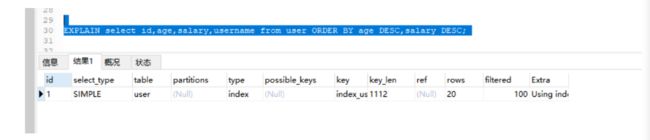
3)多字段排序
-
一个升序一个降序
EXPLAIN select id,age,salary,username from user ORDER BY age asc,salary DESC;
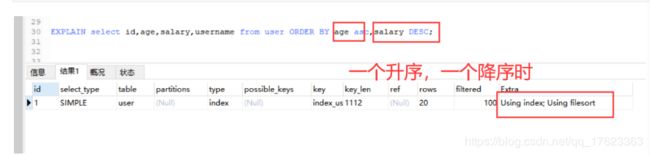
总结:最好不要既有升序也有降序,效率会降低。
- 颠倒排序的位置
如果位置有变化了,也会影响效率。排序的位置,最好和索引的顺序符合。
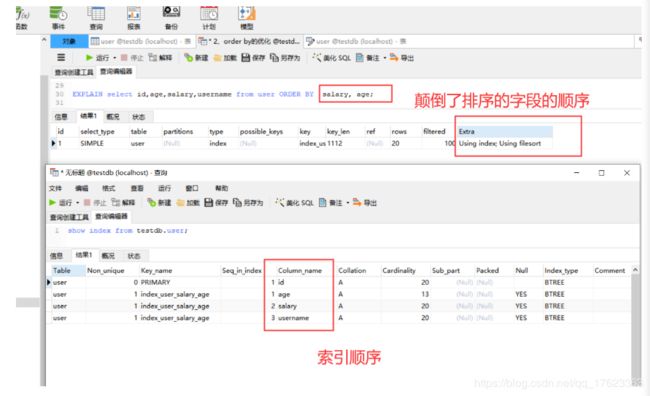
在优化排序的相关sql时,尽量减少额外的字段排序,通过索引直接返回有序的数据。where条件和Order by 使用相同的索引并且Order By的顺序和索引顺序相同,并且Order by 的字段都是升序或者都是降序。
Filesort优化
1)两次扫描算法
在MySQL4.1之前,使用该方式排序。首先根据条件取出排序字段和行指针信息,然后在排序区sort buffer中排序,如果sort buffer不够则在临时表temporary table中存储排序结果。完成排序之后,再根据行指针回表读取记录,该操作可能会导致大量随机I/O操作。
2)一次扫描算法
一次性取出满足条件的所有字段,然后在排序区sort buffer中排序后直接输出结果集。排序时内存开销较大,但是排序效率比两次扫描算法高的多。
MySQL通过比较系统变量max_length_for_sort_data的大小和Qury语句取出的字段总大小,来判定是否符合哪种排序算法,如果max_length_for_sort_data更大,则使用第二种优化之后
三、JOIN的用法
直接用代码表示的话,不能很直观的看到效果,为了方便,我使用图片+SQL的形式来讲解。
在实际的数据库应用中,我们经常需要从多个数据表中读取数据,这时我们就可以使用SQL语句中的连接(JOIN),在两个或多个数据表中查询数据。
JOIN 按照功能可分为如下三类:
-
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录;
-
LEFT JOIN(左连接):获取左表中的所有记录,即使在右表没有对应匹配的记录;
-
RIGHT JOIN(右连接):与 LEFT JOIN 相反,用于获取右表中的所有记录,即使左表没有对应匹配的记录。
有以下几个表:
学生表(students):student_id,student_name,sno,class_id; 学号,姓名,学号,班级号
班级表(classes):student_id,class_name,class_id; 学号,姓名,班级
学生表
| student_id | student_name | sno | class_id |
|---|---|---|---|
| 1 | 张三 | 201701 | 1701 |
| 2 | 李四 | 201701 | 1701 |
| 3 | 王五 | 201702 | 1702 |
学生表
| student_id | class_name | class_id |
|---|---|---|
| 201701 | 网络171C | 1701 |
| 201702 | 网络171C | 1701 |
| 201703 | 网络172 | 1702 |
四、额外补充能量
-
利用存储过程大批量插入数据
1、创建存储过程
DELIMITER inData
CREATE PROCEDURE insertData()
BEGIN
SET @i=1;
WHILE @i<=10000 DO
INSERT INTO st(name) VALUES(CONCAT("user",@i)); #拼接USER 和i值
SET @i=@i+1; #防止成为死循环
END WHILE; #结束循环
END inData #结束自定义结束符
DELIMITER ;
2、查询存储过程
show create PROCEDURE insertData ;\G
3、使用存储过程
CALL insertData()
为什么要优化?
随着数据量的增大, mysql服务性能差从而直接影响用户体验。
查询时结果显示的很慢等。
哪些方面可以优化?
1、优化硬件、操作系统
2、优化MySQL服务器
3、优化DB设计
4、优化SQL语句
5、优化应用
1、优化硬件、操作系统
-CPU,内存,硬盘
Linux操作系统的内核优化
内核相关参数(/etc/sysctl.conf)
-网络TCP连接
-加快资源回收效率
-增加资源限制
-改变磁盘调度策略
参考链接: https://www.cnblogs.com/only-me/p/11531289.html
2、优化MySQL服务器
最大连接数:
max_connections=2000
默认:max_connections=151
指定MySQL可能的连接数量
#指定MySQL可能的连接数量。当MySQL主线程在很短的时间内得到非常多的连接请求,该参数就起作用,之后主线程花些时间(尽管很短)检查连接并且启动一个新线程。
#back_log参数的值指出在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中。
back_log=1024
默认:back_log=80
索引块的缓冲区大小
key_buffer_size = 32M
#索引块的缓冲区大小,对MyISAM表性能影响最大的一个参数.决定索引处理的速度,尤其是索引读的速度。默认值是8M,通过检查状态值Key_read_requests
#和Key_reads,可以知道key_buffer_size设置是否合理
默认:key_buffer_size=8M
MySQL执行排序使用的缓冲大小
sort_buffer_size = 16M
#是MySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。
#如果不能,可以尝试增加sort_buffer_size变量的大小。
默认:sort_buffer_size=256K
MYSQL读入缓冲区大小
read_buffer_size = 64M
#是MySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。
#如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能。
默认:read_buffer_size=64K
Join操作缓存大小
join_buffer_size = 16M
#应用程序经常会出现一些两表(或多表)Join的操作需求,MySQL在完成某些 Join 需求的时候(all/index join),为了减少参与Join的“被驱动表”的
#读取次数以提高性能,需要使用到 Join Buffer 来协助完成 Join操作。当 Join Buffer 太小,MySQL 不会将该 Buffer 存入磁盘文件,
#而是先将Join Buffer中的结果集与需要 Join 的表进行 Join 操作,
#然后清空 Join Buffer 中的数据,继续将剩余的结果集写入此 Buffer 中,如此往复。这势必会造成被驱动表需要被多次读取,成倍增加 IO 访问,降低效率。
默认:join_buffer_size=256K
MySQL的随机读缓冲区大小
read_rnd_buffer_size = 32M
#是MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,
#提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
默认:read_rnd_buffer_size=256K
缓存排序索引大小
myisam_sort_buffer_size = 256M
#当对MyISAM表执行repair table或创建索引时,用以缓存排序索引;设置太小时可能会遇到” myisam_sort_buffer_size is too small”
myisam_sort_buffer_size=102M
缓存空闲的线程以便不被销毁
thread_cache_size = 384
#thread_cahe_size线程池,线程缓存。用来缓存空闲的线程,以至于不被销毁,如果线程缓存在的空闲线程,需要重新建立新连接,
#则会优先调用线程池中的缓存,很快就能响应连接请求。每建立一个连接,都需要一个线程与之匹配。
默认:thread_cache_size=10
set global max_connections=2000;#设置最大连接数
set global key_buffer_size=512*1024*1024;#设置索引块缓冲区大小
set global sort_buffer_size=128*1024*1024;#MySQL执行排序使用的缓冲大小
set global read_buffer_size=64*1024*1024;#MYSQL读入缓冲区大小
set global join_buffer_size=128*1024*1024;#Join操作缓存大小
set global read_rnd_buffer_size=32*1024*1024;#MySQL的随机读缓冲区大小
set global myisam_sort_buffer_size=256*1024*1024;#缓存排序索引大小
set global thread_cache_size=384;#缓存空闲的线程以便不被销毁
set global innodb_buffer_pool_size=1000*1024*1024;#内存
#查询
SHOW GLOBAL VARIABLES LIKE 'innodb_buffer_pool_size'
3、优化DB设计
-参照范式进行设计(1级范式)
1NF
包含分隔符类字符的字符串数据。
名字尾端有数字的属性。
没有定义键或键定义不好的表。
2NF
多个属性有同样的前缀。
重复的数据组。
汇总的数据,所引用的数据在一个完全不同的实体中。
BCNF- “每个键必须唯一标识实体,每个非键熟悉必须描述实体。
4NF
三元关系(实体:实体:实体)。
潜伏的多值属性。(如多个手机号。)
临时数据或历史值。(需要将历史数据的主体提出,否则将存在大量冗余。)
-建立合适的索引
建索引的目的
加快查询速度。
减少I/O操作,通过索引的路径来检索数据,不是在磁盘中随机检索。
消除磁盘排序,索引是排序的,走完索引就排序完成
1)B-Tree 索引
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型
2)Hash 索引
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以Hash索引的查询效率要远高于B-Tree索引。
3)什么时候可以建索引
1)列无重复值,可以建索引:唯一索引和普通索引
2)聚集索引和非聚集索引都可以是唯一的。因此,只要列中的数据是唯一的,就可以在同一个表上创建一个唯一的聚集索引和多个唯一的非聚集索引。
3)建了索引性能得到提高
4)区分度高的列可以建索引,比如表示男和女的列区分度就不高,就不能建索引
4)什么时候不可以建索引
1.频繁更新的字段不适合建立索引
2.where条件中用不到的字段不适合建立索引
3.表数据可以确定比较少的不需要建索引
4.数据重复且发布比较均匀的的字段不适合建索引(唯一性太差的字段不适合建立索引),例如性别,真假值
5.参与列计算的列不适合建索引,如select * from where amount+1>10
6.查询返回的记录数不适合建立索引
7.查询的排序表记录小于40%不适合建立索引
8.查询非排序表的记录小于 7%不适合建立索引
9.表的碎片较多(频繁增加、删除)不适合建立索引
4、优化架构设计方案
-
加缓存
-
DNS轮询
通过在DNS-server上对一个域名设置多个ip解析,来扩充web-server性能及实施负载均衡的技术 。
-
LVS(负载均衡)
Linux Virtual Server,使用集群技术,实现在linux操作系统层面的一个高性能、高可用、负载均衡服务器 。
-
nginx:一个高性能的web-server和实施反向代理的软件
一个高性能的web-server和实施反向代理的软件